并行化强化学习 —— 最终版本 —— 并行reinforce算法的尝试
本文代码地址:
https://gitee.com/devilmaycry812839668/final_-version_-parallelism_-reinforce_-cart-pole
结合了前面几个版本的并行化强化学习的设计,给出了最终版本。gym下简单的CarlPole环境作为仿真环境,以reinforce算法作为实例算法,讨论了强化学习在多仿真环境下并行化设计的可行性,并给出了几种个人设计的架构,同时对各架构的性能进行了一定的分析。
----------------------------------------------------------------------
本文是前面几篇 并行化强化学习 系统的终结版,与前面博文内容一样都是探索强化学习中并行化数据生成部分的设计,也就是说仿真环境下的多actoer的设计。
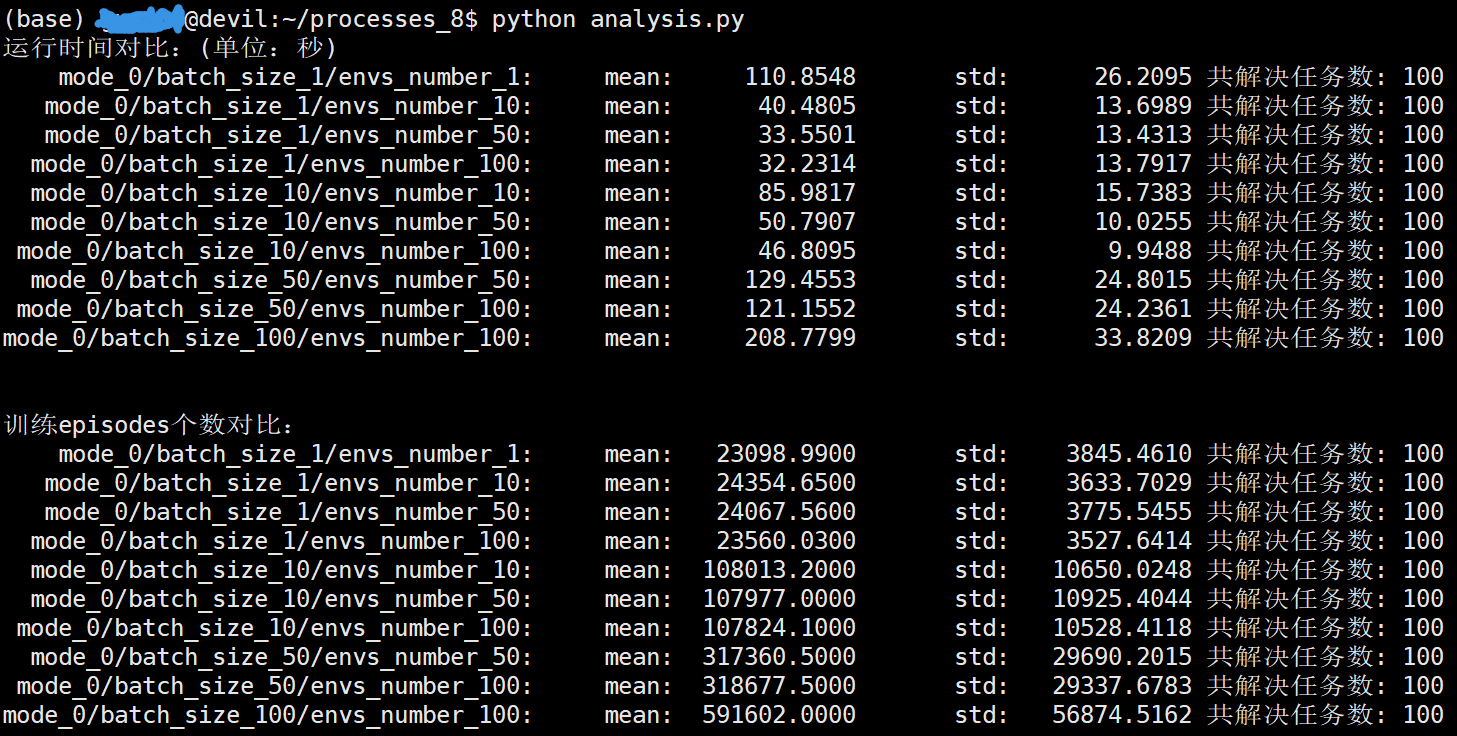
在 i7-9700k CPU上进行测试,mode=0为多进程多环境多actoer的设计:
/home/devilmaycry/anaconda3/envs/tf-14.0/bin/python -u /home/guojun/processes_8/analysis.py
运行时间对比:(单位:秒)
mode_0/batch_size_1/envs_number_1: mean: 110.8548 std: 26.2095 共解决任务数: 100
mode_0/batch_size_1/envs_number_10: mean: 40.4805 std: 13.6989 共解决任务数: 100
mode_0/batch_size_1/envs_number_50: mean: 33.5501 std: 13.4313 共解决任务数: 100
mode_0/batch_size_1/envs_number_100: mean: 32.2314 std: 13.7917 共解决任务数: 100
mode_0/batch_size_10/envs_number_10: mean: 85.9817 std: 15.7383 共解决任务数: 100
mode_0/batch_size_10/envs_number_50: mean: 50.7907 std: 10.0255 共解决任务数: 100
mode_0/batch_size_10/envs_number_100: mean: 46.8095 std: 9.9488 共解决任务数: 100
mode_0/batch_size_50/envs_number_50: mean: 129.4553 std: 24.8015 共解决任务数: 100
mode_0/batch_size_50/envs_number_100: mean: 121.1552 std: 24.2361 共解决任务数: 100
mode_0/batch_size_100/envs_number_100: mean: 208.7799 std: 33.8209 共解决任务数: 100 训练episodes个数对比:
mode_0/batch_size_1/envs_number_1: mean: 23098.9900 std: 3845.4610 共解决任务数: 100
mode_0/batch_size_1/envs_number_10: mean: 24354.6500 std: 3633.7029 共解决任务数: 100
mode_0/batch_size_1/envs_number_50: mean: 24067.5600 std: 3775.5455 共解决任务数: 100
mode_0/batch_size_1/envs_number_100: mean: 23560.0300 std: 3527.6414 共解决任务数: 100
mode_0/batch_size_10/envs_number_10: mean: 108013.2000 std: 10650.0248 共解决任务数: 100
mode_0/batch_size_10/envs_number_50: mean: 107977.0000 std: 10925.4044 共解决任务数: 100
mode_0/batch_size_10/envs_number_100: mean: 107824.1000 std: 10528.4118 共解决任务数: 100
mode_0/batch_size_50/envs_number_50: mean: 317360.5000 std: 29690.2015 共解决任务数: 100
mode_0/batch_size_50/envs_number_100: mean: 318677.5000 std: 29337.6783 共解决任务数: 100
mode_0/batch_size_100/envs_number_100: mean: 591602.0000 std: 56874.5162 共解决任务数: 100
可以看到相同batch_size的情况下,需要迭代计算的次数时相当的,这里可以近似的看做是相同的,也就是说batch_size相同的情况下迭代计算的次数是大致相同的。
在所有的设置中当batch_size=1的时候可以取得最快的运算速度。由于测试环境中CPU只有8个核心,单batch_size设置过大时会导致单进程计算时间大幅增加,导致总的计算时间增加。同时我们还可以看到单环境数增加到一定程度后并不能继续的明显加快计算速度,考虑过多的环境数设置会拉大训练数据的分布与当前训练的策略分布间的差距造成不收敛等问题,因此环境数的设置不可过大。
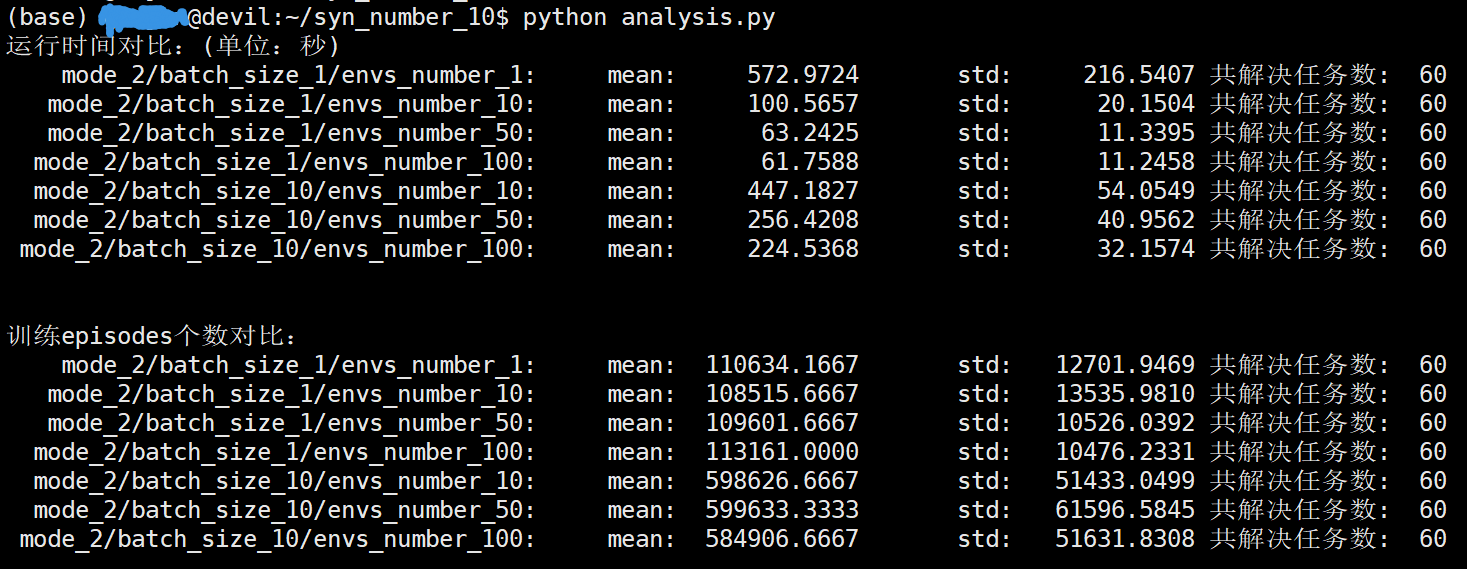
mode=2 与 mode=0 的区别是多了一个syn_number的变量设置,syn_number是指更新策略网络时并不是根据数据生成进程的batch_size个数据来更新,而是使用syn_number*batch_size个数据(episodes数)来进行网络更新。
下面的进程数设置为20, syn_number设置为10。
/home/devilmaycry/anaconda3/envs/tf-14.0/bin/python -u /home/guojun/syn_number_10/analysis.py
运行时间对比:(单位:秒)
mode_2/batch_size_1/envs_number_1: mean: 572.9724 std: 216.5407 共解决任务数: 60
mode_2/batch_size_1/envs_number_10: mean: 100.5657 std: 20.1504 共解决任务数: 60
mode_2/batch_size_1/envs_number_50: mean: 63.2425 std: 11.3395 共解决任务数: 60
mode_2/batch_size_1/envs_number_100: mean: 61.7588 std: 11.2458 共解决任务数: 60
mode_2/batch_size_10/envs_number_10: mean: 447.1827 std: 54.0549 共解决任务数: 60
mode_2/batch_size_10/envs_number_50: mean: 256.4208 std: 40.9562 共解决任务数: 60
mode_2/batch_size_10/envs_number_100: mean: 224.5368 std: 32.1574 共解决任务数: 60 训练episodes个数对比:
mode_2/batch_size_1/envs_number_1: mean: 110634.1667 std: 12701.9469 共解决任务数: 60
mode_2/batch_size_1/envs_number_10: mean: 108515.6667 std: 13535.9810 共解决任务数: 60
mode_2/batch_size_1/envs_number_50: mean: 109601.6667 std: 10526.0392 共解决任务数: 60
mode_2/batch_size_1/envs_number_100: mean: 113161.0000 std: 10476.2331 共解决任务数: 60
mode_2/batch_size_10/envs_number_10: mean: 598626.6667 std: 51433.0499 共解决任务数: 60
mode_2/batch_size_10/envs_number_50: mean: 599633.3333 std: 61596.5845 共解决任务数: 60
mode_2/batch_size_10/envs_number_100: mean: 584906.6667 std: 51631.8308 共解决任务数: 60
考虑到运算时间过久,每个试验设置只重复了60次。
可以看到mode=0时,batch_size的大小如果等于mode=2时的batch_size*syn_number,那么所需要进行的迭代计算测试是相同的。
==================================================
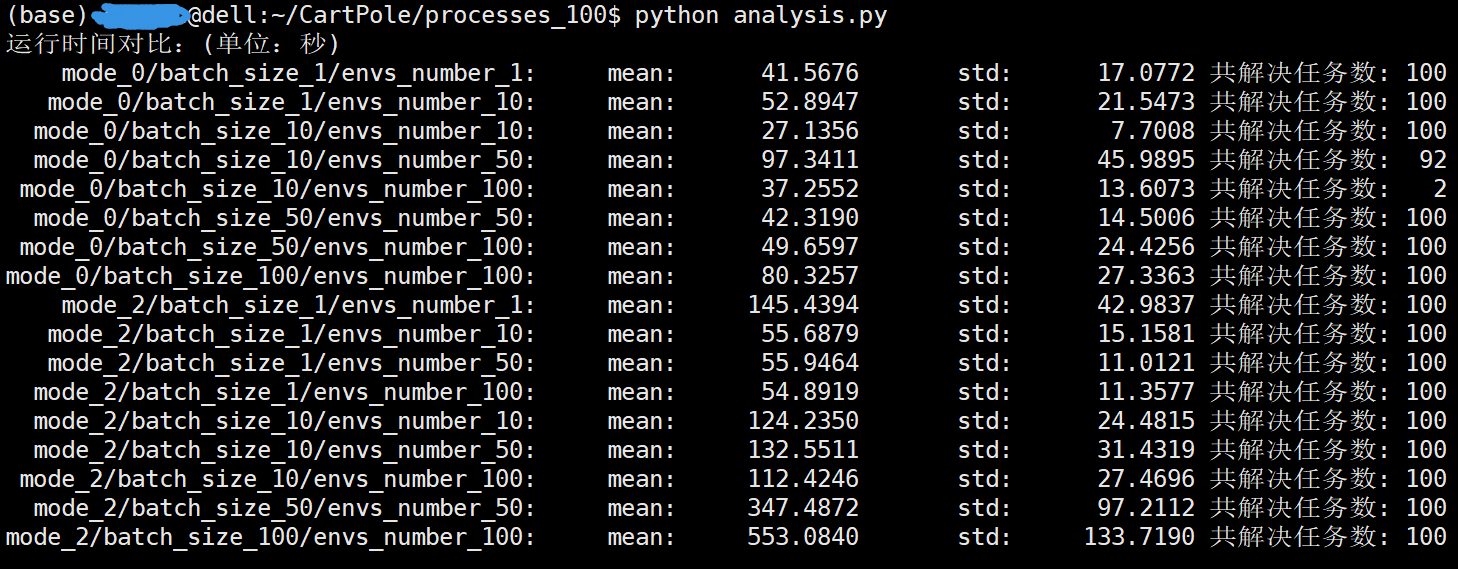
在服务器上同样进行测试(48核心CPU,96线程)
需要说明的是
mode_0/batch_size_10/envs_number_100 设置的情况下只进行了12次,其中只有2次没有退化取得了收敛成功解决任务。
其他设置的情况下均进行了100次测试。进程数为100。mode=2时syn_number=10。
@dell:~/CartPole/processes_100$ python analysis.py
运行时间对比:(单位:秒)
mode_0/batch_size_1/envs_number_1: mean: 41.5676 std: 17.0772 共解决任务数: 100
mode_0/batch_size_1/envs_number_10: mean: 52.8947 std: 21.5473 共解决任务数: 100
mode_0/batch_size_10/envs_number_10: mean: 27.1356 std: 7.7008 共解决任务数: 100
mode_0/batch_size_10/envs_number_50: mean: 97.3411 std: 45.9895 共解决任务数: 92
mode_0/batch_size_10/envs_number_100: mean: 37.2552 std: 13.6073 共解决任务数: 2
mode_0/batch_size_50/envs_number_50: mean: 42.3190 std: 14.5006 共解决任务数: 100
mode_0/batch_size_50/envs_number_100: mean: 49.6597 std: 24.4256 共解决任务数: 100
mode_0/batch_size_100/envs_number_100: mean: 80.3257 std: 27.3363 共解决任务数: 100
mode_2/batch_size_1/envs_number_1: mean: 145.4394 std: 42.9837 共解决任务数: 100
mode_2/batch_size_1/envs_number_10: mean: 55.6879 std: 15.1581 共解决任务数: 100
mode_2/batch_size_1/envs_number_50: mean: 55.9464 std: 11.0121 共解决任务数: 100
mode_2/batch_size_1/envs_number_100: mean: 54.8919 std: 11.3577 共解决任务数: 100
mode_2/batch_size_10/envs_number_10: mean: 124.2350 std: 24.4815 共解决任务数: 100
mode_2/batch_size_10/envs_number_50: mean: 132.5511 std: 31.4319 共解决任务数: 100
mode_2/batch_size_10/envs_number_100: mean: 112.4246 std: 27.4696 共解决任务数: 100
mode_2/batch_size_50/envs_number_50: mean: 347.4872 std: 97.2112 共解决任务数: 100
mode_2/batch_size_100/envs_number_100: mean: 553.0840 std: 133.7190 共解决任务数: 100 训练episodes个数对比:
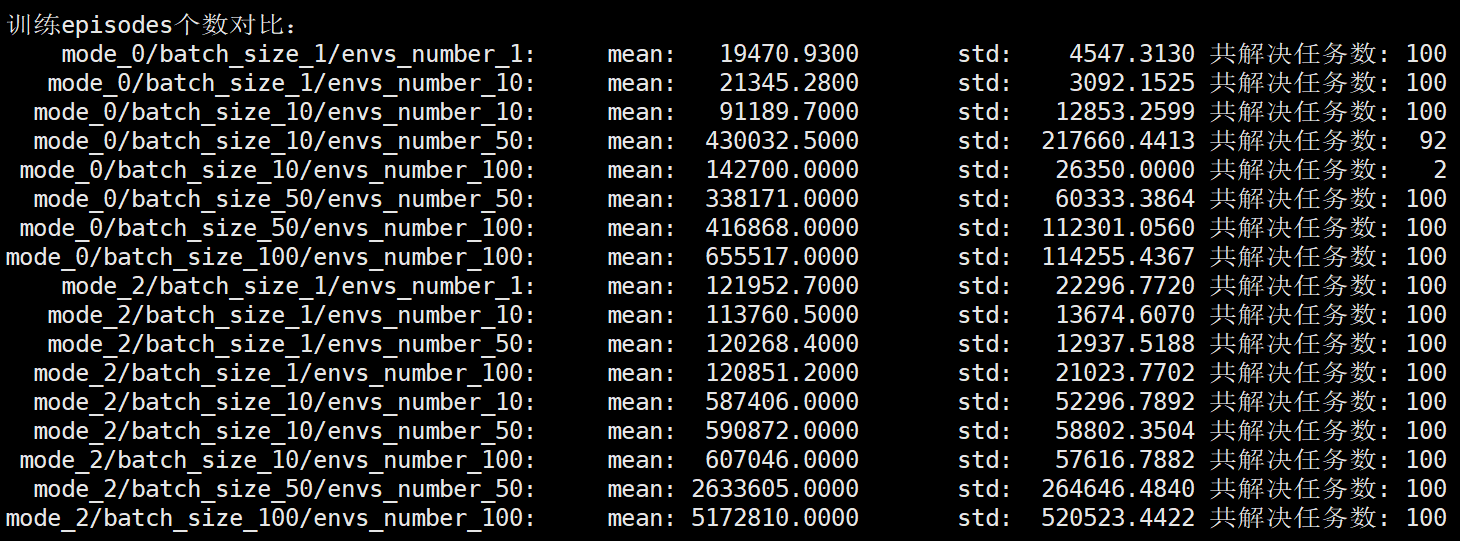
mode_0/batch_size_1/envs_number_1: mean: 19470.9300 std: 4547.3130 共解决任务数: 100
mode_0/batch_size_1/envs_number_10: mean: 21345.2800 std: 3092.1525 共解决任务数: 100
mode_0/batch_size_10/envs_number_10: mean: 91189.7000 std: 12853.2599 共解决任务数: 100
mode_0/batch_size_10/envs_number_50: mean: 430032.5000 std: 217660.4413 共解决任务数: 92
mode_0/batch_size_10/envs_number_100: mean: 142700.0000 std: 26350.0000 共解决任务数: 2
mode_0/batch_size_50/envs_number_50: mean: 338171.0000 std: 60333.3864 共解决任务数: 100
mode_0/batch_size_50/envs_number_100: mean: 416868.0000 std: 112301.0560 共解决任务数: 100
mode_0/batch_size_100/envs_number_100: mean: 655517.0000 std: 114255.4367 共解决任务数: 100
mode_2/batch_size_1/envs_number_1: mean: 121952.7000 std: 22296.7720 共解决任务数: 100
mode_2/batch_size_1/envs_number_10: mean: 113760.5000 std: 13674.6070 共解决任务数: 100
mode_2/batch_size_1/envs_number_50: mean: 120268.4000 std: 12937.5188 共解决任务数: 100
mode_2/batch_size_1/envs_number_100: mean: 120851.2000 std: 21023.7702 共解决任务数: 100
mode_2/batch_size_10/envs_number_10: mean: 587406.0000 std: 52296.7892 共解决任务数: 100
mode_2/batch_size_10/envs_number_50: mean: 590872.0000 std: 58802.3504 共解决任务数: 100
mode_2/batch_size_10/envs_number_100: mean: 607046.0000 std: 57616.7882 共解决任务数: 100
mode_2/batch_size_50/envs_number_50: mean: 2633605.0000 std: 264646.4840 共解决任务数: 100
mode_2/batch_size_100/envs_number_100: mean: 5172810.0000 std: 520523.4422 共解决任务数: 100
可以看到进程数为100时对算法性能提升(运算时间的缩短)并没有很明显,同时发现环境数的设置对运行时间(迭代更新次数)影响关系不确定(环境数过大导致训练数据与当前训练策略分布差距过大,训练陷入退化中),不过环境数设置过大对性能没有太多好处,尤其对于mode=0的情况下,batch_size等于环境数envs_number在提升算法性能的同时又能很好的保证算法稳定性,因此对于mode=0的情况下建议使用batch_size=envs_number的设置。
可以看到,当环境数envs_number远大于batch_size时,mode=2可以很好的避免算法退化,这一点要优于mode=0,不过对于mode=0,我们可以通过减少envs_number与batch_size的大小的差距,也或者使用batch_size=envs_number的设置,同样可以使mode=0得到很好的性能,因此综合考虑,还是建议使用batch_size=envs_number的设置下的mode=0算法。
-------------------------------------------------------------------
并行化强化学习 —— 最终版本 —— 并行reinforce算法的尝试的更多相关文章
- 强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)
强化学习策略梯度方法之: REINFORCE 算法 (从原理到代码实现) 2018-04-01 15:15:42 最近在看policy gradient algorithm, 其中一种比较经典的 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用.可以将Q-Table的更新问题变成 ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- <强化学习>开门帖
(本系列只用作本人笔记,如果看官是以新手开始学习RL,不建议看我写的笔记昂) 今天是2020年2月7日,开始二刷david silver ulc课程.https://www.youtube.com/w ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 机器学习&深度学习基础(tensorflow版本实现的算法概述0)
tensorflow集成和实现了各种机器学习基础的算法,可以直接调用. 代码集:https://github.com/ageron/handson-ml 监督学习 1)决策树(Decision Tre ...
- 【算法总结】强化学习部分基础算法总结(Q-learning DQN PG AC DDPG TD3)
总结回顾一下近期学习的RL算法,并给部分实现算法整理了流程图.贴了代码. 1. value-based 基于价值的算法 基于价值算法是通过对agent所属的environment的状态或者状态动作对进 ...
随机推荐
- .NET5 IIS ASP.NET CORE 部署时 HTTP Error 502.5 - ANCM Out-Of-Process Startup Failure
.NET5 IIS ASP.NET CORE 部署时 HTTP Error 502.5 - ANCM Out-Of-Process Startup Failure 部署机器只安装了dotnet-hos ...
- 搭建第一个web项目
实现使用: 1.创建一个普通java文件 2.Java文件的类名实现HttpServlet 3.重写service方法 4.在WEB-INF下的web.xml中添加请求与servlet类的映射关系 定 ...
- hive第三课:Hive函数学习
Hive函数学习 目录 Hive函数学习 SQL练习 Hive 常用函数 关系运算 数值计算 条件函数(主要使用场景是数据清洗的过程中使用,有些构建表的过程也是需要的) 日期函数重点!!! 字符串函数 ...
- 实测52.4MB/s!全国产ARM+FPGA的CSI通信案例分享!
CSI总线介绍与优势 CSI(CMOS sensor parallel interfaces)总线是一种用于连接图像传感器和处理器的并行通信接口,应用于工业自动化.能源电力.智慧医疗等领域,CSI总线 ...
- 【Python】python笔记:时间模块/时间函数
1.Python时间模块 import time import datetime # 一: time模块 ############## # 1.时间戳 print (time.time()) # 16 ...
- VulnHub-Narak靶机渗透流程
VulnHub-Narak Description Narak is the Hindu equivalent of Hell. You are in the pit with the Lord of ...
- JavaScript --函数--手稿
- Vue3 如何接入 i18n 实现国际化多语言
1. 基本方法 在 Vue.js 3 中实现网页的国际化多语言,最常用的包是 vue-i18n,通常我们会与 vue-i18n-routing 一起使用. vue-i18n 负责根据当前页面的语言渲染 ...
- Linux-Cgroup V2 初体验
本文主要记录 Linux Cgroup V2 版本基本使用操作,包括 cpu.memory 子系统演示. 1. 开启 Cgroup V2 版本检查 通过下面这条命令来查看当前系统使用的 Cgroups ...
- Solo 开发者周刊 (第8期):Claude公司再度上新产品,成交额将超73亿美元
这里会整合 Solo 社区每周推广内容.产品模块或活动投稿,每周五发布.在这期周刊中,我们将深入探讨开源软件产品的开发旅程,分享来自一线独立开发者的经验和见解.本杂志开源,欢迎投稿. 好文推荐 Cla ...