大数据小白系列——HDFS(1)

【注1:结尾有大福利!】
【注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对。】
大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件事:一、怎么存储大数据,二、怎么计算大数据。
我们先从存储开始说,如果清晨起床,你的女仆给你呈上一块牛排,牛排太大,一口吃不了,怎么办?拿刀切小。
同样的,如果一份数据太大,一台机器存不了,怎么办?切小了,存到几台机器上。
想要保存海量数据,无限地提高单台机器的存储能力显然是不现实,就好比我们不能把一栋楼盖得无限高一样(通常这也不是经济的做法),增加机器数量是相对可持续的方案。
使用多台机器,需要有配套的分布式存储系统把这些机器组织成一个整体,由于Hadoop几乎是目前大数据领域的事实标准,那么这里介绍的分布式存储系统就是HDFS(Hadoop Distributed Filesystem)。
先来介绍几个重要概念。
- 分片(shard)
就好比把牛排切成小块,对大的文件进行切分,显然是进行分布式存储的前提,例如,HDFS中默认将数据切分成128MB的块(block)。
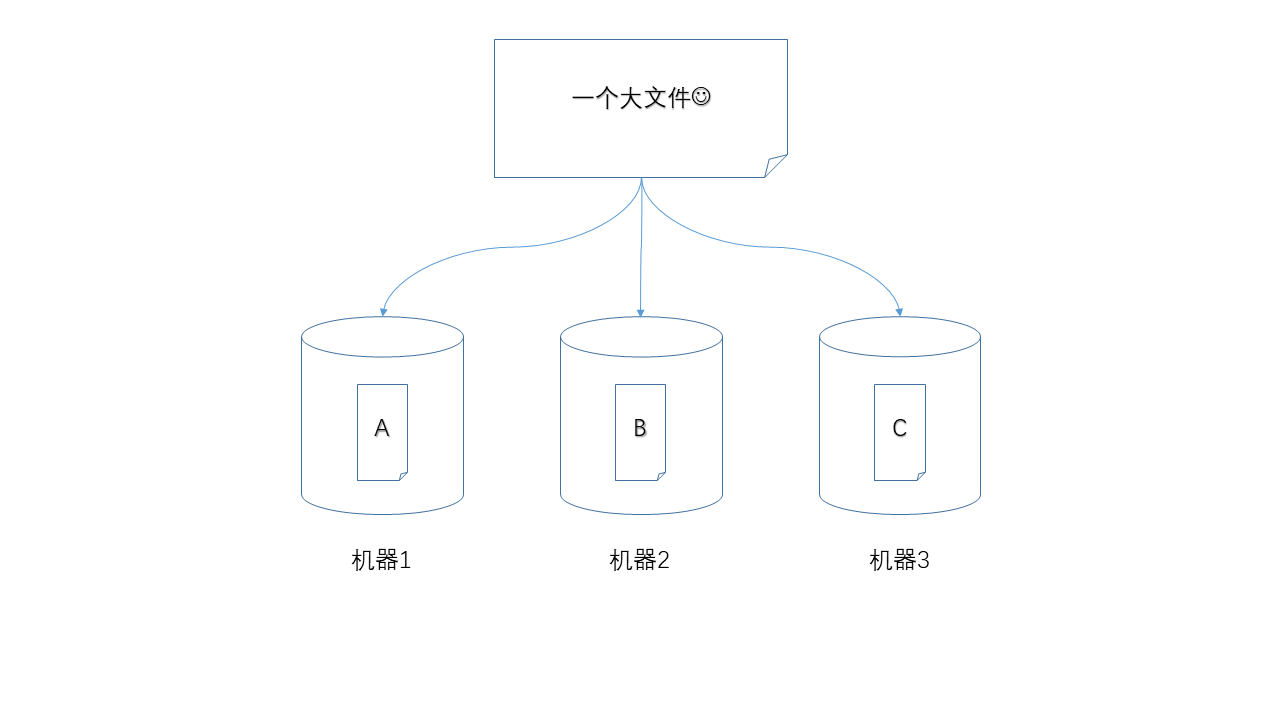
- 副本(replica)
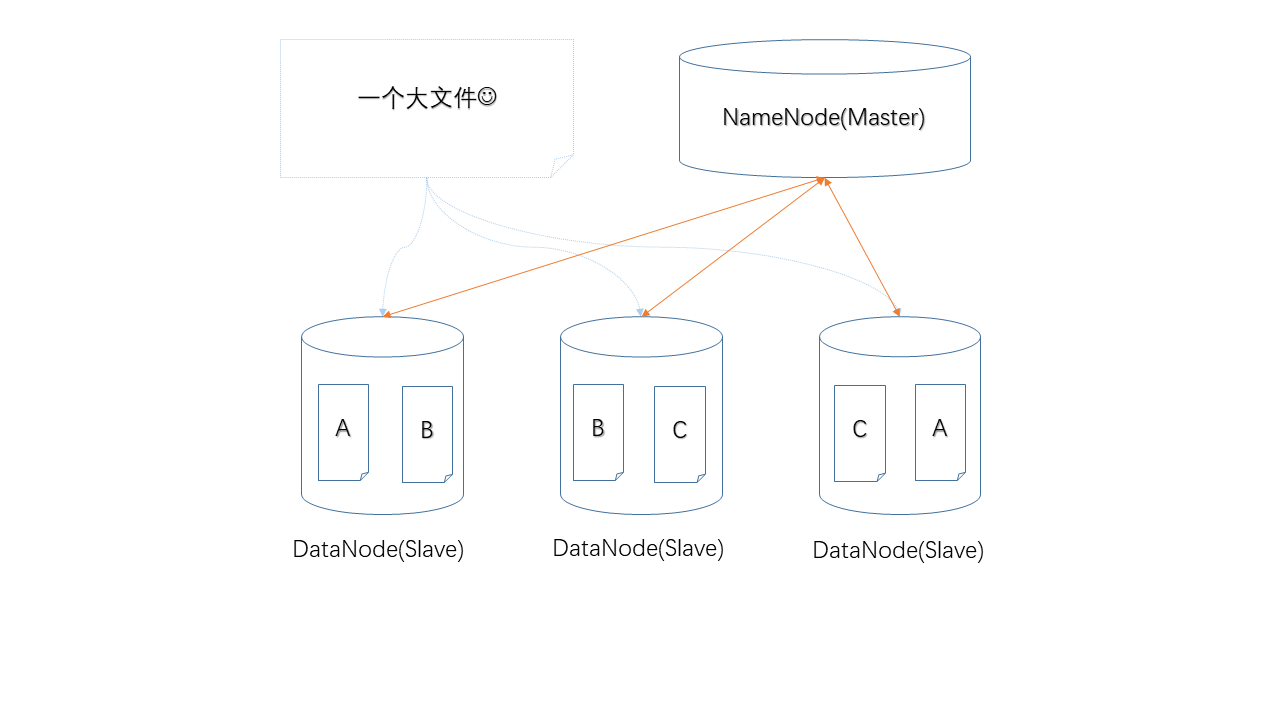
三台机器中,如果有一台出现故障,如何保证数据不丢失,那么就是使用冗余的方式,为每一个数据块都产生多个副本。
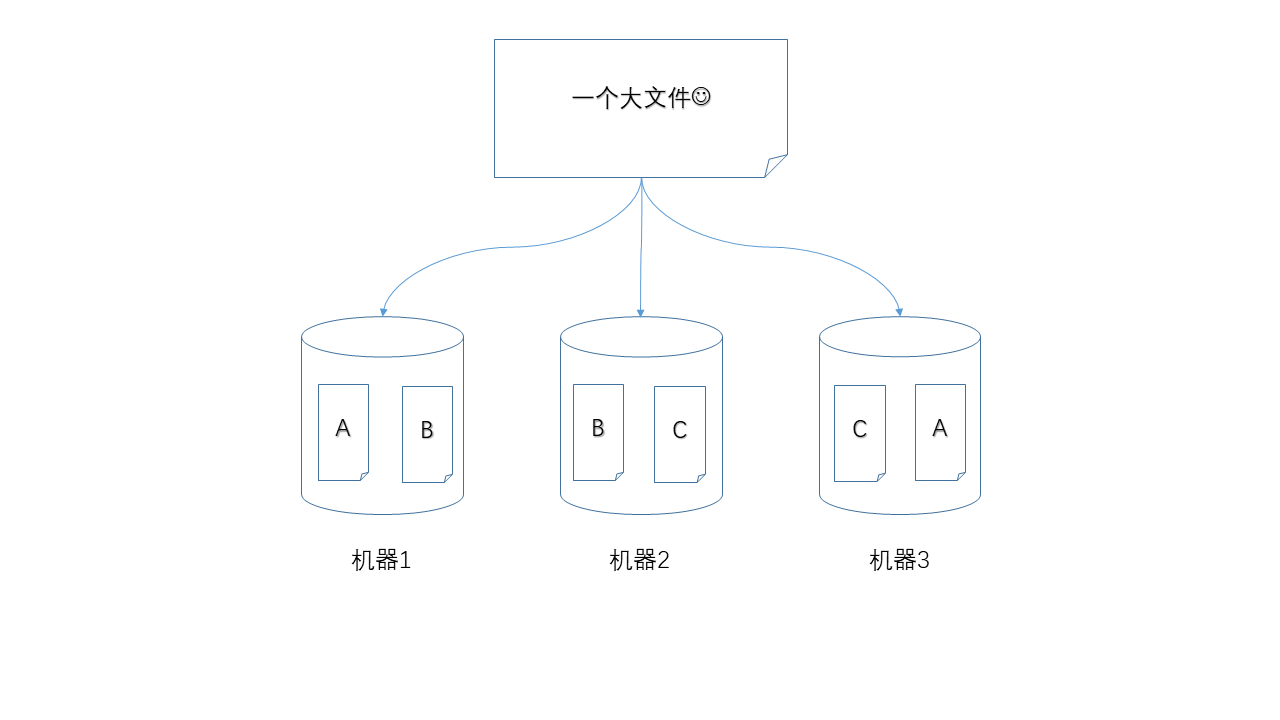
下面图示中,任何单独一个节点掉线,都不会造成数据丢失,仍然可以凑齐A、B、C三个数据块。
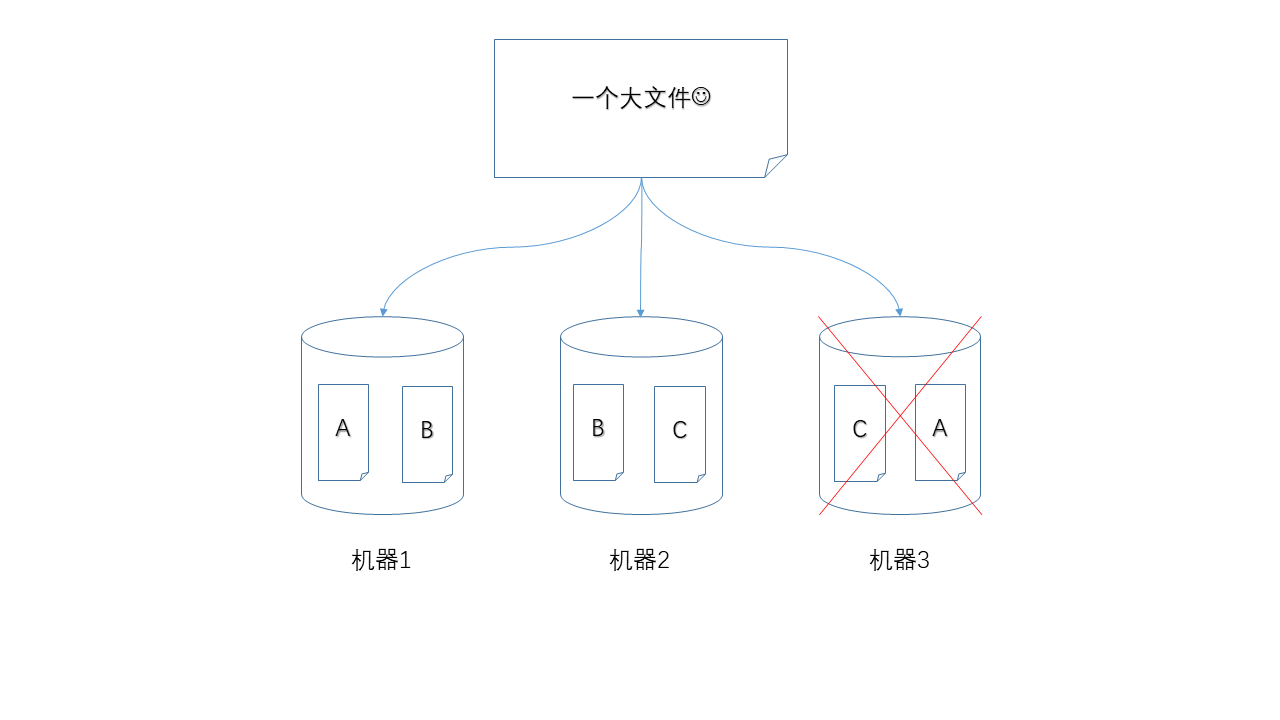
当然,如果两个节点同时掉线就不行了。
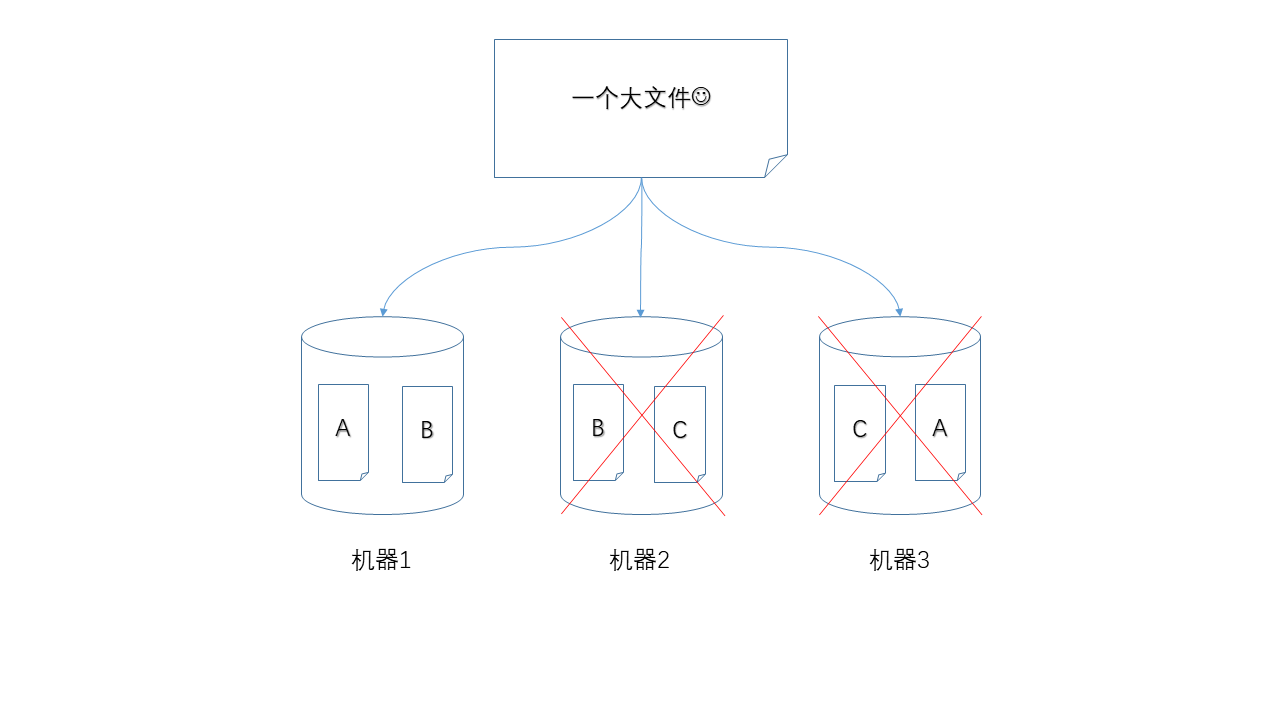
不过,如果每个数据块都有两个副本,那么可以承受同时损失两个节点。代价是,你的存储成本上升了。
- Master/Slave架构
只有工人而没有包工头的工地肯定不能正常运转,所以,除了上面3台负责存储的机器,还需要至少一台机器来领导它们,给它们分配工作,否则谁也没办法中的A、B、C具体应该存在哪个机器上。
HDFS中采用Master/Slave架构,其中的NameNode就是Master,负责管理工作,而DataNode就是Slave,负责存储具体的数据,NameNode上管理着元数据,简单的讲就是记录哪个数据块存储在哪台机器上。同时,DataNode也会定时向NameNode汇报自己的工作状态,以便后者监控节点状态、是否故障。
说完上面几个我觉得需要了解的基础概念,我们再把HDFS的读、写流程描述一下。
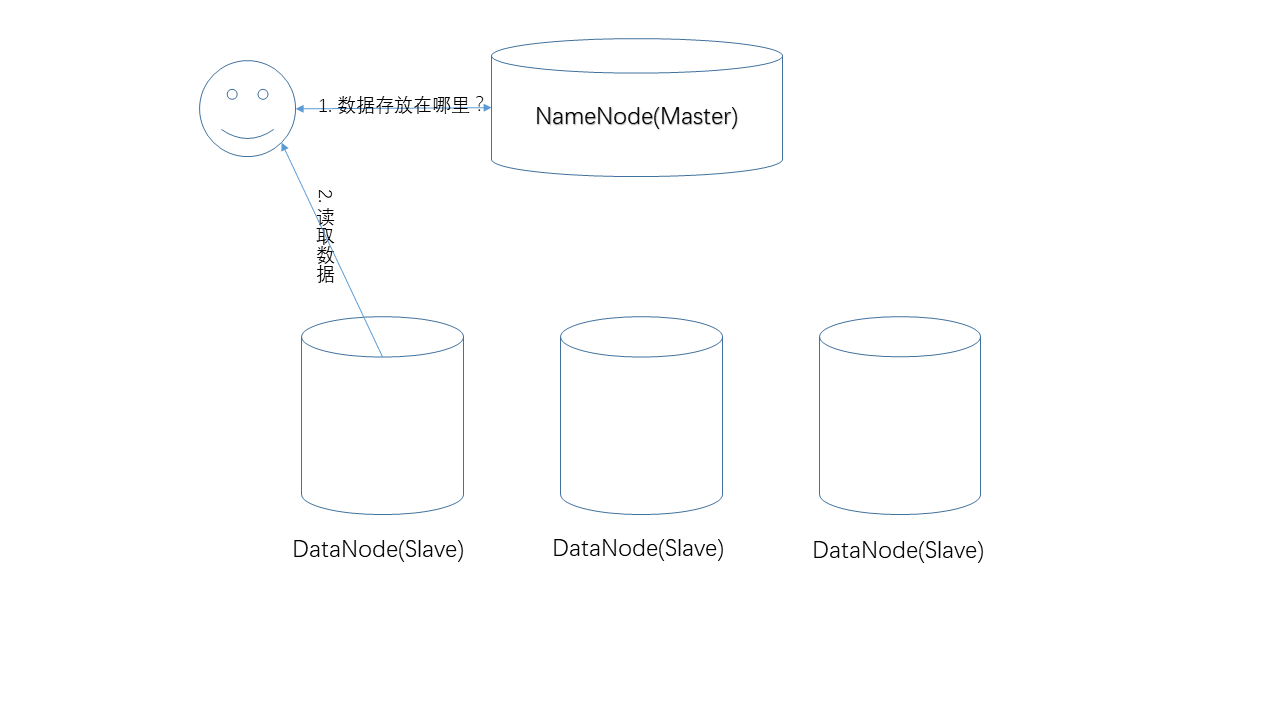
- 读取数据
读取数据的过程。在这个过程中,NameNode负责提供数据的存储位置,真正的数据读取操作发生在用户和DataNode之间。由于数据有副本,一份数据在多个节点上存在,具体NameNode返回哪个节点,遵循一定的原则(比如,就近原则)。
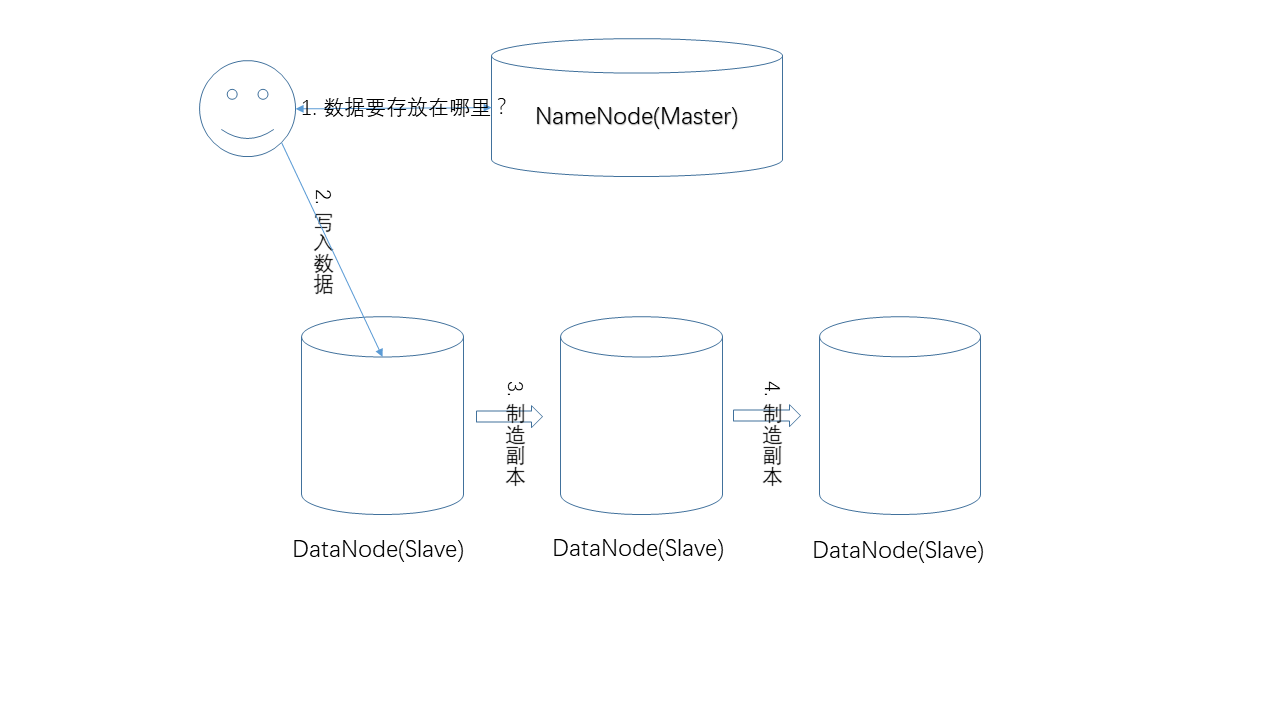
- 写入数据
写入数据的过程。和读取流程类似,NameNode负责提供数据的存储位置,真正的写入操作发生在用户和DataNode之间,而副本的制造,是在DataNode之间发生的,例如用户先把数据写入节点1,节点1再把数据复制到节点2等。
这篇文章就先到这里,下一篇准备接受HDFS中的单点问题、HA、Federation等概念。
最后,福利来了,关注公众号“程序员杂书馆”,将免费送出大数据经典书籍《Spark快速大数据分析》,没错,就是下面这本,纸质书哦,不是什么乱七八糟的其他书哦!还犹豫什么,抓紧扫码关注吧。“程序员杂书馆”以后将每周为大家带来经典书籍资料、原创干货分享,谢谢大家。
需要书的同学请直接在公众号留言哈,如果不想要纸质书的也可以说明,我会选择一些PDF数据赠送,谢谢大家。


大数据小白系列——HDFS(1)的更多相关文章
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- Confluence 6 已经存在的安装配置数据库字符集编码
针对已经存在的 Confluence 安装,如果你安装的 Confluence 版本是 6.4 或者早期的版本,我们在安装的时候没有检查你数据库的字符设置. 如果你的数据库当前没有被配置使用 UTF- ...
- pytorch的学习资源
安装:https://github.com/pytorch/pytorch 文档:http://pytorch.org/tutorials/beginner/blitz/tensor_tutorial ...
- python - 发送带各种类型附件的邮件
如何发送各种类型的附件. 基本思路就是,使用MIMEMultipart来标示这个邮件是多个部分组成的,然后attach各个部分.如果是附件,则add_header加入附件的声明. 在python中,M ...
- 继续JS之DOM对象二
前面在JS之DOM中我们知道了属性操作,下面我们来了解一下节点操作.很重要!! 一.节点操作 创建节点:var ele_a = document.createElement('a');添加节点:ele ...
- 【ftp】主动模式和被动模式
来自:http://blog.csdn.net/liuhelong12/article/details/50218311 原博主不让转载全文,不过下面这部分是原博主转载别人的,所以我拿过来应该没问题吧 ...
- cf862d 交互式二分
/* 二分搜索出一个01段或10即可 先用n个0确定1的个数num 然后测试区间[l,mid]是否全是0或全是1 如果是,则l=mid,否则r=mid,直到l+1==r 然后再测试l是1还是r是1 如 ...
- jQuery之导航菜单(点击该父节点时子节点显示,同时子节点的同级隐藏,但是同级的父节点始终显示)
注:对于同一个对象不超过3个操作的,可直接写成一行,超 过3个操作的建议每行写一个操作.这样可读性较强,可提高代码的可读性和可维护性 核心代码: $(".has_children" ...
- 【转】asp.net Core 系列【二】—— 使用 ASP.NET Core 和 VS2017 for Windows 创建 Web API
在本教程中,将生成用于管理“待办事项”列表的 Web API. 不会生成 UI. 概述 以下是将创建的 API: API 描述 请求正文 响应正文 GET /api/todo 获取所有待办事项 无 待 ...
- js中匿名函数和回调函数
匿名函数: 通过这种方式定义的函数:(没有名字的函数) 作用:当它不被赋值给变量单独使用的时候 1.将匿名函数作为参数传递给其他函数 2.定义某个匿名函数来执行某些一次性任务 var f = func ...
- 解决notepad++64位没有plugin manager的问题
安装了最新的notepad++版本发现没有插件管理器,很难受. 后来上官网发现了这样一句话 Note that the most of plugins (including Plugin Manage ...