Spark_总结一
Spark_总结一
1.Spark介绍
2.Spark运行模式(四种 )
| Local | 多用于测试 |
| Standalone | Spark自带的资源调度器(默认情况下就跑在这里面) |
| MeSOS | 资源调度器,同Hadoop中的YARN |
| YARN | 最具前景,公司里大部分都是 Spark on YRAN |
3.Spark内核之RDD的五大特性
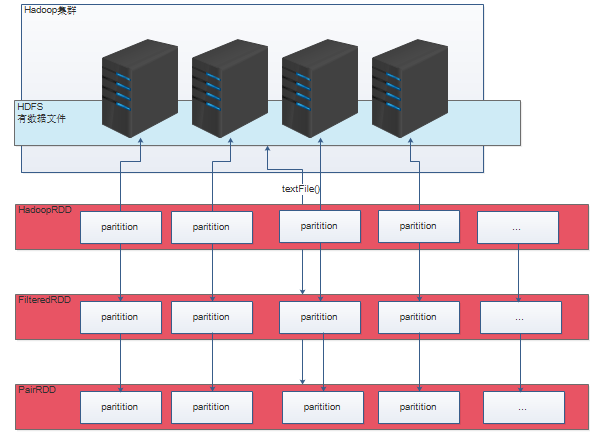
4.Spark运行机制
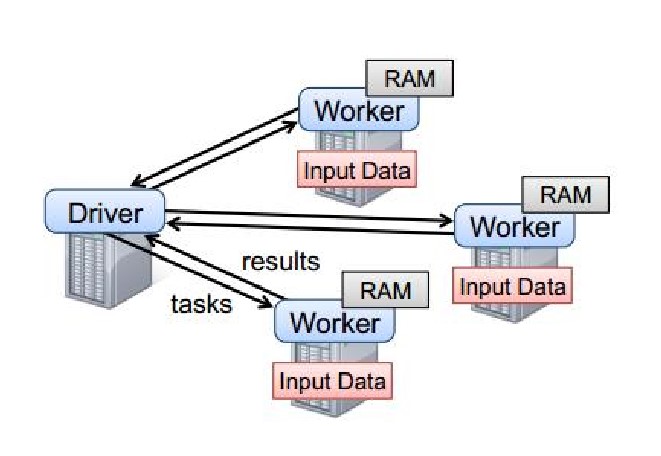
5.Spark运行时
6.Spark算子--Transformations || Actions
|
Transformations || Actions 这两类算子的区别
|
||
|
Transformations
|
Transformations类的算子会返回一个新的RDD,懒执行 | |
|
Actions
|
Actions类的算子会返回基本类型或者一个集合,能够触发一个job的 执行,代码里面有多少个action类算子,那么就有多少个job | |
| Transformation类算子 | map | 输入一条,输出一条 将原来 RDD 的每个数据项通过 map 中的用户自定义函数映射转变为一个新的 元素。输入一条输出一条; |
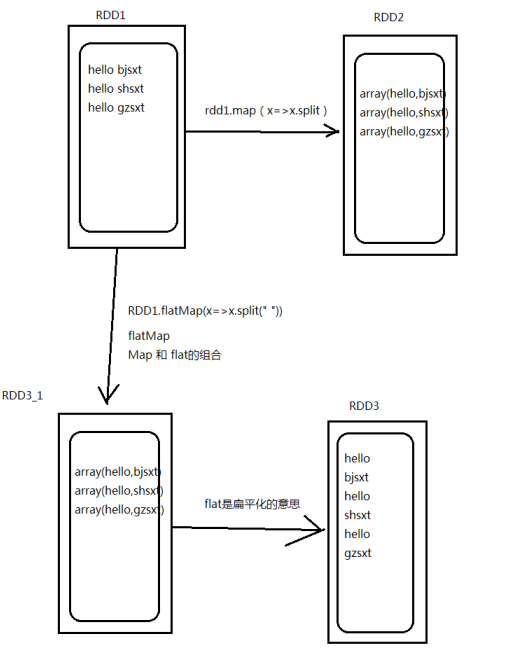
| flatMap | 输入一条输出多条 先进行map后进行flat |
|
| mapPartitions | 与 map 函数类似,只不过映射函数的参数由 RDD 中的每一个元素变成了 RDD 中每一个分区的迭代器。将 RDD 中的所有数据通过 JDBC 连接写入数据库,如果使 用 map 函数,可能要为每一个元素都创建一个 connection,这样开销很大,如果使用 mapPartitions,那么只需要针对每一个分区建立一个 connection。 | |
| mapPartitionsWithIndex | ||
| filter | 依据条件过滤的算子 | |
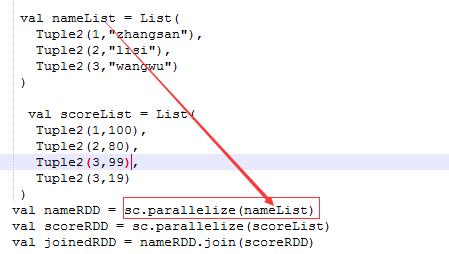
| join | 聚合类的函数,会产生shuffle,必须作用在KV格式的数据上 join 是将两个 RDD 按照 Key 相同做一次聚合;而 leftouterjoin 是依 据左边的 RDD 的 Key 进行聚 |
|
| union | 不会进行数据的传输,只不过将这两个的RDD标识一下 (代表属于一个RDD) |
|
| reduceByKey | 先分组groupByKey,后聚合根据传入的匿名函数聚合,适合在 map 端进行 combiner | |
| sortByKey | 依据 Key 进行排序,默认升序,参数设为 false 为降序 | |
| mapToPair | 进行一次 map 操作,然后返回一个键值对的 RDD。(所有的带 Pair 的算子返回值均为键值对) | |
| sortBy | 根据后面设置的参数排序 | |
| distinct | 对这个 RDD 的元素或对象进行去重操作 | |
| Actions类算子 | foreach | foreach 对 RDD 中的每个元素都应用函数操作,传入一条处理一条数据,返回值为空 |
| collect | 返回一个集合(RDD[T] => Seq[T]) collect 相当于 toArray, collect 将分布式的 RDD 返回为一个单机的 Array 数组。 |
|
| count | 一个 action 算子,计数功能,返回一个 Long 类型的对象 | |
| take(n) | 取前N条数据 | |
| save | 将RDD的数据存入磁盘或者HDFS | |
| reduce | 返回T和原来的类型一致(RDD[T] => T) | |
| foreachPartition | foreachPartition 也是根据传入的 function 进行处理,但不 同处在于 function 的传入参数是一个 partition 对应数据的 iterator,而不是直接使用 iterator 的 foreach。 |
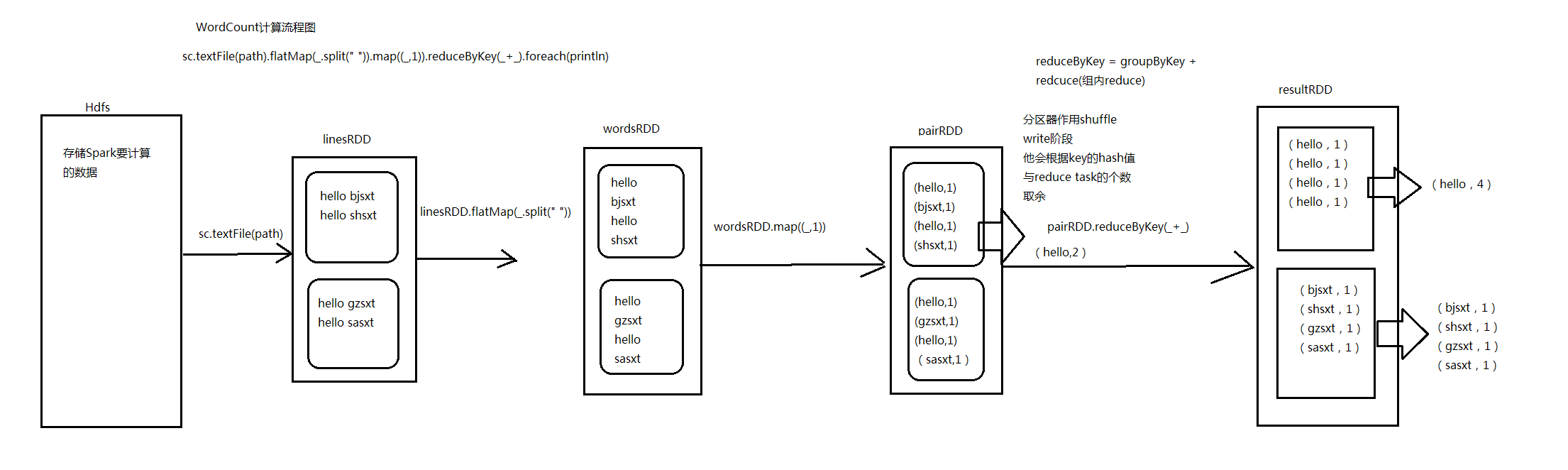
7.Spark中WordCount演变流程图_Scala和Java代码
package com.hzf.spark.exerciseimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/*** 统计每一个单词出现的次数*/object WordCount{def main(args:Array[String]):Unit={/*** 设置Spark运行时候环境参数 ,可以在SparkConf对象里面设置* 我这个应用程序使用多少资源 appname 运行模式*/val conf =newSparkConf().setAppName("WordCount").setMaster("local")/*** 创建Spark的上下文 SparkContext** SparkContext是通往集群的唯一通道。* Driver*/val sc =newSparkContext(conf)//将文本中数据加载到linesRDD中val linesRDD = sc.textFile("userLog")//对linesRDD中每一行数据进行切割val wordsRDD = linesRDD.flatMap(_.split(" "))val pairRDD = wordsRDD.map{(_,1)}/*** reduceByKey是一个聚合类的算子,实际上是由两步组成** 1、groupByKey* 2、recuce*/val resultRDD = pairRDD.reduceByKey(_+_)/*(you,2)(Hello,2)(B,2)(a,1)(SQL,2)(A,3)(how,2)(core,2)(apple,1)(H,1)(C,1)(E,1)(what,2)(D,2)(world,2)*/resultRDD.foreach(println)/*(Spark,5)(A,3)(are,2)(you,2)(Hello,2)*/val sortRDD = resultRDD.map(x=>(x._2,x._1))val topN = sortRDD.sortByKey(false).map(x=>(x._2,x._1)).take(5)topN.foreach(println)}}

Spark_总结一的更多相关文章
- Spark_总结四
Spark_总结四 1.Spark SQL Spark SQL 和 Hive on Spark 两者的区别? spark on hive:hive只是作为元数据存储的角色,解析 ...
- Spark_总结五
Spark_总结五 1.Storm 和 SparkStreaming区别 Storm 纯实时的流式处理,来一条数据就立即进行处理 SparkStreaming ...
- Spark_总结七_troubleshooting
转载标明出处 http://www.cnblogs.com/haozhengfei/p/07ef4bda071b1519f404f26503fcba44.html Spark_总结七_troubles ...
- 创建spark_读取数据
在2.0版本之前,使用Spark必须先创建SparkConf和SparkContext,不过在Spark2.0中只要创建一个SparkSession就够了,SparkConf.SparkContext ...
- Spark_安装配置_运行模式
一.Spark支持的安装模式: 1.伪分布式(一台机器即可) 2.全分布式(至少需要3台机器) 二.Spark的安装配置 1.准备工作 安装Linux和JDK1.8 配置Linux:关闭防火墙.主机名 ...
- spark_运行spark-shell报错_javax.jdo.JDOFatalDataStoreException: Unable to open a test connection to the given database.
error: # ./spark-shell Caused by: javax.jdo.JDOFatalDataStoreException: Unable to open a test connec ...
- Scala 中object和class的区别
Scala中没有静态类型,但是有有“伴侣对象”,起到类似的作用. Scala中类对象中不可有静态变量和静态方法,但是提供了“伴侣对象”的功能:在和类的同一个文件中定义同名的Object对象:(须在同一 ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- Spark-Streaming总结
文章出处:http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html Spark_总结五 1.Storm 和 ...
随机推荐
- Golang丰富的I/O----用N种Hello World展示
h1 { margin-top: 0.6cm; margin-bottom: 0.58cm; direction: ltr; color: #000000; line-height: 200%; te ...
- 序列化之对象,字符串,byte数组,XML之间的转换(一)
工作一年多了,越来越感到自己不能这样一直下去,在最好的青春里面却已经死了.被时间消磨了意志,被工作杀死了精神.我想,我只要活着,我就要去不断的要求自己,不断的去追求更高的山峰. 放眼四周,有趣的灵魂越 ...
- mysql数据库出现2003-Can't connect to MySQL server on 'localhost' (10061)的解决方法
1.右键点击我的电脑,找到管理! 2.找到服务和应用程序: 3.打开找到服务,打开: 4.在服务里找到MySQL,改成启动:
- Java IO详解(四)------字符输入输出流
File 类的介绍:http://www.cnblogs.com/ysocean/p/6851878.html Java IO 流的分类介绍:http://www.cnblogs.com/ysocea ...
- Java求循环节长度
两个整数做除法,有时会产生循环小数,其循环部分称为:循环节.比如,11/13=6=>0.846153846153..... 其循环节为[846153] 共有6位.下面的方法,可以求出循环节的长 ...
- Linux简介与安装
Linux系统的组成 Linux 内核:内核是系统的"心脏",是运行程序与管理像磁盘和打印机等硬件设备的核心程序. Linux Shell:Shell是系统的用户界面,提供了用户与 ...
- Mycat 配置
前言 Mycat 是一个数据库分库分表中间件 MyCAT 是作为通用代理设计的,后端是以 Mysql协议 和 JDBC 的方式连接数据库,可以支持 Oracle.DB2.SQL Server . mo ...
- 搬个小板凳,我们扯扯Docker的前生
一.新瓶装旧酒 首先我们需要知道,Docker是一个"箩筐": 1.存储:Device Mapper.BtrFS.AUFS 2.名字空间:UTS.IPC.Mount.PID.Net ...
- View 动画 Animation 运行原理解析
这次想来梳理一下 View 动画也就是补间动画(ScaleAnimation, AlphaAnimation, TranslationAnimation...)这些动画运行的流程解析.内容并不会去分析 ...
- 【django基础】
一.MTV模型 Django的MTV分别代表: Model(模型):负责业务对象与数据库的对象(ORM) Template(模版):负责如何把页面展示给用户 View(视图):负责业务逻辑,并在适当的 ...