使用scikit-learn构建模型
sklearn中还存在许多不同的机器学习模型可以直接调用,相比于自己撰写代码,直接使用sklearn的模型可以大大提高效率。
sklearn中所有的模型都有四个固定且常用的方法,分别是model.fit、model.predict、model.get_params、model.score。
1.数据导入
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
data=load_boston()
2.数据预处理
data.keys()
Out[ ]:
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename', 'data_module'])
In [ ]:
data['data']
Out[ ]:
array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9690e+02,
9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9283e+02,
4.0300e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
5.6400e+00],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9345e+02,
6.4800e+00],
[4.7410e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
7.8800e+00]])
In [ ]:
#将data['data']和data['target']两类数据都切割为两份,test_size=0.2
train_data,test_data,train_target,test_target=train_test_split(data['data'],data['target'],test_size=0.2)
print(train_data.shape)
print(test_data.shape)
print(train_target.shape)
print(test_target.shape)
(404, 13)
(102, 13)
(404,)
(102,)
3.构建离差标准化模型
#构建离差标准化模型
model=MinMaxScaler().fit(train_data)
In [ ]:
model.transform(train_data)
Out[ ]:
array([[6.17624751e-04, 4.00000000e-01, 2.18108504e-01, ...,
5.31914894e-01, 9.91252092e-01, 6.70529801e-02],
[9.15525569e-02, 0.00000000e+00, 6.46627566e-01, ...,
8.08510638e-01, 1.00000000e+00, 5.27593819e-01],
[1.85321145e-03, 0.00000000e+00, 2.96920821e-01, ...,
8.82978723e-01, 9.96881181e-01, 4.67163355e-01],
...,
[2.70765792e-04, 0.00000000e+00, 1.73387097e-01, ...,
8.08510638e-01, 9.94700543e-01, 2.43653422e-01],
[6.04923824e-03, 0.00000000e+00, 7.85557185e-01, ...,
9.14893617e-01, 1.00000000e+00, 4.61644592e-01],
[3.85613648e-03, 0.00000000e+00, 3.46041056e-01, ...,
6.17021277e-01, 9.98326487e-01, 2.27373068e-01]])
In [ ]:
train_data_mms=model.transform(train_data)
In [ ]:
model.transform(test_data)
Out[ ]:
array([[1.10386796e-02, 0.00000000e+00, 2.81524927e-01, ...,
8.93617021e-01, 9.94015924e-01, 5.00827815e-01],
[4.82624007e-03, 0.00000000e+00, 3.71334311e-01, ...,
6.38297872e-01, 1.00000000e+00, 5.89403974e-01],
[2.76127157e-03, 0.00000000e+00, 3.71334311e-01, ...,
6.38297872e-01, 9.81058877e-01, 4.50607064e-01],
...,
[3.27751369e-04, 8.00000000e-01, 1.16568915e-01, ...,
4.04255319e-01, 9.95638724e-01, 2.07505519e-01],
[8.61718595e-03, 0.00000000e+00, 2.81524927e-01, ...,
8.93617021e-01, 9.77280795e-01, 3.05463576e-01],
[2.65516824e-02, 0.00000000e+00, 7.00879765e-01, ...,
2.23404255e-01, 9.86840103e-01, 7.67108168e-01]])
In [ ]:
test_data_mms=model.transform(test_data)
In [ ]:
#利用PCA进行降维
model=PCA(n_components=8).fit(train_data_mms)
In [ ]:
model.transform(train_data_mms).shape
Out[ ]:
(404, 8)
In [ ]:
train_data_mms=model.transform(train_data_mms)
In [ ]:
model.transform(test_data_mms).shape
Out[ ]:
(102, 8)
In [ ]:
test_data_mms=model.transform(test_data_mms)
4.聚类分析
#使用sklearn估计器进行聚类分析
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
data=load_iris()
#使用KMeans聚类模型将数据data['data']数据分为三类
KMeans(n_clusters=3).fit(data['data'])
Out[ ]:
KMeans
KMeans(n_clusters=3)
In [ ]:
model=KMeans(n_clusters=3).fit(data['data'])
#可以查看聚类标签
model.labels_
Out[ ]:
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 2, 0, 0, 0, 0, 2, 0, 0, 0,
0, 0, 0, 2, 2, 0, 0, 0, 0, 2, 0, 2, 0, 2, 0, 0, 2, 2, 0, 0, 0, 0,
0, 2, 0, 0, 0, 0, 2, 0, 0, 0, 2, 0, 0, 0, 2, 0, 0, 2])
In [ ]:
#可以查看聚类中心
model.cluster_centers_
Out[ ]:
array([[6.85 , 3.07368421, 5.74210526, 2.07105263],
[5.006 , 3.428 , 1.462 , 0.246 ],
[5.9016129 , 2.7483871 , 4.39354839, 1.43387097]])
In [ ]:
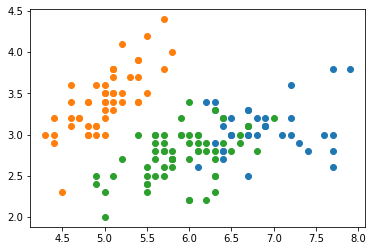
#通过可视化查看聚类效果
import matplotlib.pyplot as plt
for i in range(3):
plt.scatter(data['data'][model.labels_==i,0],data['data'][model.labels_==i,1])
plt.show()
In [ ]:
#聚类模型评价
from sklearn.metrics import silhouette_score
silhouette_score(data['data'],model.labels_)
#分析聚为几类比较好
for k in range(2,9):
model=KMeans(n_clusters=k).fit(data['data'])
print(k,silhouette_score(data['data'],model.labels_))
2 0.6810461692117462
3 0.5528190123564095
4 0.49805050499728737
5 0.48874888709310566
6 0.36483400396700255
7 0.348950840496829
8 0.3617900335973811
5.分类模型
#使用sklearn估计器进行分类分析
#导入数据
from sklearn.datasets import load_breast_cancer
data=load_breast_cancer()
#获取数据
x=data['data']
#是否是乳腺癌
y=data['target']
In [ ]:
#划分训练集,测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
#模型预处理
x_train.shape
Out[ ]:
(455, 30)
In [ ]:
#查看每一列的最大值
import numpy as np
#将科学计数法转为数值
np.int32(x_train.max(axis=0))
Out[ ]:
array([ 28, 39, 188, 2501, 0, 0, 0, 0, 0, 0, 2,
4, 21, 542, 0, 0, 0, 0, 0, 0, 36, 49,
251, 4254, 0, 0, 1, 0, 0, 0])
In [ ]:
#对数据进行标准化离散标准化处理
from sklearn.preprocessing import StandardScaler
model=StandardScaler().fit(x_train)
x_train_ss=model.transform(x_train)
x_test_ss=model.transform(x_test)
In [ ]:
#检验标准化后的最大值结果
x_train_ss.max(axis=0)
#分类模型构建
from sklearn.svm import SVC
#构建SVC模型
model=SVC().fit(x_train_ss,y_train)
#对模型进行预测,并输出预测结果
model.predict(x_test_ss)
Out[ ]:
array([1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1,
1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0,
1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1,
1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1,
1, 0, 1, 0])
In [ ]:
#再看和真实值对比,看泛化能力
y_test
Out[ ]:
array([1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1,
1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0,
1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1,
1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1,
1, 0, 1, 0])
In [ ]:
#直接计算真实值与训练值的准确率
y_pre=model.predict(x_test_ss)
model.score(x_test_ss,y_test)
Out[ ]:
1.0
In [ ]:
#分类模型的评价指标
from sklearn.metrics import recall_score,precision_score,f1_score,roc_curve
#召回率
print(recall_score(y_test,y_pre))
#准确率
print(precision_score(y_test,y_pre))
#综合衡量召回率和准确率
print(f1_score(y_test,y_pre))
1.0
1.0
1.0
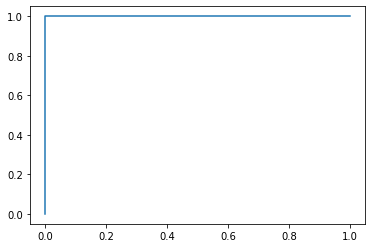
In [ ]:
fpr,tpr,thresholds=roc_curve(y_test,y_pre)
import matplotlib.pyplot as plt
plt.plot(fpr,tpr)
plt.show()
6.回归模型
#使用sklearn估计器构建回归模型
from sklearn.datasets import load_boston
data=load_boston()
x=data['data']
y=data['target']
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
In [ ]:
from sklearn.linear_model import LinearRegression
model=LinearRegression().fit(x_train,y_train)
In [ ]:
model.predict(x_test)
Out[ ]:
array([25.63512704, 18.20664391, 19.30419437, 17.56173266, 32.65076406,
20.51863333, 21.18307155, 17.69644861, 7.17364282, 21.24312946,
9.31181655, 22.58174485, 24.86143471, 17.14942807, 18.75445808,
32.02048648, 3.20366619, 18.45078084, 24.47301112, 19.91054657,
16.04118568, 23.7397113 , 7.84796407, 15.62557098, 27.29096309,
30.82585562, 22.4279634 , 20.70777259, 18.12353173, 18.57206891,
13.03685438, 12.61133503, 22.83018416, 16.01519429, 16.82163751,
24.51813482, 15.78043774, 23.40462434, 17.11255973, 28.93962029,
22.72251851, 33.18948449, 20.98919608, 20.07592808, 34.36482708,
25.23664217, 21.55366314, 15.94069443, 25.59419884, 14.1418572 ,
23.33774419, 25.04689547, 23.29641008, 33.950857 , 25.18734214,
7.63796202, 29.91317932, 13.18689018, 25.01891632, 31.05545963,
17.0977797 , 29.67337528, 36.4307191 , 16.05518381, 17.54582224,
32.33404942, 32.77216924, 18.44714854, 16.77438163, 17.65500137,
8.95855944, 27.58690131, 12.20201901, 24.89726481, 30.49544591,
21.85276613, 23.00784191, 31.17132898, 16.77202264, 18.96818273,
16.02055635, 24.45445282, 15.616554 , 22.85427056, 20.25649892,
18.5264222 , 21.18237716, 27.5588005 , 23.86810489, 16.56091536,
16.47704557, 26.20295992, 27.99514403, 10.97460741, 5.88779974,
32.77537677, 32.03321212, 15.50207643, 32.37743616, 21.86224154,
13.03662501, 21.32844856])
In [ ]:
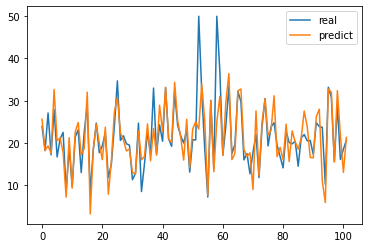
y_pre=model.predict(x_test)
In [ ]:
import matplotlib.pyplot as plt
plt.plot(range(len(y_test)),y_test)
plt.plot(range(len(y_pre)),y_pre)
plt.legend(['real','predict'])
plt.show()
In [ ]:
from sklearn.metrics import mean_squared_error,r2_score
mean_squared_error(y_true=y_test,y_pred=y_pre)
r2_score(y_true=y_test,y_pred=y_pre)
Out[ ]:
0.5489931237687122
7.参考文章
机器学习好伙伴之scikit-learn的使用——常用模型及其方法
【创作不易,望点赞收藏,若有疑问,请留言,谢谢】
使用scikit-learn构建模型的更多相关文章
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- jQuery源码解析对象实例化与jQuery原型及整体构建模型分析(一)
//源码剖析都基于jQuery-2.0.3版本,主要考虑到兼容IE 一.关于jQuery对象实例化的逻辑: 整个jQuery程序被包裹在一个匿名自执行行数内: (function(window,und ...
- 深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG.Inception.Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 使用SKlearn(Sci-Kit Learn)进行SVR模型学习
今天了解到sklearn这个库,简直太酷炫,一行代码完成机器学习. 贴一个自动生成数据,SVR进行数据拟合的代码,附带网格搜索(GridSearch, 帮助你选择合适的参数)以及模型保存.读取以及结果 ...
- 使用包图 (UML Package Diagram) 构建模型架构
包图用于以包包含层次结构的形式显示模型的组织方式.包图还可以显示包包含的模型元素以及包与其包含的模型元素之间的依赖关系. 在项目开发中,模型元素可能会很快达到大量数量,因此需要以某种方式构建它们,即使 ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
随机推荐
- anaconda3部署以及使用详解
Anaconda3-2019.10-Linux-x86_64.sh 某次执行Python程序,其中两个错误信息如下: ImportError: libcblas.so.3: cannot open s ...
- 【前端】css js 全屏 esc退出全屏 滚动条隐藏 兼容火狐,文字超出容器长度省略号显示
全屏 if (docElm.requestFullscreen) { docElm.requestFullscreen(); } else if (docElm.msRequestFullscreen ...
- Redis高可用二( 哨兵sentinel)
Redis高可用二( 哨兵sentinel) 1.主从配置 2.配置哨兵 sentinel.conf # Example sentinel.conf bind 0.0.0.0 protected-mo ...
- [COCI2008-2009 #2] PERKET
传送锚点:https://www.luogu.com.cn/problem/P2036 题目描述 Perket 是一种流行的美食.为了做好 Perket,厨师必须谨慎选择食材,以在保持传统风味的同时尽 ...
- Swoole 源码分析之 Channel 通道模块
原文首发链接:Swoole 源码分析之 Channel 通道模块 大家好,我是码农先森. 引言 通道,用于协程间通讯,支持多生产者协程和多消费者协程.底层自动实现了协程的切换和调度. 通道与 PHP ...
- 简单粗暴通过 Binlog 日志来恢复 MySQL 数据
引言 Binlog 日志的主要作用: 1.增量备份. 2.主从复制. 操作步骤 1.登录 MySQL -> 执行 show variables like '%log_bin%'; 查询 binl ...
- k8s 怎么精准获取deployment关联的pods?
标签获取 我们获取那些pods属于某个deployment时最先想到的可能是通过标签获取,其实这个是不准确的.因为标签并不是唯一的,也就是说不同deployment其实是能有相同标签的. replic ...
- Cmockery学习
什么是cmockery? 是一个轻量级的C语言单元测试框架 什么是单元测试? 单元测试就是测试一个系统的最小实现单元,往往是函数 示例解析 #include <stdarg.h> #inc ...
- 【论文笔记】ResNet深度残差网络
[深度学习]总目录 深度残差网络(ResNet)由微软研究院的何恺明.张祥雨.任少卿.孙剑提出.研究动机是为了解决深度网络的退化问题,不同于过去的网络是通过学习去拟合一个分布,ResNet通过学习去拟 ...
- C#笔记(1)窗体
1. 隐藏TabPage 在使用TabControl控件时,希望隐藏其中某个选项卡(即TabPage).设置该TabPage的父容器为null 即可,如TabPage.Parent = null .如 ...