OCR -- 文本识别 -- 理论篇
文本识别的应用场景很多,有文档识别、路标识别、车牌识别、工业编号识别等等,根据实际场景可以把文本识别任务分为两个大类:规则文本识别和不规则文本识别。
规则文本识别:主要指印刷字体、扫描文本等,认为文本大致处在水平线位置
不规则文本识别: 往往出现在自然场景中,且由于文本曲率、方向、变形等方面差异巨大,文字往往不在水平位置,存在弯曲、遮挡、模糊等问题。
下图展示的是 IC15 和 IC13 的数据样式,它们分别代表了不规则文本和规则文本。可以看出不规则文本往往存在扭曲、模糊、字体差异大等问题,更贴近真实场景,也存在更大的挑战性。
因此目前各大算法都试图在不规则数据集上获得更高的指标。
IC15 图片样例(不规则文本)
IC13 图片样例(规则文本)


不同的识别算法在对比能力时,往往也在这两大类公开数据集上比较。对比多个维度上的效果,目前较为通用的英文评估集合分类如下:

2 文本识别算法分类
在传统的文本识别方法中,任务分为3个步骤,即图像预处理、字符分割和字符识别。需要对特定场景进行建模,一旦场景变化就会失效。面对复杂的文字背景和场景变动,基于深度学习的方法具有更优的表现。
多数现有的识别算法可用如下统一框架表示,算法流程被划分为4个阶段:

我们整理了主流的算法类别和主要论文,参考下表:
| 算法类别 | 主要思路 | 主要论文 |
|---|---|---|
| 传统算法 | 滑动窗口、字符提取、动态规划 | - |
| ctc | 基于ctc的方法,序列不对齐,更快速识别 | CRNN, Rosetta |
| Attention | 基于attention的方法,应用于非常规文本 | RARE, DAN, PREN |
| Transformer | 基于transformer的方法 | SRN, NRTR, Master, ABINet |
| 校正 | 校正模块学习文本边界并校正成水平方向 | RARE, ASTER, SAR |
| 分割 | 基于分割的方法,提取字符位置再做分类 | Text Scanner, Mask TextSpotter |
2.1 规则文本识别
文本识别的主流算法有两种,分别是基于 CTC (Conectionist Temporal Classification) 的算法和 Sequence2Sequence 算法,区别主要在解码阶段。
基于 CTC 的算法是将编码产生的序列接入 CTC 进行解码;基于 Sequence2Sequence 的方法则是把序列接入循环神经网络(Recurrent Neural Network, RNN)模块进行循环解码,两种方式都验证有效也是主流的两大做法。
左:基于CTC的方法,右:基于Sequece2Sequence的方法
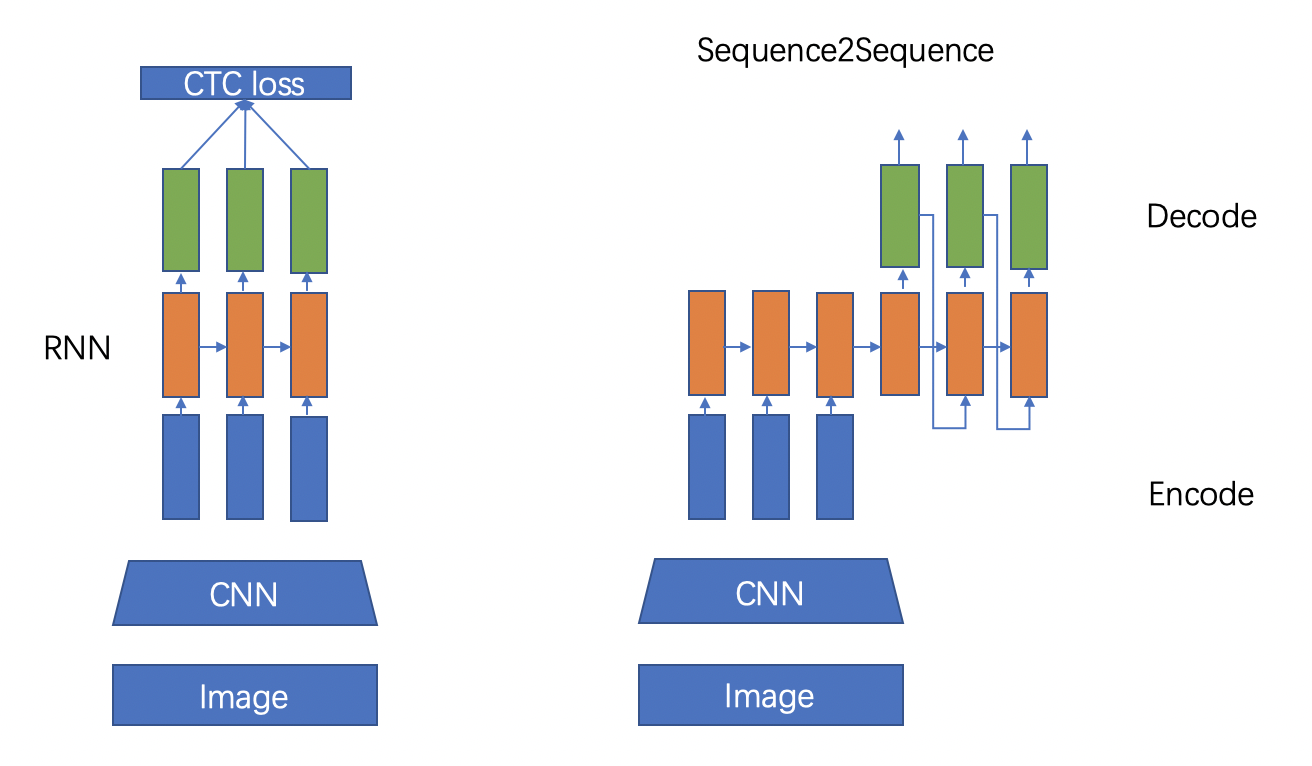
进入CNN,视觉特征提取
进入RNN,序列特征提取
2.1.1 基于CTC的算法
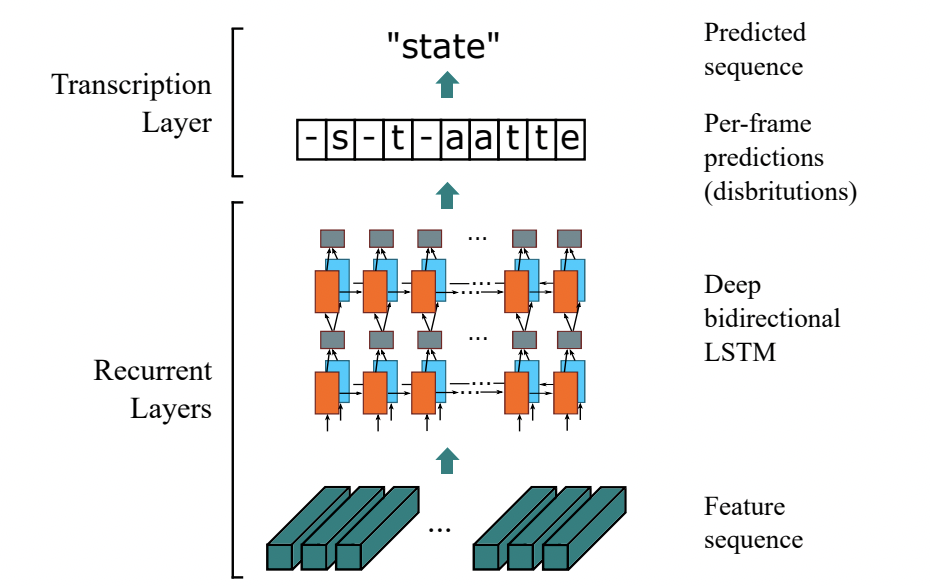
基于 CTC 最典型的算法是CRNN (Convolutional Recurrent Neural Network)[1],它的特征提取部分使用主流的卷积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。Rosetta[2]是FaceBook提出的识别网络,由全卷积模型和CTC组成。Gao Y[3]等人使用CNN卷积替代LSTM,参数更少,性能提升精度持平。
CRNN 结构图
2.1.2 Sequence2Sequence 算法
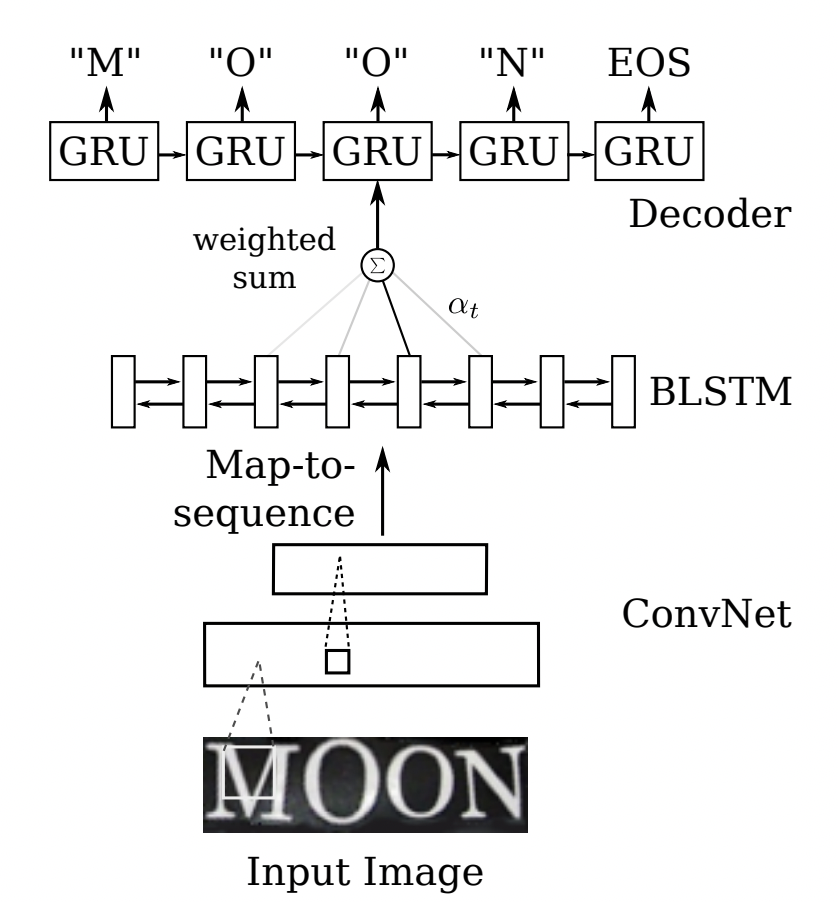
Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输出一系列字以创建转换。受到 Sequence2Sequence 在翻译领域的启发, Shi[4]提出了一种基于注意的编解码框架来识别文本,通过这种方式,rnn能够从训练数据中学习隐藏在字符串中的字符级语言模型。
Sequence2Sequence 结构图
以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的不规则文本识别任务。为了解决这类问题,部分算法研究人员在以上两类算法的基础上提出了一系列改进算法。
2.2 不规则文本识别
- 不规则文本识别算法可以被分为4大类:基于校正的方法;基于 Attention 的方法;基于分割的方法;基于 Transformer 的方法。
2.2.1 基于校正的方法
基于校正的方法利用一些视觉变换模块,将非规则的文本尽量转换为规则文本,然后使用常规方法进行识别。
RARE[4]模型首先提出了对不规则文本的校正方案,整个网络分为两个主要部分:一个空间变换网络STN(Spatial Transformer Network) 和一个基于Sequence2Squence的识别网络。其中STN就是校正模块,不规则文本图像进入STN,通过TPS(Thin-Plate-Spline)变换成一个水平方向的图像,该变换可以一定程度上校正弯曲、透射变换的文本,校正后送入序列识别网络进行解码。
RARE 结构图
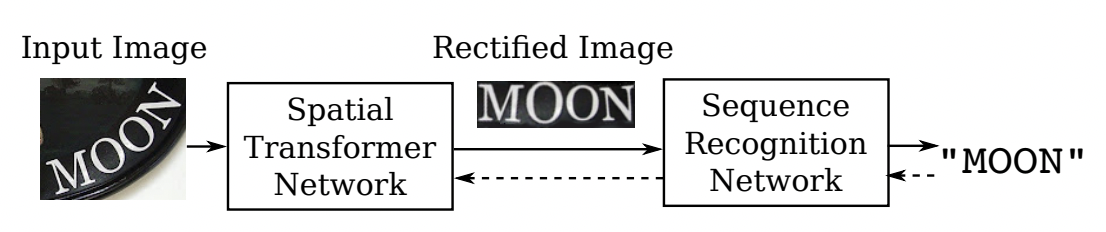
RARE论文指出,该方法在不规则文本数据集上有较大的优势,特别比较了CUTE80和SVTP这两个数据集,相较CRNN高出5个百分点以上,证明了校正模块的有效性。基于此[6]同样结合了空间变换网络(STN)和基于注意的序列识别网络的文本识别系统。
基于校正的方法有较好的迁移性,除了RARE这类基于Attention的方法外,STAR-Net[5]将校正模块应用到基于CTC的算法上,相比传统CRNN也有很好的提升。
2.2.2 基于Attention的方法
基于 Attention 的方法主要关注的是序列之间各部分的相关性,该方法最早在机器翻译领域提出,认为在文本翻译的过程中当前词的结果主要由某几个单词影响的,因此需要给有决定性的单词更大的权重。在文本识别领域也是如此,将编码后的序列解码时,每一步都选择恰当的context来生成下一个状态,这样有利于得到更准确的结果。
R^2AM [7] 首次将 Attention 引入文本识别领域,该模型首先将输入图像通过递归卷积层提取编码后的图像特征,然后利用隐式学习到的字符级语言统计信息通过递归神经网络解码输出字符。在解码过程中引入了Attention 机制实现了软特征选择,以更好地利用图像特征,这一有选择性的处理方式更符合人类的直觉。
R^2AM 结构图
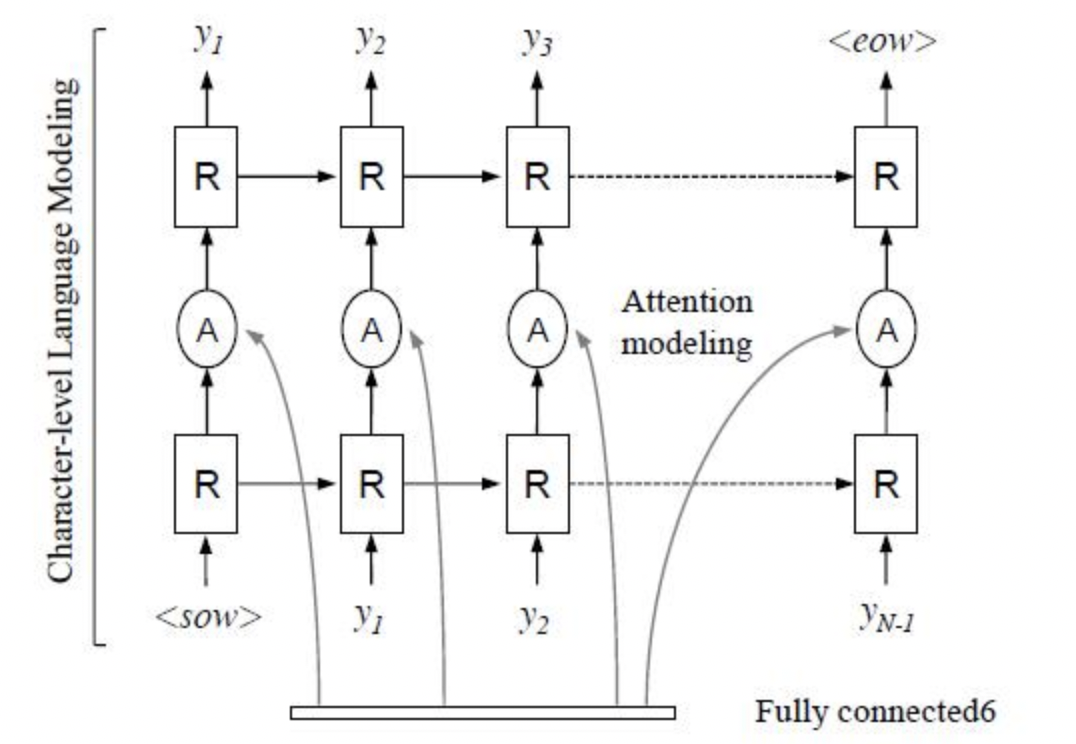
后续有大量算法在Attention领域进行探索和更新,例如SAR[8]将1D attention拓展到2D attention上,校正模块提到的RARE也是基于Attention的方法。实验证明基于Attention的方法相比CTC的方法有很好的精度提升。

2.2.3 基于分割的方法
基于分割的方法是将文本行的各字符作为独立个体,相比与对整个文本行做矫正后识别,识别分割出的单个字符更加容易。它试图从输入的文本图像中定位每个字符的位置,并应用字符分类器来获得这些识别结果,将复杂的全局问题简化成了局部问题解决,在不规则文本场景下有比较不错的效果。然而这种方法需要字符级别的标注,数据获取上存在一定的难度。Lyu[9]等人提出了一种用于单词识别的实例分词模型,该模型在其识别部分使用了基于 FCN(Fully Convolutional Network) 的方法。[10]从二维角度考虑文本识别问题,设计了一个字符注意FCN来解决文本识别问题,当文本弯曲或严重扭曲时,该方法对规则文本和非规则文本都具有较优的定位结果。
Mask TextSpotter 结构图

2.2.4 基于Transformer的方法
随着 Transformer 的快速发展,分类和检测领域都验证了 Transformer 在视觉任务中的有效性。如规则文本识别部分所说,CNN在长依赖建模上存在局限性,Transformer 结构恰好解决了这一问题,它可以在特征提取器中关注全局信息,并且可以替换额外的上下文建模模块(LSTM)。
一部分文本识别算法使用 Transformer 的 Encoder 结构和卷积共同提取序列特征,Encoder 由多个 MultiHeadAttentionLayer 和 Positionwise Feedforward Layer 堆叠而成的block组成。MulitHeadAttention 中的 self-attention 利用矩阵乘法模拟了RNN的时序计算,打破了RNN中时序长时依赖的障碍。也有一部分算法使用 Transformer 的 Decoder 模块解码,相比传统RNN可获得更强的语义信息,同时并行计算具有更高的效率。
SRN[11] 算法将Transformer的Encoder模块接在ResNet50后,增强了2D视觉特征。并提出了一个并行注意力模块,将读取顺序用作查询,使得计算与时间无关,最终并行输出所有时间步长的对齐视觉特征。此外SRN还利用Transformer的Eecoder作为语义模块,将图片的视觉信息和语义信息做融合,在遮挡、模糊等不规则文本上有较大的收益。
NRTR[12] 使用了完整的Transformer结构对输入图片进行编码和解码,只使用了简单的几个卷积层做高层特征提取,在文本识别上验证了Transformer结构的有效性。
NRTR 结构图
SRACN[13]使用Transformer的解码器替换LSTM,再一次验证了并行训练的高效性和精度优势。
原文:https://aistudio.baidu.com/aistudio/projectdetail/6276554
OCR -- 文本识别 -- 理论篇的更多相关文章
- 个人永久性免费-Excel催化剂功能第86波-人工智能之图像OCR文本识别全覆盖
在上一年中,Excel催化剂已经送上一波人工智能系列功能,鉴于部分高端用户的需求,再次给予实现了复杂的图像OCR识别,包含几乎所有日常场景,让公司个人手头的图像非结构化数据瞬间变为可进行结构化处理分析 ...
- Android OCR文字识别 实时扫描手机号(极速扫描单行文本方案)
身份证识别:https://github.com/wenchaosong/OCR_identify 遇到一个需求,要用手机扫描纸质面单,获取面单上的手机号,最后决定用tesseract这个开源OCR库 ...
- OCR文字识别软件 怎么识别包含非常规符号的文本
ABBYY FineReader 12 是一款OCR图文识别软件,可快速方便地将扫描纸质文档.PDF文件和数码相机的图像转换成可编辑.可搜索的文本,有时文本中可能会包含一些非常规的符号,此时ABBYY ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- CVPR2020论文解读:OCR场景文本识别
CVPR2020论文解读:OCR场景文本识别 ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network∗ 论文 ...
- 我的AI之路 —— OCR文字识别快速体验版
OCR的全称是Optical Character Recoginition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别.交通路牌的识别.车牌的自动识别等等. ...
- OCR文字识别笔记总结
OCR的全称是Optical Character Recognition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别,交通路牌的识别,车牌的自动识别等等.本 ...
- 超简单集成华为HMS ML Kit文本识别SDK,一键实现账单号自动录入
前言 在之前的文章<超简单集成华为HMS Core MLKit通用卡证识别SDK,一键实现各种卡绑定>中我们给大家介绍了华为HMS ML Kit通用卡证识别技术是如何通过拍照自动识别卡 ...
- [OpenCV实战]35 使用Tesseract和OpenCV实现文本识别
目录 1 如何在Ubuntu和windows上安装Tesseract 1.1 在ubuntu18.04上安装Tesseract4 1.2 在Ubuntu 14.04,16.04,17.04,17.10 ...
- 对OCR文字识别软件的扫描选项怎么设置
说到OCR文字识别软件,越来越多的人选择使用ABBYY FineReader识别和转换文档,然而并不是每个人都知道转换质量取决于源图像的质量和所选的扫描选项,今天就给大家普及一下这方面的知识. ABB ...
随机推荐
- 从头开始——重新布置渗透测试环境的过程记录(From Windows To Mac)
因为疫情和工作的原因,2022年整整一年我基本没有深度参与过网络安全和渗透测试相关的工作. 背景:之前因为使用习惯,一直使用的是ThinkPad X1 Extreme,可联想的品控实在拉胯,奈何Thi ...
- Centos9网卡配置
Centos9 网卡配置文件已修改,如下 [root@bogon ~]# cat /etc/NetworkManager/system-connections/ens18.nmconnection [ ...
- [Linux]常用命令之【top/uptime/w/vmstat/free】
1 top 语法:top [-s time] [-d count] [-q] [-u] [-h] [-n number] [-f filename] -s time 设置屏幕刷新的延时,单位为秒,默认 ...
- 教程 - 在 Vue3+Ts 中引入 CesiumJS 的最佳实践@2023
目录 1. 本篇适用范围与目的 1.1. 适用范围 1.2. 目的 2. 牛刀小试 - 先看到地球 2.1. 创建 Vue3 - TypeScript 工程并安装 cesium 2.2. 清理不必要的 ...
- Redis读书笔记(三)
单机数据库的实现 Redis数据库 Redis数据库的实现 struct redisServer { //... //保存服务器中的所有数据库, 数组 redisDB *db; //服务器的数据库数量 ...
- C# System.ObjectDisposedException: Cannot access a disposed object, A common cause of thiserror is disposing a context that was resolved from dependency injection and then later trying touse...
项目中使用了依赖注入,这个错误在我项目中的原因:在async修饰的异步方法中,调用执行数据库操作的方法时,没有使用await关键字调用,因为没有等待该调用,所以在调用完成之前将继续执行该方法.因此,已 ...
- Github 添加贪吃蛇动画
前言 我们都知道,对于Github来说,当你选择你的账户时,可以看到自己的提交记录. 于是就有大神动脑筋了,这些commit记录都是一些豆,如果弄一条蛇来,不就可以搞个贪吃蛇了吗? 有道理有道理,本文 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之图生图进阶篇
目录 图生图基本参数 图生图(img2img) 涂鸦绘制(Sketch) 局部绘制(Inpaint) 涂鸦蒙版(Inpaint sketch) 上传蒙版(Inpaint upload) 图生图基本参数 ...
- JUC(一)JUC简介与Synchronized和Lock
1 JUC简介 JUC就是java.util.concurrent的简称,这是一个处理线程的工具包,JDK1.5开始出现的. 进程和线程.管程 进程:系统资源分配的基本单位:它是程序的一次动态执行过程 ...
- Restless API 与 Restful API
Restful API: 1.CURD(增删改查) 由请求方式决定 2.请求方式有:get/post/delete/put 3.同一个路径可以进行多个操作 Restless API 1.CURD(增 ...