Hadoop集群搭建-05安装配置YARN
先保证集群5台虚拟机,
| nn1 | nn2 | s1 | s2 | s3 | |
|---|---|---|---|---|---|
| hadoop | 是 | 是 | 是 | 是 | 是 |
| zookeeper | 是 | 是 | 是 | ||
| namenode | 是 | 是 | |||
| jouralnode | 是 | 是 | |||
| datanode | 是 | 是 | 是 |
1.然后启动yarn在nn1机器上:
[hadoop@nn1 hadoop]$ start-yarn.sh
然后查看各节点信息
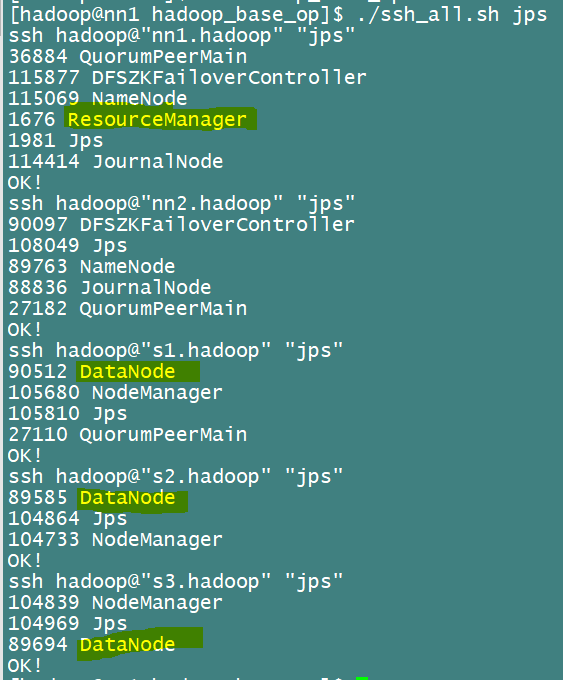
2.配置yarn的HA高可用
高可用就是好几台机器,一台突然挂掉了,其他机器就补上去,刚刚只启动了nn1作为yarn服务器,只有一台,所以这里要在nn2也开一台,来做简单的高可用
###############在nn2控制台操作####################
[hadoop@nn2 ~]$ yarn-daemon.sh start resourcemanager
如图查看jps
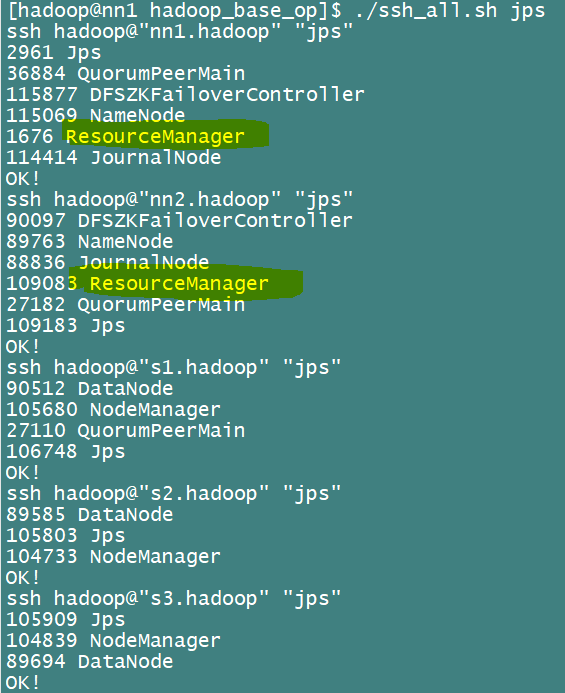
这里相比第一张图,在nn2多了一个resourceManager
##########查看状态############
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm1
active
[hadoop@nn1 hadoop_base_op]$ yarn rmadmin -getServiceState rm2
standby
打开网页查看http://192.168.10.6:8088/cluster
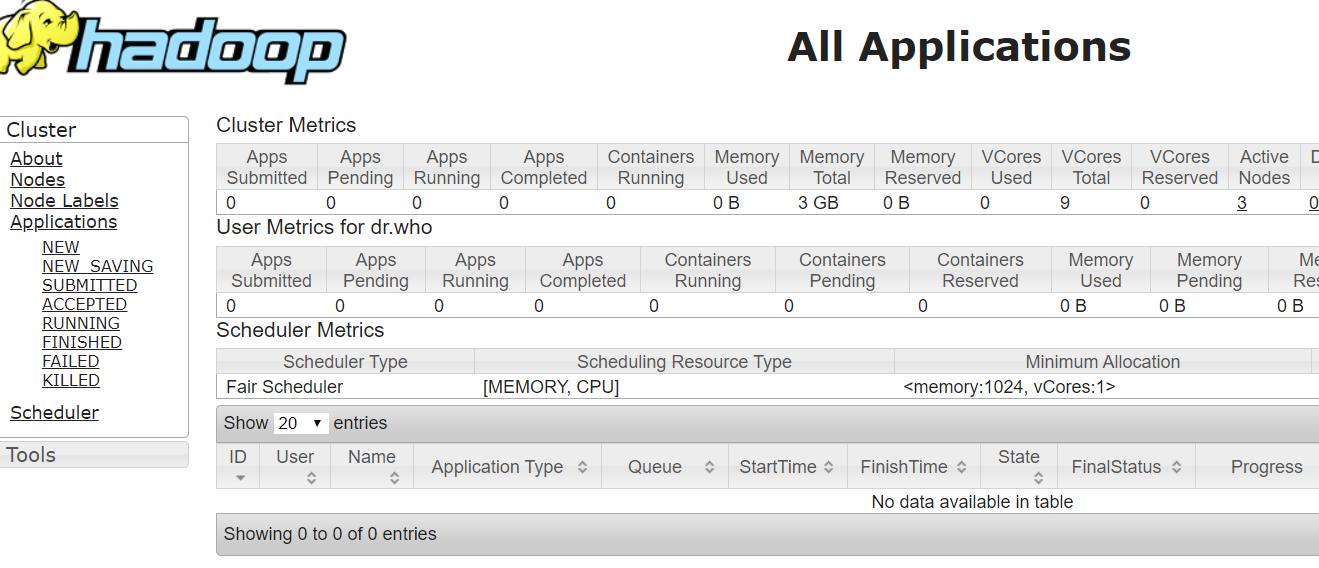
出现hadoop页面就是成功了,这时候因为nn1是active状态,所以你输入http://192.168.10.7:8088/cluster的话,或自动跳转到active机器,也就是自动跳转到nn1的ip上。
启动成功
来,跑个任务试试
用这个集群进行简单的wordcount任务
创建两个文件
vim abc1
aa bbb abc
aa aa
aa bb
aa cc aa
vim abc2
张三 张 三
张
三 张
把这两个文件上传到hadoop的hdfs上
[hadoop@nn1 ~]$ hadoop fs -mkdir -p /user/hadoop/abc/input
[hadoop@nn1 ~]$ hadoop fs -put ./abc* /user/hadoop/abc/input
查看网页端:
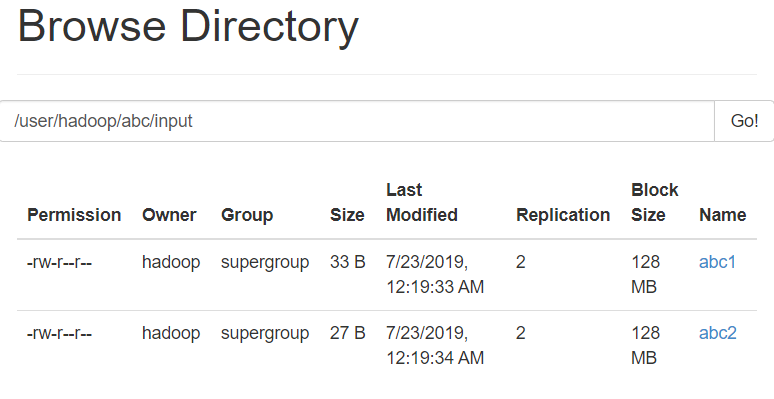
扔到MR里执行下
[hadoop@nn1 ~]$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /user/hadoop/abc/input /user/hadoop/abc/output

查看网页端的状态展示:
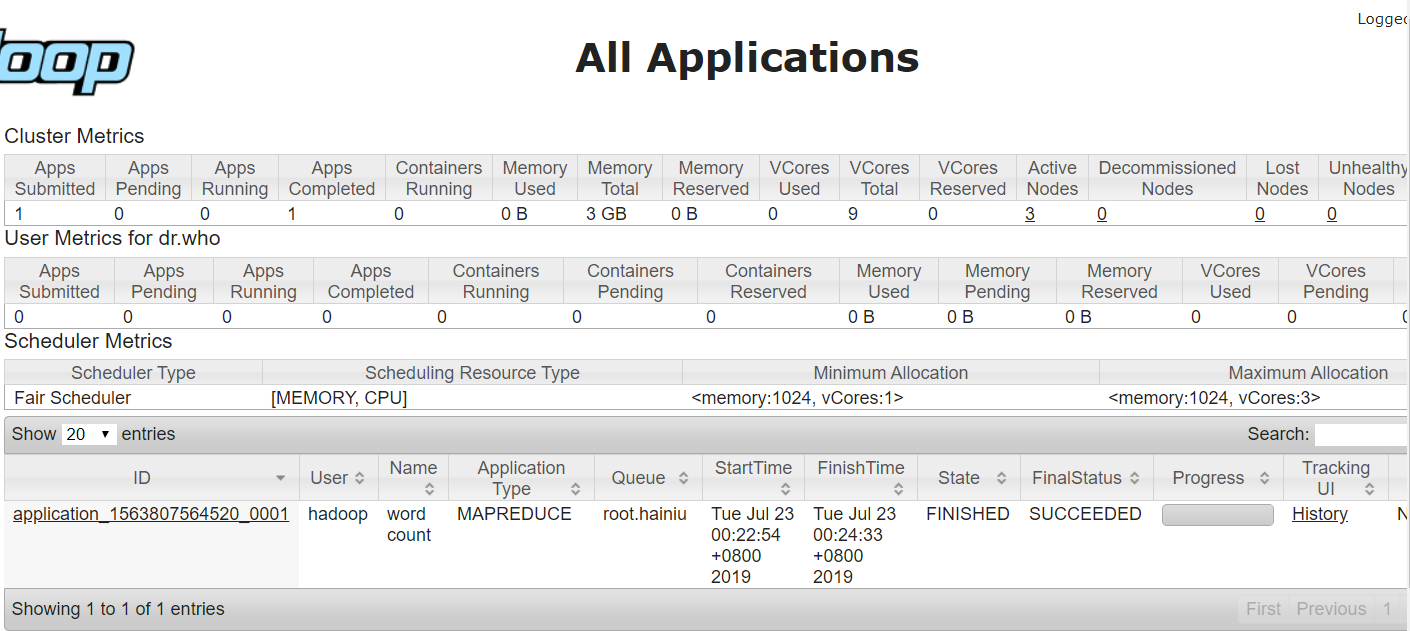
然后我们去hadoop那里查看结果文件
[hadoop@nn1 ~]$ hadoop fs -cat /user/hadoop/abc/output/part-r-00000
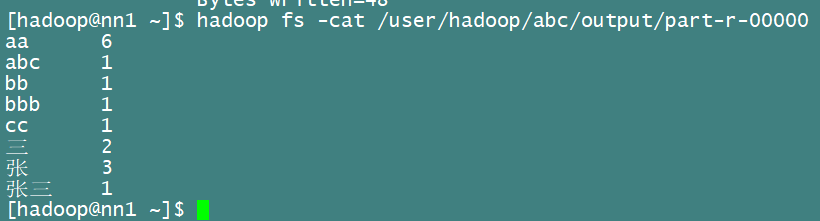
大功告成!!!
Hadoop集群搭建-05安装配置YARN的更多相关文章
- Hadoop集群搭建-04安装配置HDFS
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- Hadoop集群搭建-02安装配置Zookeeper
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- Linux下Hadoop集群环境的安装配置
1)安装Ubuntu或其他Linux系统: a)为减少错误,集群中的主机最好安装同一版本的Linux系统,我的是Ubuntu12.04. b)每个主机的登陆用户名也最好都一样,比如都是hadoop,不 ...
- Hadoop集群搭建(六)~安装JDK
前面集群的准备工作都做完了,本篇记录安装JDK,版本位1.8 1,在opt目录下创建software和module文件夹:software用来放安装包,module为安装目录 2,把JDK和hadoo ...
- Hadoop集群搭建的密钥配置SSH实现机制的配置(2)
[hadoop@weekend110 ~]$ ssh-keygen -t rsa 用来生产密钥对 Generating public/private rsa key pair. Enter file ...
- Hadoop集群搭建-虚拟机安装(转)(一)
1.软件准备 a).操作系统:CentOS-7-x86_64-DVD-1503-01 b).虚拟机:VMware-workstation-full-9.0.2-1031769(英文原版先安装) VM ...
- Hadoop集群搭建的密钥配置SSH实现机制
- Hadoop集群搭建-03编译安装hadoop
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
随机推荐
- [Luogu] 相关分析
不想调了 #include <bits/stdc++.h> ; #define LL long long #define gc getchar() int fjs; struct Node ...
- [Luogu] 魔法树
https://www.luogu.org/problemnew/show/P3833 树链剖分 + 线段树 为啥会RE?? 不解 #include <iostream> #include ...
- Towers of Hanoi Strike Back (URAL 2029)
Problem The Tower of Hanoi puzzle was invented by French mathematician Édouard Lucas in the second h ...
- single-pass单遍聚类方法
一.通常关于文本聚类也都是针对已有的一堆历史数据进行聚类,比如常用的方法有kmeans,dbscan等.如果有个需求需要针对流式文本进行聚类(即来一条聚一条),那么这些方法都不太适用了,当然也有很多其 ...
- 无线AP知识点
FAT模式指该AP可以独立配置,有独立的管理界面,就像普通的无线AP:FAT模式主要用在没有使用AC的小型网络中. FIT模式指该AP由TP-LINK AC(无线控制器)统一管控设置. 1,这个 ...
- 2016 NEERC, Moscow Subregional Contest K. Knights of the Old Republic(Kruskal思想)
2016 NEERC, Moscow Subregional Contest K. Knights of the Old Republic 题意:有一张图,第i个点被占领需要ai个兵,而每个兵传送至该 ...
- 第七章 python基础之函数,递归,内置函数
五 局部变量和全局变量 name='cyj' #在程序的一开始定义的变量称为全局变量. def change_name(): global name #global 定义修改全局变量. name=&q ...
- 2018-2019-2 20175226王鹏雲 实验四《Android程序设计》实验报告
2018-2019-2 20175226王鹏雲 实验四<Android程序设计>实验报告 实验报告封面 课程:Java程序设计 班级:1752班 姓名:王鹏雲 学号:20175226 指导 ...
- Linux编程之recvmsg和sendmsg函数
recvmsg 和 sendmsg 函数 #include <sys/types.h> #include <sys/socket.h> ssize_t send(int soc ...
- 用Qt生成dll类库及调用方法
空白工程新建DLL后,将DLL和LIB文件放入需要调用的“指定目录” 项目->属性->连接器->常规->附加库目录->添加“指定目录” 项目->属性->连接器 ...