数据库重构之路,以 OrientDB 到 NebulaGraph 为例

“本文由社区用户 @阿七从第一视角讲述其团队重构图数据库的过程,首发于阿七公众号「浅谈架构」”
一、写在前面
读过我公众号文章的同学都知道,我做过很多次重构,可以说是“重构钉子户”,但是这次,重构图数据库 OrientDB 为 NebulaGraph(https://www.nebula-graph.com.cn/),可以说是我做过最艰难的一次重构。
{kind=link}
那这篇文章就来聊聊,图数据库重构之路。
二、难点在哪里
- 历史包袱重,原来使用 OrientDB 系统是2016年开始开发的,逻辑很复杂,历史背景完全不清楚。
- 业务不了解,我们是临时接的大数据需求,之前没有参与过这块业务,完全不了解。
- 技术栈不了解,图数据库是第一次接触(团队中也没有人了解),OrientDB 和 NebulaGraph 之前都没有接触过,原来老系统大部分代码是 Scala 语言写的,系统中使用的 HBase、Spark、Kafka,对于我们也比较陌生。
- 时间紧迫
总结来说: 业务不了解,技术栈不熟悉
tips: 大家思考一个问题,在业务和技术栈都不熟的情况下,如何做重构呢?
三、技术方案
下面介绍一下本次重构技术方案
1、迁移背景
猎户座的图数据库 OrientDB 存在性能瓶颈和单点问题,需升级为 NebulaGraph。
老系统是用使用技术栈无法支持弹性伸缩,监控报警设施也不够完善。
具体的使用痛点后续我将会写一篇文章具体讲述下,本篇就不详细展开了。
2、调研事项
注:既然业务都不熟悉,那我们都调研了哪些东西呢?
- 对外接口梳理:梳理系统所有对外接口,包括接口名、接口用途、请求量 QPS、平均耗时,调用方(服务和 IP);
- 老系统核心流程梳理:输出老系统整理架构图,重要的接口(大概 10 个)输出流程图;
- 环境梳理:涉及到的需要改造的项目有哪些,应用部署、MySQL、Redis、HBase 集群 IP,及目前线上部署分支整理;
- 触发场景:接口都是如何触发的,从业务使用场景出发,每个接口至少一个场景覆盖到,方便后期功能验证;
- 改造方案:可行性分析,针对每一个接口,如何改造(OrientDB 语句改为 NebulaGraph 查询语句),入图(写流程)如何改造;
- 新系统设计方案: 输出整理架构图,核心流程图。
3、项目目标
完成图数据库数据源 OrientDB 改造为 NebulaGraph,重构老系统统一技术栈为 Java,支持服务水平扩展。
4、整体方案
我们采用了比较激进的方案:
- 从调用接口入口出发,直接重写底层老系统,影响面可控;
- 一劳永逸,方便后期维护;
- 统一 Java 技术栈、接入公司统一服务框架,更利于监控及维护;
- 基础图数据库应用边界清晰,后续上层应用接入图数据库更简单。
注:这里就贴调研阶段画的图,图涉及业务,我这里就不列举了。
5、灰度方案
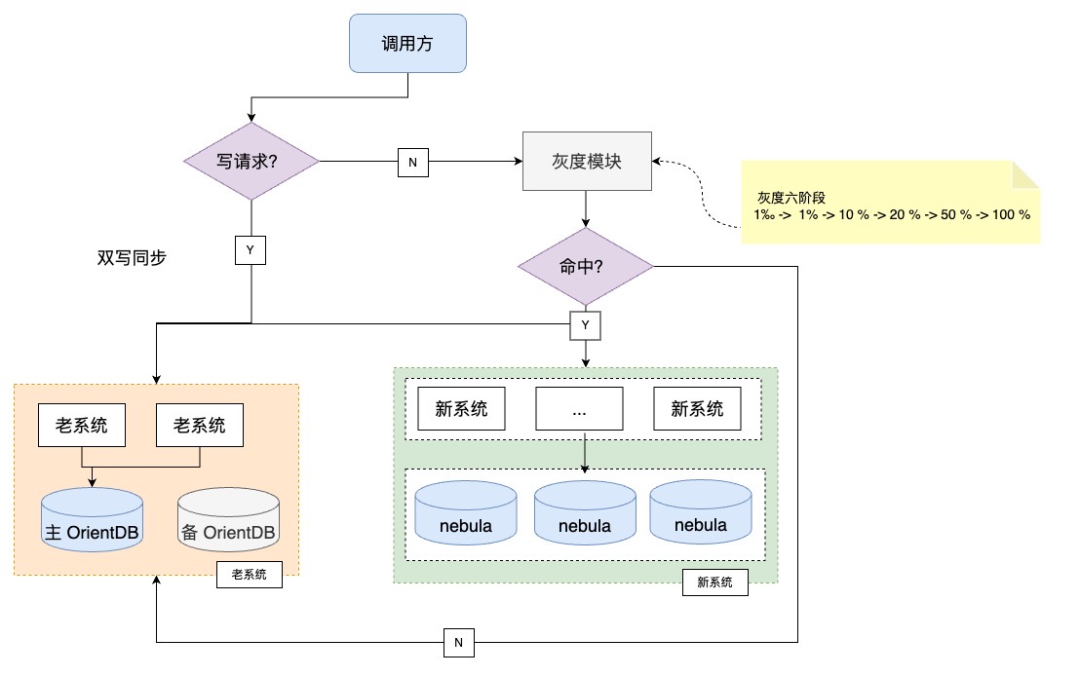
灰度方案
- 写请求:采用同步双写
- 读请求:按流量从小到大陆续迁移、平滑过渡
灰度计划
| 阶段一 | 阶段二 | 阶段三 | 阶段四 | 阶段五 | 阶段六 | 阶段七 |
|---|---|---|---|---|---|---|
| 0% | 1‰ | 1% | 10% | 20% | 50% | 100% |
| 同步双写, 流量回放采样对比,100% 通过、预计灰度 2 天 | 灰度 2 天 | 灰度 2 天 | 灰度 5 天、此阶段要压测 | 灰度 2 天 | 灰度 2 天 | - |
注:
- 配置中心开关控制,有问题随时切换,秒级恢复。
- 读接口遗漏无影响, 只有改到的才会影响。
- 使用参数 hash 值作为 key,确保同一参数多次请求结果一致、满足 abs(key) % 1000 < X ( 0< X < 1000, X 为动态配置 ) 即为命中灰度。
题外话:其实重构,最重要的就是灰度方案,这个我在之前文章《浅谈这些年做过的千万级系统重构项目》也提到过。本次灰度方案设计比较完善,大家重点看阶段一、在灰度放量之前,我们用线上真实的流量去异步做数据对比,对比完全通过之后,再放量,本次对比阶段比预期长了很多(实际上用了 2 周时间,发现了很多问题)。
6、数据对比方案
未命中灰度
未命中灰度流程如下:
先调用老系统,再根据是否命中采样(采样比例配置 0% ~ 100%),命中采样会发送 MQ,再在新系统消费 MQ,请求新系统接口,于老系统接口返回数据进行 JSON 对比。对比不一致,发送企业微信通知,实时感知数据不一致,发现并解决问题。
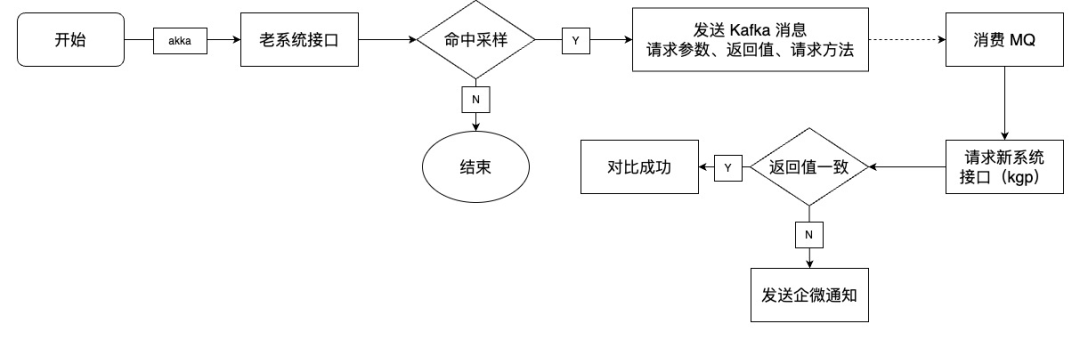
反之亦然!!
7、数据迁移方案
- 全量(历史数据):写脚本全量迁移,上线期间产生不一致从 MQ 消费近 3 天数据
- 增量:同步双写(写的接口很少,写请求 QPS 不高)
8、改造案例 - 以子图查询为例
改造前:
@Override
public MSubGraphReceive getSubGraph(MSubGraphSend subGraphSend) {
logger.info("-----start getSubGraph------(" + subGraphSend.toString() + ")");
MSubGraphReceive r = (MSubGraphReceive) akkaClient.sendMessage(subGraphSend, 30);
logger.info("-----end getSubGraph:");
return r;
}
改造后:
定义灰度模块接口
public interface IGrayService {
/**
* 是否命中灰度 配置值 0 ~ 1000 true: 命中 false:未命中
*
* @param hashCode
* @return
*/
public boolean hit(Integer hashCode);
/**
* 是否取样 配置值 0 ~ 100
*
* @return
*/
public boolean hitSample();
/**
* 发送请求-响应数据
* @param requestDTO
*/
public void sendReqMsg(MessageRequestDTO requestDTO);
/**
* 根据
* @param methodKeyEnum
* @return
*/
public boolean hitSample(MethodKeyEnum methodKeyEnum);
}
接口改造如下, kgpCoreService 请求到 kgp-core 新服务,接口业务逻辑和 orion-x 保持一致、底层图数据库改为查询 NebulaGraph:
@Override
public MSubGraphReceive getSubGraph(MSubGraphSend subGraphSend) {
logger.info("-----start getSubGraph------(" + subGraphSend.toString() + ")");
long start = System.currentTimeMillis();
//1. 请求灰度
boolean hit = grayService.hit(HashUtils.getHashCode(subGraphSend));
MSubGraphReceive r;
if (hit) {
//2、命中灰度 走新流程
r = kgpCoreService.getSubGraph(subGraphSend); // 使用Dubbo调用新服务
} else {
//这里是原来的流程 使用的akka通信
r = (MSubGraphReceive) akkaClient.sendMessage(subGraphSend, 30);
}
long requestTime = System.currentTimeMillis() - start;
//3.采样命中了发送数据对比MQ
if (grayService.hitSample(MethodKeyEnum.getSubGraph_subGraphSend)) {
MessageRequestDTO requestDTO = new MessageRequestDTO.Builder()
.req(JSON.toJSONString(subGraphSend))
.res(JSON.toJSONString(r))
.requestTime(requestTime)
.methodKey(MethodKeyEnum.getSubGraph_subGraphSend)
.isGray(hit).build();
grayService.sendReqMsg(requestDTO);
}
logger.info("-----end getSubGraph: {} ms", requestTime);
return r;
}
9、项目排期计划
投入人力: 开发 4 人,测试 1 人
主要事项及耗时如下:

10、所需资源
略,这里不展开讲述。
四、重构收益
经过团队 2 个月奋斗,目前已完成灰度阶段,收益如下
- NebulaGraph 本身支持分布式扩展,新系统服务支持弹性伸缩,整体支持性能水平扩展;
- 从压测结果看,接口性能提升很明显,可支撑请求远超预期;
- 接入公司统一监控、告警,更利于后期维护。
五、总结
本次重构顺利完成,感谢本次一起重构的小伙伴,以及大数据、风控同学支持,同时也感谢 NebulaGraph社区(https://discuss.nebula-graph.com.cn/),我们遇到一些问题提问,也很快帮忙解答。
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
数据库重构之路,以 OrientDB 到 NebulaGraph 为例的更多相关文章
- android开发之路06(浅谈单例设计模式)
设计模式之单例模式: 一.单例模式实现特点:①单例类在整个应用程序中只能有一个实例(通过私有无参构造器实现):②单例类必须自己创建这个实例并且可供其他对象访问(通过静态公开的访问权限修饰的getIns ...
- 第五章、 Linux 常用網路指令
http://linux.vbird.org/linux_server/0140networkcommand.php 第五章. Linux 常用網路指令 切換解析度為 800x600 最近更新 ...
- 利用 crontab 來做 Linux 固定排程
crontab 介紹 crontab 是 Linux 內建的機制,可以根據設置的時間參數來執行例行性的工作排程. 上述這張圖可以清楚的顯示出前五項參數應該要帶進去的數字.依序是分鐘, 小時, 日期, ...
- Tomcat配置多个端口号或多个应用
一.在Tomcat下配置一个应用服务(service)中,配置多个端口号. 即一个service配置多个端口,项目可以通过多个端口访问. 修改tomcat-home\conf下的server.xml, ...
- TCP/IP卷一:第一章
================================================= 版權聲明:如需轉載,請列明出處:HingAglaiaWong@博客園 支持原創,是對作者最好的的鼓勵 ...
- 【Linux基础】查看硬件信息-CPU
1.物理CPU数:计算机上实际配置的CPU个数. //查看计算机物理CPU个数(必须先sort后uniq) cat /proc/cpuinfo | grep "physical id&quo ...
- reids的搭建
---恢复内容开始--- redis的安装 源码包安装 以reids3.0为例 先安装编译的软件 gcc gcc-c++ make yum -y install gcc gcc-c++ make ...
- linux文件和目錄管理的基本命令命令
ls命令 作用:顯示目標列表或目錄的內容 語法:ls[選項][目錄或文件] -a:顯示指定目錄下所有子目錄與文件,包括隱藏文件 -l:顯示文件的詳細信息 -d: 顯示目錄 例:ls -dl cd命令 ...
- linux下 ip指令
目录 Network ip command Command :ip 简介 内容 Network ip command Command :ip 简介 ip 是個指令喔!並不是那個 TCP/IP 的 IP ...
- 软工读书笔记 week4 ——《黑客与画家》下
因为时间有限,只对书中后半部分几个篇章进行了阅读. 一.另一条路 作者以他自己为例,在那个没人知道什么叫“软件运行在服务器时”的时代,他和朋友选择创业时,没有选择写传统的桌面 ...
随机推荐
- 图解Redis和Zookeeper分布式锁
1.基于Redis实现分布式锁 Redis分布式锁原理如上图所示,当有多个Set命令发送到Redis时,Redis会串行处理,最终只有一个Set命令执行成功,从而只有一个线程加锁成功 2:SetNx命 ...
- SpringBoot配置文件加载
Spring Boot 配置文件加载是通过 Spring Boot 的自动配置机制实现的,它可以根据不同的环境加载不同的配置文件,包括 application.properties.applicati ...
- vulnhub_jangow
来源 vulnhub:https://www.vulnhub.com/entry/jangow-101,754/ 描述 难度:简单 这在 VirtualBox 而不是 VMware 上效果更好 我这里 ...
- 算法基础(一):串匹配问题(BF,KMP算法)
好家伙,学算法, 这篇看完,如果没有学会KMP算法,麻烦给我点踩 希望你能拿起纸和笔,一边阅读一边思考,看完这篇文章大概需要(20分钟的时间) 我们学这个算法是为了解决串匹配的问题 那什么是串匹配 ...
- 函数接口(Functional Interfaces)
定义 首先,我们先看看函数接口在<Java语言规范>中是怎么定义的: 函数接口是一种只有一个抽象方法(除Object中的方法之外)的接口,因此代表一种单一函数契约.函数接口的抽象方法可以是 ...
- in用不用索引,啥时候能用啥时候不能用,一文说清
in/or到底能不能用索引应该是肯定的,但有时生效有时不生效,这个能不能量化计算?这是本文想讨论和解答的问题. in到底用不用索引感觉像一桩悬疑片!古早时期的面经,统一说不走索引,在一些程序员脑海中从 ...
- 现代C++学习指南-具体类
类作为C++中重要的概念之一,有着众多的特性,也是最迷人的部分! 类是一个加工厂,开发者使用C++提供的各种材料组装这个工厂,使得它可以生产出符合自己要求的数据,通过对工厂的改造,可以精细控制对象从出 ...
- Mysql数据库常见故障
Mysql数据库常见故障 1.报错现象 Host is blocked because of many connection errors; unblock with 'mysqladmin flus ...
- Kubernetes(k8s)服务账号Service Accounts
目录 一.系统环境 二.前言 三.服务账号Service Accounts简介 四.用户账号与服务账号区别 五.服务账号(Service Accounts) 5.1 创建服务账号(Service Ac ...
- Visual Studio2019如何添加引用
同一解决方案中添加引用 比如我们想在Test项目中添加Queue项目的引用 1.鼠标右击引用-->添加引用 2."引用管理器"-->项目-->解决方案--&g ...