ScanFormer:逐层抵达目标,基于特征金字塔的指代表达理解框架 | CVPR'24
指代表达理解(
REC)旨在在图像中定位由自由形式自然语言描述指定的目标对象。尽管最先进的方法取得了令人印象深刻的性能,但它们对图像进行了密集感知,包含与语言查询无关的多余视觉区域,导致额外的计算开销。这启发论文探讨一个问题:能否消除与语言无关的多余视觉区域,以提高模型的效率?现有的相关方法主要侧重于基本的视觉任务,在视觉语言领域的探索有限。为了解决这一问题,论文提出了一个称为ScanFormer的粗到细的迭代感知框架。该框架逐层利用图像尺度金字塔,从上到下提取与语言相关的视觉图像块。在每次迭代中,通过设计的信息预测方法丢弃不相关的图像块。此外,论文提出了一个用于加速推断的被丢弃图像块的选择策略。在广泛使用的数据集RefCOCO、RefCOCO+、RefCOCOg和ReferItGame上的实验证明了该框架有效性,可以在准确性和效率之间取得平衡。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: ScanFormer: Referring Expression Comprehension by Iteratively Scanning

Introduction
作为视觉语言理解中的基本任务,指代表达理解(REC)依赖于自由形式的自然语言描述来识别所指对象。REC的发展不仅可以支撑各种视觉语言任务,还有可能有助于实际应用,如人机交互。
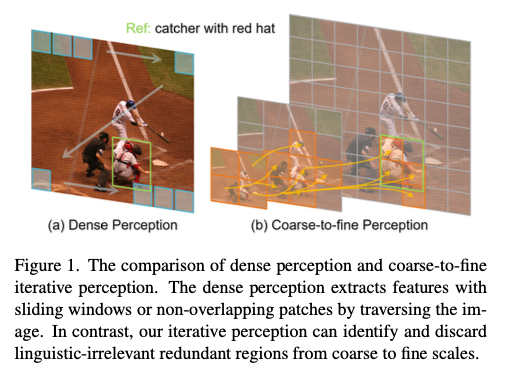
在指代表达理解(REC)中,与高度简洁和信息密集的语言查询形成对比的是,图像通常包含大量冗余信息。例如,如图1所示,图像中存在大量与语言查询弱相关甚至不相关的冗余视觉区域,例如目标捕手周围的人物以及大面积的低信息背景区域。然而,最先进的方法采用密集感知形式来获取用于后续跨模态交互的视觉特征。这些方法使用诸如ResNet、DarkNet、Swin Transformer等的视觉编码器,并使用滑动窗口或非重叠图像块遍历图像的所有空间位置以提取特征,如图1(a)所示。尽管取得了令人印象深刻的性能,但密集感知的形式带来大量冗余信息,并增加了整个模型的计算开销。特别是在基于Transformer的模型中,多头自注意力的计算复杂度是二次的。这引出一个研究问题:是否可能丢弃与语言无关的冗余视觉区域,以提升模型的效率?
值得注意的是,目前出现了一种探索消除冗余视觉特征的新趋势。典型的自下而上融合方法最初将图像分割成细粒度图像块,并逐渐在后续多个阶段中合并这些图像块以减少视觉标记。然而,初始标记的丰富性不可避免地导致了早期阶段的巨大计算成本,特别是在处理高分辨率图像时。此外,自上而下的粗到细方法从粗粒度分割开始,使用大的图像块尺寸,并逐渐减小图像块尺寸以获取细粒度的视觉标记。例如,DVT级联多个Transformer,并利用高置信预测来确定是否使用较小的图像块尺寸将整个图像划分为更细粒度的图像块。然而,这种方法通常会带来大量冗余的视觉区域,并增加计算开销。CF-ViT引入了一个粗到细的两阶段视觉Transformer,该模型在粗阶段识别信息丰富的图像块,并在第二阶段进一步将它们重新分割为更细的图像块。尽管在分类任务中表现出色,但基于类别注意力的启发式信息丰富区域识别限制了其扩展以及在没有[CLS]标记的情况下的建模。此外,由于它是非可学习的,应用正则化来控制标记的稀疏性是具有挑战性的。因此,现有的高效Transformer方法仍然存在局限性,并侧重于视觉任务,而忽视了对视觉语言领域的探索。
为了解决这个问题,论文提出了一种粗到细的迭代感知框架,称为ScanFormer,如图1(b)所示。具体而言,利用预构建的图像尺度金字塔,模型从金字塔顶部的粗粒度低分辨率图像开始进行视觉感知。通过预测下一次迭代中更细粒度图像块的信息量,模型自适应地消除冗余的视觉区域,最终达到金字塔底部的细粒度高分辨率图像。此外,通过将先前的标记保留在缓存中而不进行进一步的更新(KVCache),从而减少计算资源。在每次迭代中提取的新标记,通过自注意力和交叉注意力分别与自身和缓存中包含的先前标记交互。在这个过程中,多尺度图像块分区使模型能够从不同空间位置聚合与尺度相关的信息。此外,论文提出了一种针对被丢弃图像块的图像块选择策略以加速推理。一个可学习的标记参与粗到细的迭代感知过程,并最终用于坐标回归,直接预测目标框。大量实验证明了ScanFormer的有效性,在广泛使用的数据集上取得了最先进的方法,即RefCOCO,RefCOCO+,RefCOCOg和ReferItGame。
主要贡献可以总结如下:
提出了
ScanFormer,这是一个粗到细的迭代感知框架,每次迭代逐渐丢弃与语言无关的冗余视觉区域,以增强模型的效率。为了实现图像块选择,提出通过常数标记替换来选择标记,其中未被选中的标记将被常数标记替换,最终合并以真正加速处理。
广泛的实验证明了
ScanFormer的有效性,与最先进的方法相比,在准确性和效率之间取得了平衡。
Method
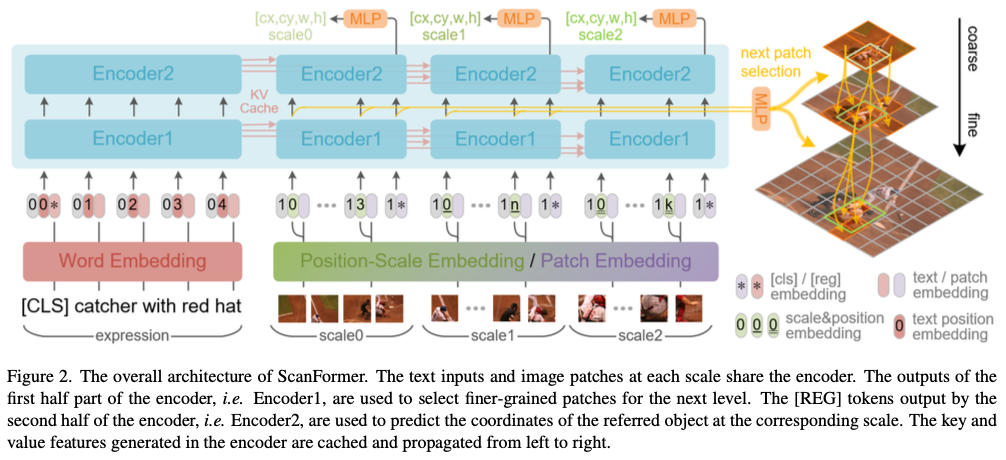
Framework
ScanFormer利用一种统一的类Transformer结构,用于语言和视觉模态,如图2所示。具体地,该框架由词嵌入、图像块嵌入、位置-尺度嵌入和编码器组成。词嵌入和图像块嵌入分别从文本和图像中提取特征。位置-尺度嵌入用于编码每个图像图像块的空间位置和尺度大小。编码器由N个层组成,每个层包括一个多头注意力(MHA)层和一个前馈网络(FFN)。
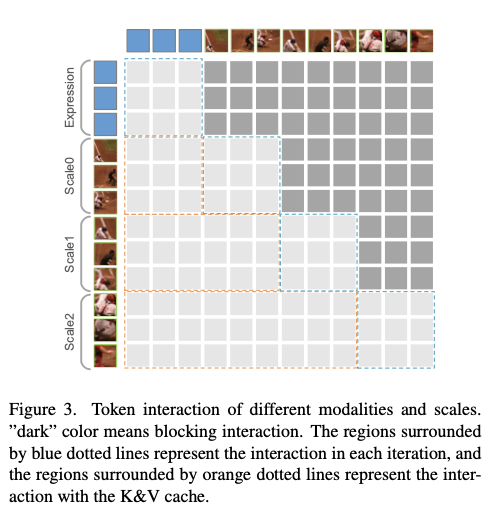
此外,每个编码器层都配备有一个缓存来存储输出特征。MHA的查询来自输入特征,而键和值由输入特征和先前缓存特征组成,如图3所示。尺度上的因果性不仅减少了计算量,还利用了先前的语言和多尺度视觉信息来更新特征。
语言模态的输入首先由该框架进行编码,并提取的语言特征被存储在缓存中。随后,对于视觉模态,基于输入图像 \(I\) 构建了一个包含 \(S\) 个尺度的图像尺度金字塔。自顶向下,对于每次迭代,选择的图像块被提取并通过框架进行处理,中间特征用于生成下一个金字塔层中子图像块的选择。此外,每个编码器层的缓存存储每次迭代后获得的视觉特征。每次迭代中与[REG]标记对应的特征用于预测对应尺度上指代对象的坐标。对于金字塔顶部的图像,选择所有图像块以确保模型捕获全局信息。随着尺度的增加,ScanFormer融合了更精细的特征以实现准确的预测,同时丢弃不相关的图像块以节省大量计算资源。
具体而言,对于语言模态,指代文本 \(t\in\mathbb{R}^{L\times|V|}\) 被嵌入到词嵌入矩阵 \(T\in\mathbb{R}^{|V|\times d}\) 中,前置[CLS]嵌入 \(T^{cls}\in\mathbb{R}^d\) ,然后与文本位置嵌入矩阵 \(T^{pos}\in\mathbb{R}^{(L+1)\times d}\) 和类型嵌入 \(T^{type}\in\mathbb{R}^d\) 相加。嵌入的语言特征首先被送入框架中,更新后的语言特征将存储在编码器每层的缓存中。对于视觉模态,在图像尺度金字塔的自顶向下,以第 \(i\) 层为例,首先从具有 \((P, P)\) 分辨率和 \(C\) 通道的 \(N_i\) 个选择的图像块被平铺为 \(v\in\mathbb{R}^{N_i\times (P^2\cdot C)}\) ,然后通过线性投影层投影到 \(E\in\mathbb{R}^{N_i \times d}\) 。之后,图像块特征与空间嵌入 \(E^{spatial}\in\mathbb{R}^{N_i\times d}\) 和类型嵌入 \(E^{type}\in\mathbb{R}^d\) 相加。 \(E^{spatial}\) 由位置-尺度嵌入 \(PSE: [0,1]^3 \rightarrow \mathbb{R}^d\) 生成,使用规范化的图像块坐标和尺度 \([cx, cy, s]\) 作为输入。之后,附加[REG]标记的嵌入 \(E^{reg}\in\mathbb{R}^d\) 用于回归第 \(i\) 层对象的边界框 \([cx_i, cy_i, w_i, h_i]\) 。
Patch Selection by Constant Replacement
为了通过反向传播学习选择信息图像块,为第 \(i\) 个图像块生成了选择因子 \(s_i\) 。关于如何使用 \(s_i\) 有两个选择:(1)将 \(s_i\) 应用于每个Transformer层上MHA的每个头,通过对键和值进行加权实现。逐渐将 \(s_i\) 衰减为 \(0.0\) ,以最小化其对其余标记的影响。然而,对于具有 \(N\) 层和 \(H\) 头的Transformer,获得清晰的梯度信号以优化 \(s_i\) 是具有挑战性的,使得难以实现理想的学习选择。(2)将 \(s_i\) 直接加权地应用于Transformer的输入,即图像块嵌入。由于 \(s_i\) 仅在此位置使用,因此更容易训练。因此,本文采用了第二种选择。
此外,值得注意的是,即使将输入图像块嵌入设置为零,由于FFN和MHA的偏置项以及点积注意力,它在后续层中仍会变为非零。幸运的是,当标记序列包含许多相同的标记时,MHA的计算可以被简化,从而实现实际推理加速。为了提高模型的适应性,论文建议将图像块嵌入替换为可学习的常数标记,而不是直接将其设置为零。因此,图像块选择问题被转化为图像块替换问题。
Constant Token Replacement
为了实现标记替换,引入了一个常数标记 \(E^{const}\in\mathbb{R}^d\) ,并从Transformer中产生第 \(i\) 个图像块的选择值 \(r_i\in \mathbb{R}\) 。遵循改进的语义哈希方法,通过反向传播学习 \(r_i\) 。为了鼓励探索,将噪声添加到 \(r_i\) 中,即 \(r_i^n=r_i+n\) 。在训练过程中, \(n\sim \mathcal{N}(0,1)\) ,而在评估和推断时 \(n=0\) 。然后,计算两个变量 \(v_1=\sigma{'}(r_i^n)\) 和 \(v_2=\mathbb{I}(r_i^n\geq 0)\) 。
\sigma{'}(x) = clamp(1.2\sigma(x)-0.1, 0, 1),
\end{equation}
\]
其中, \(\mathbb{I}(\cdot)\) 和 \(\sigma(\cdot)\) 分别为指示函数和 \(sigmoid\) 函数。在训练过程中,在前向传播中,均匀抽样 \(v_1\) 和 \(v_2\) 作为选择因子 \(s_i\) 。
\label{equ:select}
s_i = \mathbb{I}(n_s\geq0.5)\cdot v_1 +\mathbb{I}(n_s < 0.5)\cdot v_2,
\end{equation}
\]
这里, \(n_s\sim Uniform[0, 1]\) 表示随机采样权重。在反向传播中,梯度始终流向 \(v_1\) ,即使在前向计算中使用了 \(v_2\) 。加权图像块嵌入 \(\overline{E}_i\) 计算如下:
\overline{E}_i = s_i\cdot E_i + (1-s_i)\cdot E^{const}.
\end{equation}
\]
在训练过程中, \(s_i\) 被规范化为 \(0\) ,即第 \(i\) 个标记被常量标记 \(E^{const}\) 替换。
Merging Constant Tokens

尽管冗余标记被常量标记替换后仍然包含在编码器的前向计算中,但它们不能直接被丢弃而不产生任何影响。然而,这些常量标记可以合并以有效减少计算量。对于一个包含 \(N\) 个标记和 \(N_c\) 个常量标记的键和值序列:
\label{equ:orig_kv}
\begin{split}
&K=[\underbrace{k_1, k_2, \cdots, k_i}_{N-N_c}, \underbrace{k^c,\cdots, k^c}_{N_c}] \\
&V=[\underbrace{v_1, v_2, \cdots, v_i}_{N-N_c}, \underbrace{v^c,\cdots, v^c}_{N_c}]
\end{split}
\end{equation}
\]
通过将一个常量向量连接到键上, \(N_c\) 个标记的键和值可以减少到仅一个键和一个值,这可以通过以下方式来说明:
\label{equ:merge_kv}
\begin{split}
&K^{'}=concat([\underbrace{k_1, k_2, \cdots, k_i}_{N-N_c}, k^c], [\underbrace{0, 0, \cdots, 0}_{N-N_c}, log(N_c)]) \\
&V^{'}=[\underbrace{v_1, v_2, \cdots, v_i}_{N-N_c}, v^c]
\end{split}
\end{equation}
\]
根据缩放点积注意力机制,相对于 \(K\) 的一个查询 \(q\in\mathbb{R}^{d}\) 的注意力值 \(A\in\mathbb{R}^{N}\) 可以计算为:
\label{equ:attn}
A = softmax(\frac{qK^T}{\sqrt{d}}).
\end{equation}
\]
根据公式4和公式5,可以得出同样的注意力加权值,如公式6所示。因此, \(N_c-1\) 个标记最终被丢弃,由它们带来的计算可以节省。
Prediction Head
被指代的对象可能存在于各种尺度上。类似于目标检测方法,其中在不同特征级别进行多尺度预测。对于ScanFormer中的每个尺度级别,应用直接坐标回归来预测被指代对象的边界框,通过回归标记[REG]来搜集Transformer中图像图像块的特征。与[REG]标记对应的输出特征被馈送到共享的多层感知器(MLP),随后使用Sigmoid函数来预测被引用对象的归一化边界框 \(\hat{b}=(\hat{x},\hat{y},\hat{w},\hat{h})\) 。
Training Objectives
通过端到端的方式优化所提出的粗到细的迭代感知框架。对于第 \(l\) 个图像尺度,可以获得预测的边界框 \(\hat{b}_l=(\hat{x}_l,\hat{y}_l,\hat{w}_l,\hat{h}_l)\) 。给定真实边界框 \(b=(x,y,w,h)\) ,检测损失函数定义如下:
\label{equ:loss_bbox}
\mathcal{L}_{bbox} = \sum_{l=0}^{2} \lambda_{L1}^l\mathcal{L}_{L1}(b,\hat{b}_l) + \sum_{l=0}^{2} \lambda_{giou}^l\mathcal{L}_{giou}^l(b,\hat{b}_l),
\end{equation}
\]
其中, \(\mathcal{L}_{L1}(\cdot,\cdot)\) 和 \(\mathcal{L}_{giou}(\cdot,\cdot)\) 分别代表L1损失和广义IoU损失,而 \(\lambda_{L1}^l\) 和 \(\lambda_{giou}^l\) 分别是相对权重,用于控制第 \(l\) 个图像尺度上的检测损失惩罚。
此外,为了控制所选图像块的稀疏性,添加正则化损失函数如下:
\label{equ:loss_sparse}
\mathcal{L}_{sparse} = \lambda_{sparse}\sum_{l=1}^{2}(\frac{1}{N_l}\sum_{i=1}^{N_l}s_i^l-\beta^l)^2,
\end{equation}
\]
其中, \(\lambda_{sparse}\) 代表相对权重,用于控制稀疏性惩罚, \(s_i^l\) 代表第 \(l\) 个图像尺度中公式2中的第 \(i\) 个图像块的选择因子。 \(\beta^l\) 是用于控制从第 \(l\) 个图像尺度选择的标记比例的超参数。
ScanFormer的总损失函数定义如下:
\mathcal{L}_{total} = \mathcal{L}_{bbox} + \mathcal{L}_{sparse},
\end{equation}
\]
经过训练的ScanFormer可以在准确性和效率之间取得平衡。
Experiment

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

ScanFormer:逐层抵达目标,基于特征金字塔的指代表达理解框架 | CVPR'24的更多相关文章
- [OpenCV]基于特征匹配的实时平面目标检测算法
一直想基于传统图像匹配方式做一个融合Demo,也算是对上个阶段学习的一个总结. 由此,便采购了一个摄像头,在此基础上做了实时检测平面目标的特征匹配算法. 代码如下: # coding: utf-8 ' ...
- SPPNet(特征金字塔池化)学习笔记
SPPNet paper:Spatial pyramid pooling in deep convolutional networks for visual recognition code 首先介绍 ...
- 特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更 ...
- 常见特征金字塔网络FPN及变体
好久没有写文章了(对不起我在划水),最近在看北京的租房(真真贵呀). 预告一下,最近无事,根据个人多年的证券操作策略和自己的浅显的AI时间序列的算法知识,还有自己Javascript的现学现卖,在微信 ...
- DNS通道检测 国内学术界研究情况——研究方法:基于特征或者流量,使用机器学习决策树分类算法居多
http://xuewen.cnki.net/DownloadArticle.aspx?filename=BMKJ201104017&dbtype=CJFD<浅析基于DNS协议的隐蔽通道 ...
- [OpenCV实战]19 使用OpenCV实现基于特征的图像对齐
目录 1 背景 1.1 什么是图像对齐或图像对准? 1.2 图像对齐的应用 1.3 图像对齐基础理论 1.4 如何找到对应点 2 OpenCV的图像对齐 2.1 基于特征的图像对齐的步骤 2.2 代码 ...
- SaccadeNet:使用角点特征进行two-stage预测框精调 | CVPR 2020
SaccadeNet基于中心点特征进行初步的目标定位,然后利用初步预测框的角点特征以及中心点特征进行预测框的精调,整体思想类似于two-stage目标检测算法,将第二阶段的预测框精调用的区域特征转化为 ...
- 基于深度学习的中文语音识别系统框架(pluse)
目录 声学模型 GRU-CTC DFCNN DFSMN 语言模型 n-gram CBHG 数据集 本文搭建一个完整的中文语音识别系统,包括声学模型和语言模型,能够将输入的音频信号识别为汉字. 声学模型 ...
- 基于SpringBoot的Environment源码理解实现分散配置
前提 org.springframework.core.env.Environment是当前应用运行环境的公开接口,主要包括应用程序运行环境的两个关键方面:配置文件(profiles)和属性.Envi ...
- 基于事件驱动的DDD领域驱动设计框架分享(附源代码)
原文:基于事件驱动的DDD领域驱动设计框架分享(附源代码) 补充:现在再回过头来看这篇文章,感觉当初自己偏激了,呵呵.不过没有以前的我,怎么会有现在的我和现在的enode框架呢?发现自己进步了真好! ...
随机推荐
- [oeasy]python0012_字符_character_chr函数_根据序号得到字符
字符(character) 回忆上次内容 上次了解了ord函数 这个函数可以通过字符得到序号 那么可以反过来吗? 通过序号得到字符可以吗? 编辑 ord的逆运算chr 有来就有回 编辑 好 ...
- python_xecel
移动并重命名工作簿 1 from pathlib import Path # 导入pathlib模块的path类 2 import time 3 4 # Press the green button ...
- 加油,为Vue3提供一个可媲美Angular的ioc容器
为什么要为Vue3提供ioc容器 Vue3因其出色的响应式系统,以及便利的功能特性,完全胜任大型业务系统的开发.但是,我们不仅要能做到,而且要做得更好.大型业务系统的关键就是解耦合,从而减缓shi山代 ...
- 在Python中使用sqlalchemy来操作数据库的几个小总结
在探索使用 FastAPI, SQLAlchemy, Pydantic,Redis, JWT 构建的项目的时候,其中数据库访问采用SQLAlchemy,并采用异步方式.数据库操作和控制器操作,采用基类 ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-62 - 判断元素是否可操作
1.简介 有些页面元素的生命周期如同流星一闪,昙花一现.我们也不知道这个元素在没在页面中出现过,为了捕获这一美好瞬间,让其成为永恒.我们就来判断元素是否显示出现过. 在操作元素之前,可以先判断元素的状 ...
- Apache COC闪电演讲总结【OSGraph】
大家能看到我最近一直在折腾与OSGraph这个产品相关的事情,之前在文章<妙用OSGraph:发掘GitHub知识图谱上的开源故事>中向大家阐述过这个产品的设计理念和应用价值.比方说以下问 ...
- 【微信小程序】 使用NPM包与VantWeapp
小程序对npm的支持与限制 目前,小程序中已经支持使用npm安装第三方包,从而来提高小程序的开发效率. 但是,在小程序中使用npm包有如下3个限制: ① 不支持依赖于Node.js内置库的包② 不支持 ...
- 【Server - 运维】更改腾讯云数据库参数设置
购买的MySQL实例是一个屏蔽了后台设置的服务器: 默认大小写设置是使用严格区分的: 要设置忽略大小写,就要在my.cnf中更改配置参数 https://cloud.tencent.com/devel ...
- 【IDEA】转大小写快速操作
需求场景: 快速修改一些字符全部变成大写,或者小写 例如修改SQL语句,部分字段大写,部分字段小写,需要统一 快捷键: [Ctrl + Shift + U] 演示案例: SELECT ( (SELEC ...
- 【Spring】09 后续的学习补充 vol3
原生JDBC事务: package dao; import cn.dzz.util.DruidUtil; import org.apache.commons.dbutils.QueryRunner; ...