爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录:
在爬虫系列文章 优雅的HTTP库requests 中介绍了 requests 的使用方式,这一次我们用 requests 构建一个知乎 API,功能包括:私信发送、文章点赞、用户关注等,因为任何涉及用户操作的功能都需要登录后才操作,所以在阅读这篇文章前建议先了解Python模拟知乎登录。现在假设你已经知道如何用 requests 模拟知乎登录了。
思路分析
发送私信的过程就是浏览器向服务器发送一个 HTTP 请求,请求报文包括请求 URL、请求头 Header、还有请求体 Body,只要把这些信息弄清楚,那么就很容易用 requests 来模拟浏览器发送私信了。
打开 Chrome 浏览器,随便找一个用户,点击发送私信,追踪一下私信的网络请求过程。
先看下请求头信息
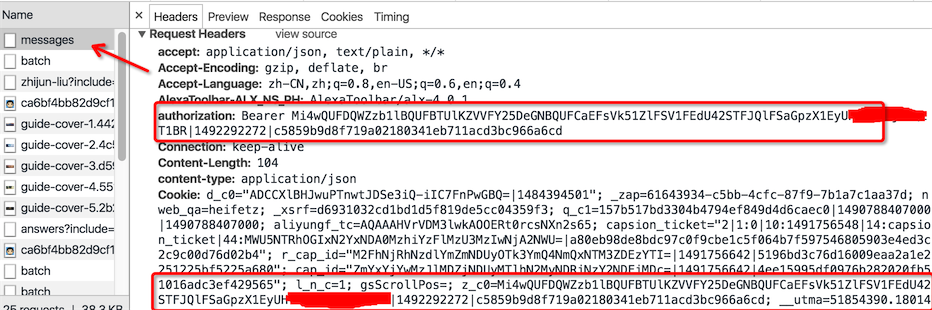
请求头 Header 中有 cookies 登录信息,此外还有一个 authorization 字段,该字段是用于用户认证的,同时这个字段也存在 cookies 中(为了防止 cookie 信息泄露,我打了马赛克), requests 请求时这些信息都必须携带上。
再来看看请求的URL和请求体
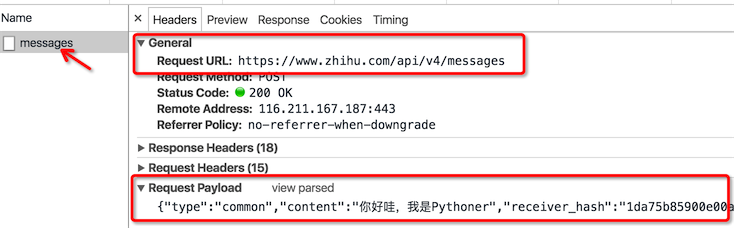
请求URL是 https://www.zhihu.com/api/v4/messages ,请求方法是 POST,请求体
{"type":"common","content":"你好,我是pythoner","receiver_hash":"1da75b85900e00adb072e91c56fd9149"}
请求体是一个 json 字符串,type 和 content 很好理解,但 receiver_hash 是什么并不知道,需要进一步确定,不过你应该猜得出这是类似于用户 id 的字段。
那么现在问题来了,如何通过用户主页的URL找到用户的 id 呢?为了完整的模拟私信的整个流程,我特地注册了一个知乎小号。
如果你手头没有多余的手机号,可以用 Google 搜「receive sms online」,网上很多提供免费在线接收短信的手机号码,我注册的小号主页:https://www.zhihu.com/people/xiaoxiaodouzi
先尝试关注小号,然后在我关注的列表中找到该小号,把鼠标移到小号的头像处时,发现有一个 HTTP 网络请求。
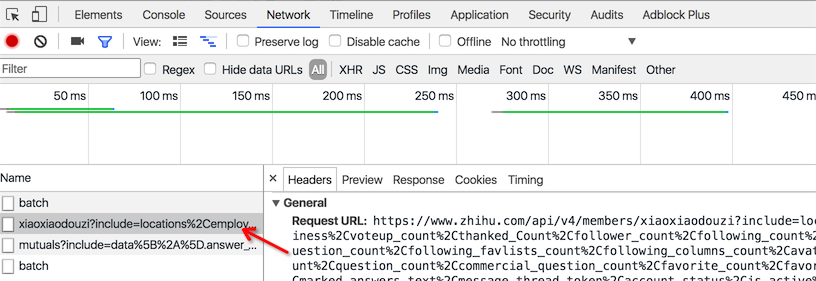
请求 url 是 https://www.zhihu.com/api/v4/members/xiaoxiaodouzi ,这个URL的后面部分「xiaoxiaodouzi」对应小号主页URL的后面部分,这部分我们称之为 url_token。
接口的返回数据是该用户的个人公开信息。
{
...
"id":"1da75b85900e00adb072e91c56fd9149",
"favorite_count":0,
"voteup_count":0,
"commercial_question_count":0,
"url_token":"xiaoxiaodouzi",
"type":"people",
"avatar_url":"https://pic1.zhimg.com/v2-ca13758626bd7367febde704c66249ec_is.jpg",
"is_active":1492224390,
"name":"\u6211\u662f\u5c0f\u53f7",
"url":"http://www.zhihu.com/api/v4/people/1da75b85900e00adb072e91c56fd9149",
"gender":-1
...
}
我们可以很清楚的看到有个id的字段,跟我们之前猜测的一样,私信里面的 receiver_hash 字段就是用户的id。
代码实现
到此我们把私信功能的思路理清楚了,代码实现就是水到渠成的事情了。
用户信息
为了得到私信接口需要的 receiver_hash 字典,我们先要获取用户信息,该信息里面含有用于的id值。
@need_login
def user(self, url_token):
"""
获取用户信息,
:param url_token:
url_token 是用户主页url中后面部分
例如: https://www.zhihu.com/people/xiaoxiaodouzi
url_token 是 xiaoxiaodouzi
:return:dict
"""
response = self._session.get(URL.profile(url_token))
return response.json()
发送私信
@need_login
def send_message(self, user_id, content):
"""
给指定的用户发私信
:param user_id: 用户ID
:param content: 私信内容
"""
data = {"type": "common", "content": content, "receiver_hash": user_id}
response = self._session.post(URL.message(), json=data)
data = response.json()
if data.get("error"):
self.logger.info("私信发送失败, %s" % data.get("error").get("message"))
else:
self.logger.info("发送成功")
return data
上面两个方法放在一个叫Zhihu的类里面,我只列出了关键代码,涉及到的 @need_login 是一个用户认证的装饰器,表示该方法需要登录后才能操作。细心的你可能发现,每个请求中我并没有显示地指定 Header 字段,那时因为我把它放在 __init__.py 方法中初始化了。
def __init__(self):
self._session = requests.session()
self._session.verify = False
self._session.headers = {"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/56.0.2924.87',
}
self._session.cookies = cookiejar.LWPCookieJar(filename=cookie_filename)
try:
self._session.cookies.load(ignore_discard=True)
except:
pass
调用执行
from zhihu import Zhihu if __name__ == '__main__':
zhihu = Zhihu()
profile = zhihu.user("xiaoxiaodouzi")
_id = profile.get("id")
zhihu.send_message(_id, "你好,这是来自Python之禅的问候")
执行完成后,小号成功收到我发送的私信。

最后,我们可以按照类似的思路把关注用户,点赞等功能实现了。源码地址:https://github.com/lzjun567/zhihu-api,欢迎大家 Fork 贡献代码,一起完善。
爬虫入门系列(三):用 requests 构建知乎 API的更多相关文章
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- C# 互操作性入门系列(三):平台调用中的数据封送处理
好文章搬用工模式启动ing ..... { 文章中已经包含了原文链接 就不再次粘贴了 言明 改文章是一个系列,但只收录了2篇,原因是 够用了 } --------------------------- ...
- [转]C# 互操作性入门系列(三):平台调用中的数据封送处理
参考网址:https://www.cnblogs.com/FongLuo/p/4512738.html C#互操作系列文章: C# 互操作性入门系列(一):C#中互操作性介绍 C# 互操作性入门系列( ...
- 前端构建大法 Gulp 系列 (三):gulp的4个API 让你成为gulp专家
系列目录 前端构建大法 Gulp 系列 (一):为什么需要前端构建 前端构建大法 Gulp 系列 (二):为什么选择gulp 前端构建大法 Gulp 系列 (三):gulp的4个API 让你成为gul ...
- mybatis入门系列三之类型转换器
mybatis入门系列三之类型转换器 类型转换器介绍 mybatis作为一个ORM框架,要求java中的对象与数据库中的表记录应该对应 因此java类名-数据库表名,java类属性名-数据库表字段名, ...
- Scrapy爬虫入门系列3 将抓取到的数据存入数据库与验证数据有效性
抓取到的item 会被发送到Item Pipeline进行处理 Item Pipeline常用于 cleansing HTML data validating scraped data (checki ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
随机推荐
- 【开源.NET】轻量级内容管理框架Grissom.CMS(第三篇解析配置文件和数据以转换成 sql)
该篇是 Grissom.CMS 框架系列文章的第三篇, 主要介绍框架用到的核心库 EasyJsonToSql, 把标准的配置文件和数据结构解析成可执行的 sql. 该框架能实现自动化增删改查得益于 E ...
- 考试模块 - ERP数据流
快速链接:人力资源知识体系索引 本主题主要列出考试中涉及到的所有表. 步骤 操作 相关表 说明 1 考试辅助资料 基础资料,见附表1 2 题库(109130) HXExmGp 3 试题 HXE ...
- 【曝】苹果应用商店逾千款iOS应用存安全漏洞
据国外网站Ibtimes报道,知名网络安全公司FireEye日前警告称,由于一款名为“JSPatch”.可帮助开发者修改应用程序的软件上存在安全漏洞,导致苹果应用商店内1000多款使用了该框架的iOS ...
- 《学习记录》ng2-bootstrap中的component使用教程
前序: 现在angular2已经除了集成的angular-cli,建议大家可以基于这个来快速开发ng2的项目,不用自己再搭建环境: 相关内容请前往:https://angular.cn/docs/ts ...
- Spring+CXF的WebServices简单示例
本文就最简单的WebServices示例来演示Spring和CXF的整合. 使用Maven创建webapp项目,pom如下 <properties> <cxf.version> ...
- 深入源码剖析String,StringBuilder,StringBuffer
[String,StringBuffer,StringBulider] 深入源码剖析String,StringBuilder,StringBuffer [作者:高瑞林] [博客地址]http://ww ...
- 基于 Koa平台Node.js开发的KoaHub.js的模板引擎代码
koahub-handlebars koahub-handlebars koahub handlebars templates Installation $ npm install koahub-ha ...
- react.js 获取真实的DOM节点
为了获取真实的dom节点,文本输入框必须有一个 ref 属性,然后 this.refs.[refName] 就会返回这个真实的 DOM 节点. var MyComponent = React.crea ...
- H5 内联 SVG
HTML5 内联 SVG HTML5 画布 HTML5 画布 vs SVG HTML5 支持内联 SVG. 什么是SVG? SVG 指可伸缩矢量图形 (Scalable Vector Graphics ...
- 使用JSON.parse(),JSON.stringify()实现对对象的深拷贝
根据不包含引用对象的普通数组深拷贝得到启发,不拷贝引用对象,拷贝一个字符串会新辟一个新的存储地址,这样就切断了引用对象的指针联系. 测试例子: var test={ a:"ss", ...