提速 10 倍!深度解读字节跳动新型云原生 Spark History Server
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
前不久,在 6月29日 Databricks 举办的 Data + AI Summit 上,火山引擎向大家首次介绍了 UIMeta,一款致力于监控、分析和优化的新型云原生 Spark History Server,相比于传统的事件日志文件,它在缩小了近乎 10倍体积的基础上,居然还实现了提速 10倍!!!
目前,UIMeta Service 已经取代了原有的 History Server,为字节跳动每天数百万的作业提供服务,并且成为火山引擎 湖仓一体分析服务 LAS(LakeHouse Analytics Service)的默认服务。
实际上,对于 History Server来说,事件日志包含太多冗余信息,长时间运行的应用程序可能会带来巨大的事件日志,这可能需要大量维护并且需要很长时间才能重构 UI 数据从而提供服务。在大规模生产中,作业的数量可能很大,会给历史服务器带来沉重的负担。接下来,火山引擎 LAS 团队将向大家详细介绍字节跳动内部是怎么基于 UIMeta 实现海量数据业务的平稳和高效运转,让技术驱动业务不断发展。
业务背景
开源 Spark History Server 架构
为了能够更好理解本次重构的背景和意义,首先对原生 Spark History Server 原理做个简单的介绍。
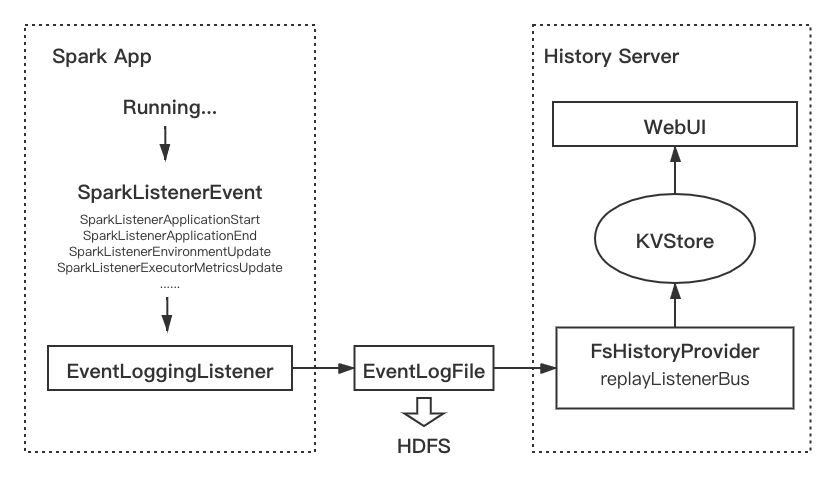
开源 Spark History Server 流程图
Spark History 建立在 Spark 事件(Spark Event)体系之上。在 Spark 任务运行期间会产生大量包含运行信息的SparkListenerEvent,例如 ApplicationStart / StageCompleted / MetricsUpdate 等等,都有对应的 SparkListenerEvent 实现。所有的 event 会发送到ListenerBus中,被注册在ListenerBus中的所有listener监听。其中EventLoggingListener是专门用于生成 event log 的监听器。它会将 event 序列化为 Json 格式的 event log 文件,写到文件系统中(如 HDFS)。通常一个机房的任务的文件都存储在一个路径下。
在 History Server 侧,核心逻辑在 FsHistoryProvider中。FsHistoryProvider 会维持一个线程间歇扫描配置好的 event log 存储路径,遍历其中的 event log 文件,提取其中概要信息(主要是 appliaction_id, user, status, start_time, end_time, event_log_path),维护一个列表。当用户访问 UI,会从列表中查找请求所需的任务,如果存在,就完整读取对应的 event log 文件,进行解析。解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 ReplayListener将其中信息反馈到 KVStore 中,还原任务的状态。
无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 KVStore中,KVStore是 Spark 中基于内存的KV存储,可以存储任意的类实例。前端会从KVStore查询所需的对象,实现页面的渲染。
痛点
存储空间开销大
Spark 的事件体系非常详细,导致 event log 记录的事件数量非常大,对于 UI 显示来说,大部分 event 是无用的。并且 event log 一般使用 json 明文存储,空间占用较大。对于比较复杂或时间长的任务,event log 可以达到几十 GB。字节内部 7 天的 event log 占用约 3.2 PB 的 HDFS 存储空间。
回放效率差,延迟高
History Server 采用回放解析 event log 的方式还原 Spark UI,有大量的计算开销,当任务较大就会有明显的响应延迟,响应延迟是指从用户发起前端访问到页面 UI 完全渲染出来的等待时长。作业结束之后,用户可能要等十几分钟甚至半小时才能通过 History Server 看到作业历史。而大型作业结束后,用户往往希望尽快看到作业历史从而根据作业历史进行问题诊断和作业优化,用户等待 UI 完成渲染时间过长,非常影响用户体验。
扩展性差
如上所述,History Server 的FsHistoryProvider在回放解析文件之前,需要先扫描配置的 event log 路径,遍历其中的 event log,将所有文件的元信息加载到内存中,这使得原生服务成为了有状态的服务。因此每次服务重启,都需要重新加载整个路径,才能对外服务。每个任务在完成后,也需要等待下一轮扫描才能被访问到。
当集群任务数量增多,每一轮扫描文件的耗时以及元信息内存占用都会增加,这也要求服务有越来越高的资源配置。如果通过拆分 event log 路径来缩小单实例的压力,需要对路由规则进行改造,运维难度增大。目前,字节跳动内部通过增加 UIService 实例就可以方便的进行水平扩展。
非云原生
Spark History Server 并非是云原生的服务,在公有云场景下改造和维护成本高。首先公有云场景需要进行租户资源隔离,其次公有云场景下不同用户的 workload 差异很大,不同用户任务量有数量级的差别,会出现大量长尾作业。为每个用户单独部署 History Server 计算和存储成本过大且不均衡,而部署统一的 History Server 无法做到资源隔离,一旦出现问题影响较多用户,两种方式运维成本都会很高。火山引擎湖仓一体分析引擎 LAS(Lakehouse Analytics Service),提供了云原生的 UIService,可以有效解决上述问题。
UIService
方案
为了解决前面的三个问题,我们尝试对 History Server 进行改造。如上所述,无论运行中的 Spark Driver 还是 History Server,都是通过监听 event,将其中包含的任务变化信息反映到几种 UI 相关的类的实例中,然后存入KVStore供 UI 渲染。也就是说,KVStore中存储着 UI 显示所需的完备信息。对于 History Server 的用户来说,绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 KVStore 持久化下来,而不需要存储大量冗余的 event 信息。此外,KVStore原生支持了 Kryo 序列化,性能明显于 Json 序列化。我们基于此思想重写了一套新的 History Server 系统,命名为 UIService。
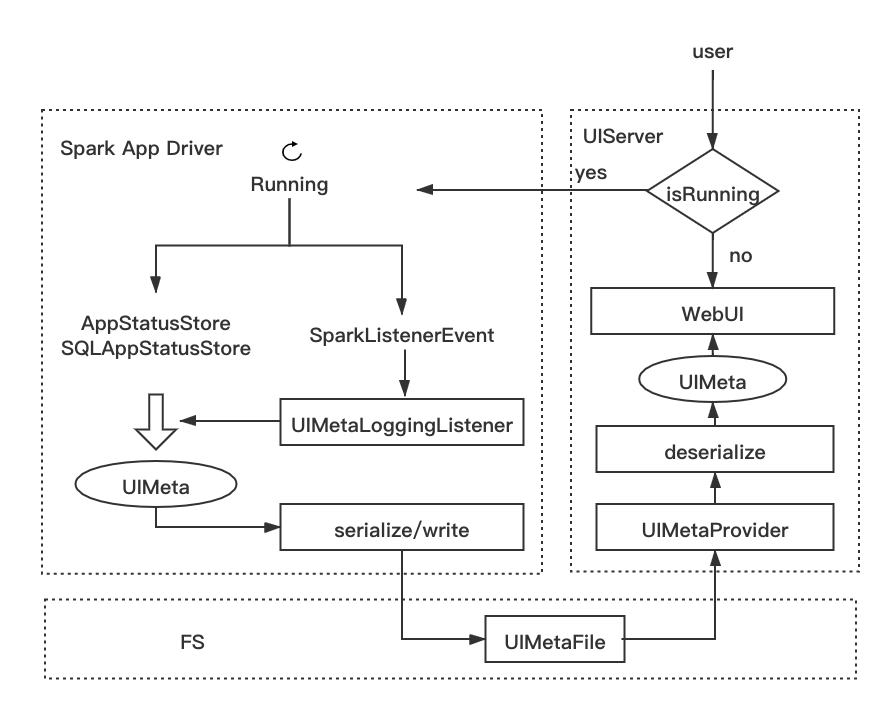
UIService框架图
实现
UIMetaStore
KVStore
中和 UI 相关的所有类实例,我们将这些类统称为 UIMeta 类。具体包括 AppStatusStore和SQLAppStatusStore中的信息(如下所列)。我们定义一个类 UIMetaStore来抽象,一个UIMetaStore即一个任务所有 UI 信息的集合。
UIMetaStore所包含信息:
# AppStatusStore
org.apache.spark.status.JobDataWrapper
org.apache.spark.status.ExecutorStageSummaryWrapper
org.apache.spark.status.ApplicationInfoWrapper
org.apache.spark.status.PoolData
org.apache.spark.status.ExecutorSummaryWrapper
org.apache.spark.status.StageDataWrapper
org.apache.spark.status.AppSummary
org.apache.spark.status.RDDOperationGraphWrapper
org.apache.spark.status.TaskDataWrapper
org.apache.spark.status.ApplicationEnvironmentInfoWrapper # SQLAppStatusStore
org.apache.spark.sql.execution.ui.SQLExecutionUIData
org.apache.spark.sql.execution.ui.SparkPlanGraphWrapper
UIMetaStore
还定义了持久化文件的数据结构,结构如下:
4-Byte Magic Number: "UI_S"
----------- Body ---------------
4_byte_length_of_class_name | class_name_str1 | 4_byte_length | serialized_of_class1_instance1
4_byte_length_of_class_name | class_name_str1 | 4_byte_length | serialized_of_class1_instance2
4_byte_length_of_class_name | class_name_str2 | 4_byte_length | serialized_of_class2_instance1
4_byte_length_of_class_name | class_name_str2 | 4_byte_length | serialized_of_class2_instance2
Magic Number用于文件类型标识校验。
Body 是
UIMetaStore的主体数据,使用连续存储。每一个 UI 相关的类实例,会序列化成四个片段:类名长度(4 byte long 类型)+ 类名(string 类型)+ 数据长度(4 byte long 类型)+ 序列化的数据(二进制类型)。在读取时顺序读取,每个元素先读取长度信息,再根据长度读取后续相应数据进行反序列化。使用 Spark 原生的
KVStoreSerializer序列化,可以保证前后兼容性。
UIMetaLoggingListener
类似于EventLoggingListener,为 UIMeta 开发了专用的 Listener —— UIMetaLoggingListener,用于监听事件,写 UIMeta 文件。和EventLoggingListener进行对比:EventLoggingListener每接受一个 event 都会触发写,写的是序列化的 event;而UIMetaLoggingListener只会被特定的 event 触发,目前是只会被stageEnd,JobEnd 事件触发,但每次写操作是批量的写,将上一阶段的UIMetaStore的信息完整地持久化。做一个类比,EventLoggingListener好比流式,不断地追加写,而 UIMetaLoggingListener类似于批式,定期将任务状态快照下来。
UIMetaProvider
替换原先的FsHistoryProvider,主要区别在于:
将读取 event log 文件和回放生成
KVStore的流程改为读取UIMetaFile,反序列化出UIMetaStore。去掉了
FsHistoryProvider的路径扫描逻辑;每次 UI 访问,根据 appid 和路径规则,直接去读取 UIMetaFile 解析。这使得 UIService 无需预加载所有文件元信息,不需要随着任务数量增加提高服务器配置,方便了水平扩展。
优化
避免重复写
由于每个 stage 完成都会触发写 UIMeta 文件,这样对于 UIMeta 的很多元素,可能会出现重复持久化的情况,增加写入耗时和文件的大小。因此我们在UIMetaLoggingListener内部维护了一个 map,记录已经被序列化的实例。在写 UIMeta 文件时进行过滤,只写没有写过或者数据发生改变的元素。这样可以杜绝大部分的写冗余。此外,开发期间发现,占用空间最大的是task级别信息TaskDataWrapper。在一个 stage 完成触发写时。可能会将仍处于 RUNNING 状态的 stage 的 task 序列化下来,这样当 RUNNING 的 stage 完成时,task 信息会再被写一次,也会造成数据冗余,因此我们对序列化TaskDataWrapper信息进行过滤,在 stage 结束时只持久化状态是 Completed 的 task 信息。
支持回退到 event log
鉴于 UIService 在初期有存在问题的风险,我们还支持了回退机制,即访问一个任务的 UI,优先尝试走 UIService 的路径:解析 UIMeta 文件,如果 UIMeta 文件不存在或者解析报错,会回退到读 event log 文件的路径,避免 UI 访问失败。同时还支持将 event log 文件转换成 UIMeta 文件,这样下一次调用时就可以使用 UIService。这个功能保证我们迁移过程的平滑。
收益
存储收益
线上测试显示存储平均减少85%,总量减少92.4%。
下图显示了某机房 event log 和 UIMeta 存储占用监控,可以看到 UIMeta 较 event log 在存储量上有数量级的减少。目前字节内部7天的 event log 占用存储空间 3.2 PB,改用 UIMeta 后,空间占用只有350TB。
凭借 UIService 的存储优势,我们可以保留更长时间的日志信息,有助于历史分析,问题复盘。目前我们已从保留7天日志提高到了保留30天,并可以根据需求增大保留时间。
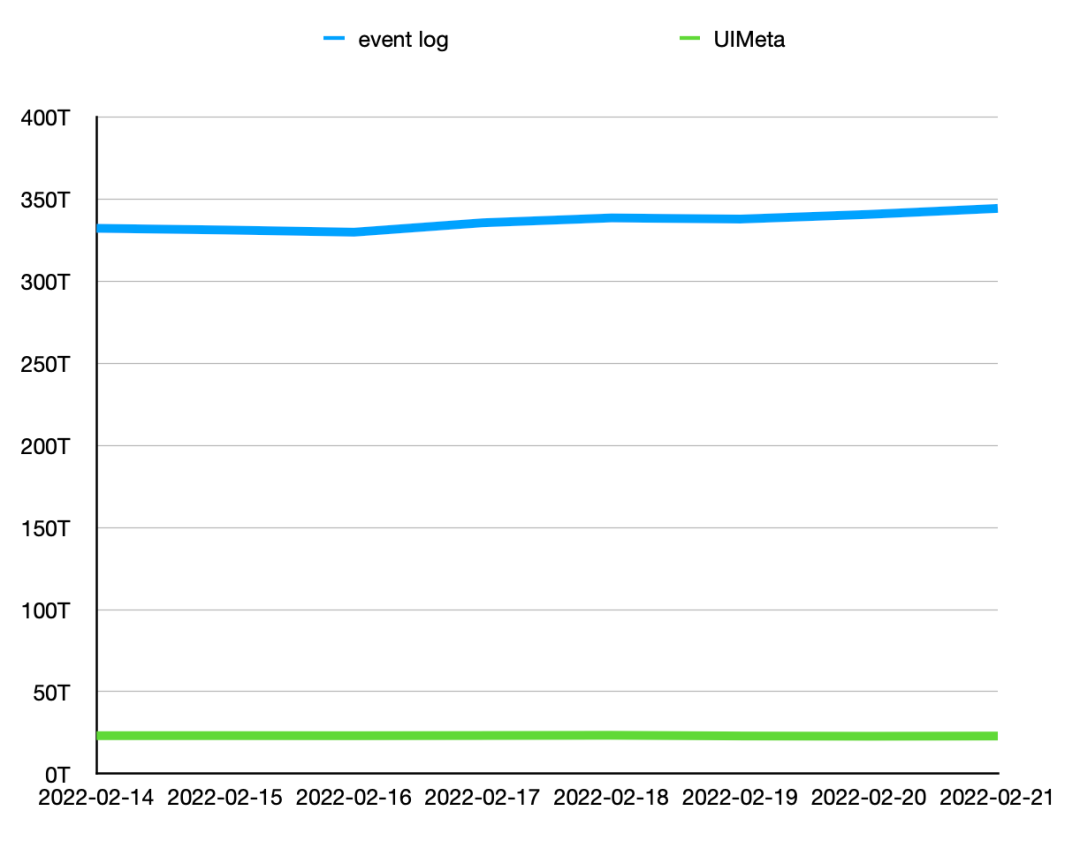
某机房 event log/UIMeta HDFS存储监控对比
访问延迟收益
访问延迟:平均缩短 35%,PCT90/95/99 分别减少 84.6%/90.8%/93.7%。
访问延迟百分位分布
如下图所示,UIService 的 UI 访问延迟整体较比 event log 向左移,长尾任务明显减少。
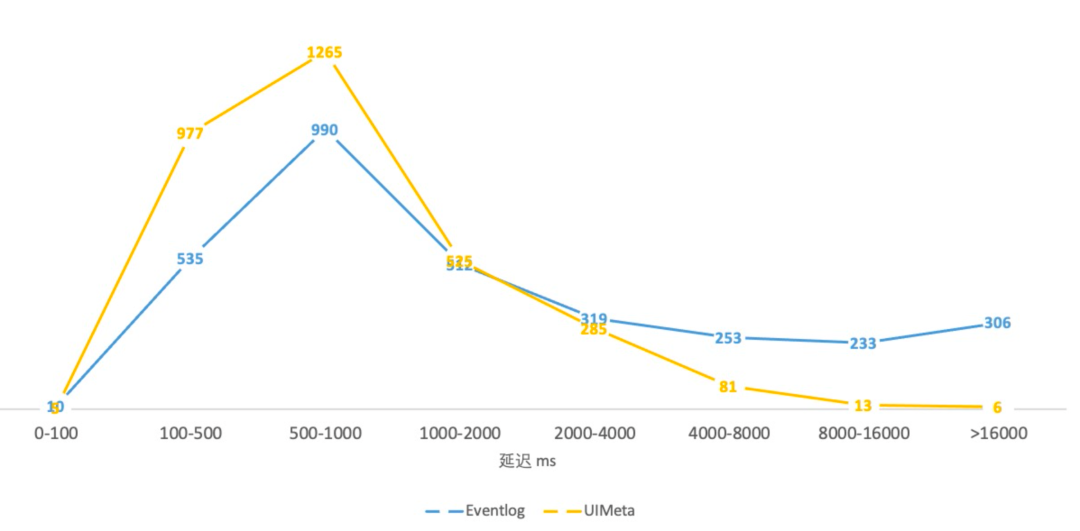
访问延迟分布图
架构收益
去掉了原生 History Server 遍历路径,预加载的耗时环节,消除从任务完成到 History Server 可访问的时间间隔,从原本的平均 10min 左右降低到秒级,任务完成即可立即对外提供服务。同时使 History Server 可以水平扩展,能更好应对未来任务量增长带来的挑战。
目前,字节跳动内部我们通过增加 UIService 实例就可以方便的进行横向扩展。在火山引擎湖仓一体分析服务 LAS 中,我们也基于 UIService 实现了支持租户访问隔离,云原生的,可按需伸缩的 Spark History Server。
提速 10 倍!深度解读字节跳动新型云原生 Spark History Server的更多相关文章
- 比MySQL快6倍 深度解析国内首个云原生数据库POLARDB的“王者荣耀”
随着移动互联网.电子商务的高速发展,被使用最多的企业级开源数据系统MySQL面临着巨大挑战——为迎接“双11"的高并发要提前做好分库分表;用户不断激增要将读写分离才能应对每天上亿次的访问,但 ...
- SmartIDE v0.1.18 已经发布 - 助力阿里国产IDE OpenSumi 插件安装提速10倍、Dapr和Jupyter支持、CLI k8s支持
SmartIDE v0.1.18 (cli build 3538) 已经发布,在过去的Sprint 18中,我们集中精力推进对 k8s 远程工作区 的支持,同时继续扩展SmartIDE对不同技术栈的支 ...
- SuperEdge再添国产智能加速卡支持,为边缘智能推理再提速10倍
作者 寒武纪AE团队,腾讯云容器中心边缘计算团队,SuperEdge 开发者 SuperEdge 支持国产智能加速卡寒武纪 MLU220 SuperEdge 对应的商业产品 TKE Edge 也一直在 ...
- 深度解析国内首个云原生数据库POLARDB的“王者荣耀”
随着移动互联网.电子商务的高速发展,被使用最多的企业级开源数据系统MySQL面临着巨大挑战--为迎接"双11"的高并发要提前做好分库分表;用户不断激增要将读写分离才能应对每天上亿次 ...
- Java网络编程与NIO详解10:深度解读Tomcat中的NIO模型
本文转自:http://www.sohu.com/a/203838233_827544 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 ht ...
- 【免费公测】阿里云SSD云盘,不仅仅是IO提速10倍
今天很高兴为大家介绍最新的ECS存储服务:SSD云盘. SSD云盘基于全SSD存储介质.利用阿里云飞天分布式存储技术,提供数据可靠性99.999%的高性能存储:该产品具备以下特点: l 高性能:单个 ...
- 这款 IDE 插件再次升级,让「小程序云」的开发部署提速 8 倍
今年3月份,在阿里云北京峰会上,阿里巴巴正式发布了“阿里巴巴小程序繁星计划”,截至当前,已经有成千上万的开发者加入这个计划,使得小程序得到蓬勃发展,然而不可避免的是,这些服务加重了对云端的开发部署.运 ...
- 使用 PyTorch Lightning 将深度学习管道速度提高 10 倍
前言 本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,主要包括有为什么优化深度学习管道很重要.使用 PyTorch Lightning 加快实验周期的六种 ...
- 深度介绍Flink在字节跳动数据流的实践
本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲分享,将着重分享Flink在字节跳动数据流的实践. 字节跳动数据流 ...
- 搜索 比MySQL快10倍?这可能是目前AWS Aurora最详解读!
作者介绍 朱阅岸,中国人民大学博士,现供职于腾讯云数据库团队.研究方向主要为数据库系统理论与实现.新硬件平台下的数据库系统以及TP+AP型混合系统. 编者按 Aurora作为AWS云上的关系数据库 ...
随机推荐
- Wonder8.promotion营销规则引擎,轻松搞掂千变万化的营销玩法
超过10年没有更新过内容了,不知道现在园子的氛围这类文章还适不适合放首页 想着整点内容,也是支持园子! 旺德發.营销 引擎 概述 为了广泛支持营销活动的复杂与灵活,Wonder8.promotion( ...
- c#组合模式详解
基础介绍: 组合模式用于表示部分-整体的层次结构.适用于希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象的情况. 顾名思义,什么叫部分-整体,比如常见的前端UI,一个 ...
- Python 包管理器入门指南
什么是 PIP? PIP 是 Python 包管理器,用于管理 Python 包或模块.注意:如果您的 Python 版本是 3.4 或更高,PIP 已经默认安装了. 什么是包? 一个包包含了一个模块 ...
- 整理unity资料
https://www.cnblogs.com/fly-100/p/3910515.html 协同的概念介绍
- CSS 元素居中方式总结
作者:WangMin 格言:努力做好自己喜欢的每一件事 在开发过程中,很多网页需求要求我们居中一个div,比如html文档流当中的一块div,比如弹出层内容部分这种脱离了文档流等.不同的情况有不同的居 ...
- 【译】Visual Studio 2022 - 17.8 的性能改进
Visual Studio 2022 17.8版本欢迎一系列令人振奋的性能增强,包括响应式文件打开体验,改进 Razor/Blazor 的响应性,加速 F5,优化的 C++ 虚幻引擎智能感知和非 SD ...
- 【uniapp】【外包杯】学习笔记day06 | 微信小程序导航栏的制作并推送的到码云【黑】
先创建分支 格式化快捷键 shift+alt+f
- QA12更改使用决策时自动转至长文本并报错 上载附件 Word2007template.dotm
*&---------------------------------------------------------------------**& Report Z_SCR_WORD ...
- 解决win10的wifi打不开或无法搜索到周围wifi的问题
今天笔者遇到了一个比较奇葩的问题,就是笔记本电脑的wifi打不开了,即使打开了也是搜索不到周围的wifi的.这个问题一开始笔者没有发现,因为在暑假期间都是使用笔记本连接自己的手机热点进行上网的.然而暑 ...
- 使用jvm工具排查系统问题
java-jvm-tool Jstatd 远程连接(推荐) 不用重启项目 远程机配置 [demo@localhost jvmtest]$ vi jstatd.all.policy# 内容grant c ...