BiLSTM算法(一)
原理分析:
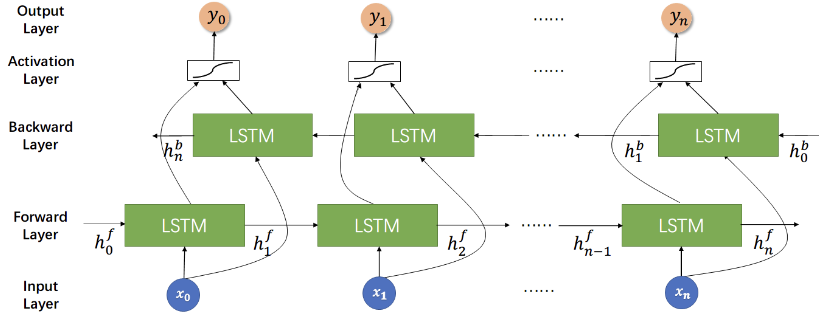
BiLSTM(双向长短期记忆网络) 是一种循环神经网络(RNN)的变体,它在自然语言处理任务中非常有效,其中包括给定一个长句子预测下一个单词。
这种效果的主要原因包括以下几点:
长短期记忆网络(LSTM)结构:LSTM 是一种特殊的 RNN,专门设计用于解决长序列依赖问题。相比于普通的 RNN,LSTM 有能力更好地捕捉长距离的依赖关系,因此适用于处理长句子。
双向性:BiLSTM 通过在输入序列的两个方向上进行处理,即前向和后向,使得模型能够同时捕捉到当前位置前后的上下文信息。这样,模型就能够更全面地理解整个句子的语境,从而更准确地预测下一个单词。
上下文信息:BiLSTM 能够通过记忆单元和门控机制(如输入门、遗忘门、输出门)来记忆并使用之前的输入信息。这使得模型能够在预测下一个单词时考虑到句子中前面的所有单词,而不仅仅是最近的几个单词。
参数共享:由于 LSTM 的参数在整个序列上是共享的,模型能够利用整个序列的信息来进行预测,而不是仅仅依赖于当前时刻的输入。
端到端学习:BiLSTM 可以通过端到端的方式进行训练,这意味着模型可以直接从原始数据中学习输入和输出之间的映射关系,无需手工设计特征或规则。
总的来说,BiLSTM 结合了双向处理、长序列依赖建模和上下文信息的利用,使得它能够在给定一个长句子的情况下有效地预测下一个单词。
代码实现:
BiLSTM的代码相对而言比较难找,很多提供的也不准确。笔者找了几个运行成功的案例,针对案例中的BiLSTM算法部分进行分析。
案例一:给定一个长句子预测下一个单词
原文链接点击此给定一个长句子预测下一个单词
class BiLSTM(nn.Module):
def __init__(self):
super(BiLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=n_class, hidden_size=n_hidden, bidirectional=True)
# fc
self.fc = nn.Linear(n_hidden * 2, n_class)
def forward(self, X):
# X: [batch_size, max_len, n_class]
batch_size = X.shape[0]
input = X.transpose(0, 1) # input : [max_len, batch_size, n_class]
hidden_state = torch.randn(1*2, batch_size, n_hidden) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
cell_state = torch.randn(1*2, batch_size, n_hidden) # [num_layers(=1) * num_directions(=2), batch_size, n_hidden]
outputs, (_, _) = self.lstm(input, (hidden_state, cell_state))
outputs = outputs[-1] # [batch_size, n_hidden * 2]
model = self.fc(outputs) # model : [batch_size, n_class]
return model
model = BiLSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
针对def __init__(self):
这段代码定义了一个名为 BiLSTM 的模型类,它继承自 nn.Module 类。在 __init__ 方法中,首先调用 super(BiLSTM, self).__init__() 来初始化父类 nn.Module,然后创建了一个双向 LSTM 模型 self.lstm。
input_size 参数指定了输入的特征维度,这里设置为 n_class,即输入数据的特征数量。hidden_size 参数指定了 LSTM 隐藏状态的维度,这里设置为 n_hidden,即隐藏层的大小。bidirectional=True 表示这是一个双向 LSTM,即包含前向和后向两个方向的信息。接着创建了一个全连接层 self.fc,其中输入特征数量为 n_hidden * 2,表示双向 LSTM 输出的隐藏状态的维度乘以 2,输出特征数量为 n_class,表示分类的类别数量。
针对def forward(self, X):
这段代码定义了模型的前向传播方法forward。在该方法中,首先接受输入X,其维度为[batch_size,max_len, n_class],其中batch_size表示输入数据的批量大小,max_len表示序列的最大长度,n_class表示输入数据的特征数量。接着通过transpose方法将输入X的维度重新排列,以适应LSTM模型的输入要求,即将序列的维度放在第二维上,结果存储在input中。
然后,创建了LSTM模型所需的初始隐藏状态hidden_state和细胞状态cell_state。这里使用了随机初始化的状态,其维度为[num_layers * num_directions, batch_size, n_hidden],其中num_layers表示 LSTM 的层数,默认为 1,num_directions表示 LSTM 的方向数,默认为 2(双向)。这里的 1*2 表示单层双向 LSTM。
接着,将输入数据input和初始状态传递给 LSTM 模型self.lstm,得到输出outputs。最后,取 LSTM 模型输出的最后一个时间步的隐藏状态作为模型输出,即outputs[-1],其维度为[batch_size, n_hidden * 2],然后通过全连接层self.fc进行分类,得到模型的输出model,其维度为[batch_size, n_class],即表示每个类别的得分。
针对
model = BiLSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
:
这段代码实例化了一个 BiLSTM 模型,并定义了损失函数 CrossEntropyLoss 和优化器 Adam。损失函数用于计算模型输出与目标标签之间的误差,优化器用于更新模型的参数,其中学习率 lr 设置为 0.001。
BiLSTM算法(一)的更多相关文章
- NLP(二十四)利用ALBERT实现命名实体识别
本文将会介绍如何利用ALBERT来实现命名实体识别.如果有对命名实体识别不清楚的读者,请参考笔者的文章NLP入门(四)命名实体识别(NER) . 本文的项目结构如下: 其中,albert_ ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 【算法】BILSTM+CRF中的条件随机场
BILSTM+CRF中的条件随机场 tensorflow中crf关键的两个函数是训练函数tf.contrib.crf.crf_log_likelihood和解码函数tf.contrib.crf.vit ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- PyTorch 高级实战教程:基于 BI-LSTM CRF 实现命名实体识别和中文分词
前言:译者实测 PyTorch 代码非常简洁易懂,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中,相关的代码后续将会分享. 具体的数据格式,这种方式并不适合处理 ...
- Pytorch Bi-LSTM + CRF 代码详解
久闻LSTM + CRF的效果强大,最近在看Pytorch官网文档的时候,看到了这段代码,前前后后查了很多资料,终于把代码弄懂了.我希望在后来人看这段代码的时候,直接就看我的博客就能完全弄懂这段代码. ...
- pytorch BiLSTM+CRF代码详解 重点
一. BILSTM + CRF介绍 https://www.jianshu.com/p/97cb3b6db573 1.介绍 基于神经网络的方法,在命名实体识别任务中非常流行和普遍. 如果你不知道Bi- ...
- 高级教程: 作出动态决策和 Bi-LSTM CRF 重点
动态 VS 静态深度学习工具集 Pytorch 是一个 动态 神经网络工具包. 另一个动态工具包的例子是 Dynet (我之所以提这个是因为使用 Pytorch 和 Dynet 是十分类似的. 如果你 ...
- pytorch实现BiLSTM+CRF用于NER(命名实体识别)
pytorch实现BiLSTM+CRF用于NER(命名实体识别)在写这篇博客之前,我看了网上关于pytorch,BiLstm+CRF的实现,都是一个版本(对pytorch教程的翻译), 翻译得一点质量 ...
- NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型
在文章NLP(二十四)利用ALBERT实现命名实体识别中,笔者介绍了ALBERT+Bi-LSTM模型在命名实体识别方面的应用. 在本文中,笔者将介绍如何实现ALBERT+Bi-LSTM+CRF ...
随机推荐
- 【Azure 应用服务】更新镜像后并重启应用服务,部署日志始终没有出现加载新镜像成功的日志
问题描述 在App Service中部署镜像文件,发现镜像一直没有部署,重启App Service服务也无效果. DockerFile如下: FROM crunchgeek/php-fpm:7.0 # ...
- Java实现书城项目(增删)
书城项目 登录 dao 接口:UserDao Users login(String username,String password); 实现:UserDaoImpl QueryRunner quer ...
- 使用 Docker 部署 MrDoc 在线文档管理系统
1)MrDoc 介绍 MrDoc 简介 MrDoc 觅思文档:https://mrdoc.pro/ MrDoc 使用手册:https://doc.mrdoc.pro/p/user-guide/ MrD ...
- 深入浅出Java多线程(十一):AQS
引言 大家好,我是你们的老伙计秀才!今天带来的是[深入浅出Java多线程]系列的第十一篇内容:AQS(AbstractQueuedSynchronizer).大家觉得有用请点赞,喜欢请关注!秀才在此谢 ...
- 3DCAD图纸转2D(DXF)图纸通用解决方案文稿
本文地址:https://gitee.com/dvaloveu/lovedva/issues/I6B5YC 视频演示(1.25倍速&原速):Acfun Bilibili 脚本地址:https: ...
- k8s创建Pod的流程
Kubernetes(k8s)中Pod的创建过程是一个涉及多个组件协作的复杂流程,下面将详细描述这个过程,确保内容的详尽性和深度. 一.用户提交创建请求 Pod的创建始于用户通过kubectl命令行工 ...
- 基于六轴传感器MPU6050的加速度和角度值读取
一 系统简介 1.简介 MPU-60x0 是全球首例 9 轴运动处理传感器.它集成了 3 轴MEMS陀螺仪,3 轴MEMS加速度计,以及一个可扩展的数字运动处理器 DMP(Digital Motion ...
- Docker部署nginx配置SSL多目录
对自己第一次搭建nginx做个简要的笔记 第一步:创建宿主机挂载点目录 mkdir -p /home/nginx/{conf,conf.d,html,log,ssl} 第二步:安装简易版nginx,复 ...
- day32-JQuery05
jQuery05 9.作业 9.1homework01 对多选框进行操作,输出选中的多选框的个数,并且把选中爱好的名称显示. <!DOCTYPE html> <html lang=& ...
- 【C语言复习笔记】一些要点
[C语言复习笔记]一些要点 按学校教材复习的,整理的是我不熟悉的地方 最近C用的好少,快忘完了就赶紧整理一下(Python真好玩) 第一章 初识C语言 存储器 内存容量的大小,取决于地址总线的数量 \ ...