InfluxDB+Grafana大数据监控系列之数据源配置(二)
一、Grafana 配置 InfluxDB 数据源
1.1 登录 Granfana 界面选择 InfluxDB 数据源
在前面我们已经部署好相应监控环境,登录Grafana:http://10.223.1.199:3000/,登录密码默认是 admin / admin,初次登录时会要求修改密码。
进入 Settings -> Data Sources -> Add data source,可以看到 Grafana 支持多种数据源,在这里我们选择 InfluxDB 数据源。

1.2 配置 InfluxDB 数据库登录信息
可以看出,InfluxDB 数据源配置包括 Name、HTTP、Auth、Basic Auth Details 和 InfluxDB Details 几个部分:
- Name:配置的数据源名称,可以随便取;
- HTTP:InfluxDB 数据库部署的地址,默认 8086 端口;
- Auth:InfluxDB 的账号认证机制,图中勾选了账号认证,即需要进行账号认证。InfluxDB 默认没有启用账号认证,若要启用则需要修改配置,在文章 https://www.cnblogs.com/walker-/p/11286283.html 中会介绍;
- Basic Auth Details:启动认证的用户名和密码;
- InfluxDB Detail:要连接的 InfluxDB 数据库的信息,包括数据库名、用户名和密码

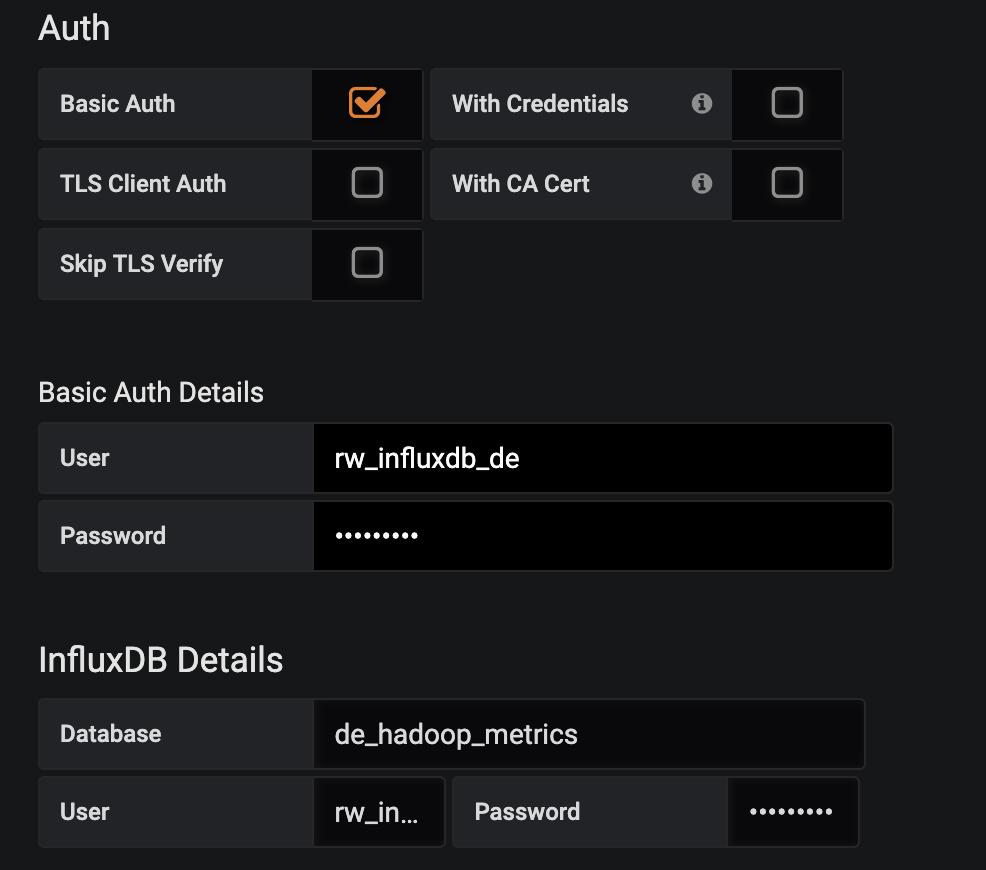
配置完相关信息后点击下面的‘Save & Test’,则 Grafana 添加 InfluxDB 数据源工作已完成,可以开始尽情的配置监控指标了。
【参考资料】
[1]. https://grafana.com/docs/v5.4/guides/getting_started/
InfluxDB+Grafana大数据监控系列之数据源配置(二)的更多相关文章
- InfluxDB+Grafana大数据监控系列之基础环境部署(一)
一.单节点环境部署 机器节点信息及 InfluxDB.Grafana 版本选择: 节点 Linux版本 部署服务 10.223.1.198 Centos 6.8 InfluxDB 1.7.7 10.2 ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(三)
在之前系列博文中,已经介绍完了数据采集和数据存储,那数据如何展示呢?所以今天就专门来讲下数据如何展示的问题. 以前博文参考: Docker系列--InfluxDB+Grafana+Jmeter性能监控 ...
- Docker系列——InfluxDB+Grafana+Jmeter性能监控平台搭建(一)
在做性能测试的时候,重点关注点是各项性能指标,用Jmeter工具,查看指标数据,就是借助于聚合报告,但查看时也并不方便.那如何能更直观的查看各项数据呢?可以通过InfluxDB+Grafana+Jme ...
- [转帖] 基于telegraf, influxdb, grafana 建立 esxi 监控
[系统集成] 基于telegraf, influxdb, grafana 建立 esxi 监控 https://www.cnblogs.com/hahp/p/7677420.html 之前在 nagi ...
- Telegraf+InfluxDB+Grafana搭建服务器监控平台
Telegraf+InfluxDB+Grafana搭建服务器监控平台 tags:网站 个人网站:https://wanghualong.cn/ 效果展示 本站服务器状态监控:https://statu ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
随机推荐
- centOS7 下 安装mysql8.x
第一部分 CentOS7安装mysql1.1 安装前清理工作:1.1.1 清理原有的mysql数据库:使用以下命令查找出安装的mysql软件包和依赖包: rpm -pa | grep mysql 显示 ...
- MySQL之left jion 、 right jion 和inner jion 的区别和使用方法
left jion 左联结 right jion 右联结 inner jion 等值联结 create table teacher( tid ) primary key auto_incremen ...
- kafka读书笔记《kafka并不难学》
======第一章 1 在高并发场景,如大量插入.更新数据库会导致锁表,导致连接数过多的异常,此时需要消息队列来缓冲一下.消息队列通过异步处理请求来缓解压力 2 消息队列采用异步通信机制消息队列拥有先 ...
- Copy Books
Description Given n books and the i-th book has pages[i] pages. There are k persons to copy these bo ...
- waitgroup等待退出
等待一组协程结束,用sync.WaitGroup操作 package main import ( "fmt" "sync" "time" ) ...
- sql server 交集,差集的用法 (集合运算)
概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便. 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合. 在T-SQL中.UN ...
- reCaptcha 新版,国内可无障碍使用
reCaptcha 新版,国内可无障碍使用 蓝小灰 Digital Sign® PKI 创始人/一点安全专栏主编 4 人赞同了该文章 如果你在使用一些网站看到下图,这就是由 Google 提供的 re ...
- Vue.js 中的 v-cloak 指令
可以使用 v-cloak 指令设置样式,这些样式会在 Vue 实例编译结束时,从绑定的 HTML 元素上被移除. 当网络较慢,网页还在加载 Vue.js ,而导致 Vue 来不及渲染,这时页面就会显示 ...
- [HNOI2002]营业额统计 II
https://www.luogu.org/problemnew/show/2234 将权值离散化,以权值为下标建立权值线段树 #include <bits/stdc++.h> using ...
- 前端逼死强迫症系列之javascript续集
一.javascript函数 1.普通函数 function func(){ } 2.匿名函数 setInterval(function(){ console.log(123); },5000) 3. ...