深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用

基于深度学习的人脸识别发展,从deepid开始,到今年(或者说去年),已经基本趋于成熟。
凡是基于识别的,总是离不开三个东西:数据,网络,以及loss。
数据方面,
目前的公开数据集中有主打类别数的MS_celeb_1M,有主打各种姿态角与年龄的VggFace2;也有一些主打高质量的数据集,像WebFace,guo yandong的MS-20K。除了公开数据集之外,图片生成领域也有不错的成果,例如基于三维人脸模型生成不同姿态角的人脸图片,利用GAN生成不同人脸角度或者属性的图片(StarGAN,TPGAN)。
网络方面,
从最开始的浅层网络lightCNN到后面的ResNet,Inception-ResNet,ResNeXt以及SeNET,都是针对识别而设计的网络,而并非针对人脸识别设计的网络,所以一些网络在人脸识别里带来的提升没有ImageNet那么明显。
由于人脸识别相对于一般的识别问题,存在人脸对比这样一个需求,这就将人脸识别的主要方向变成了metric learning问题而并非简简单单的分类问题。而近几年学术上的发展也基本是围绕loss function展开,除了像google,baidu这些拥有海量人脸数据的论文,focus点基本都在一个问题上:如何在有限的数据集上得到更高的精度。
如果光看loss function,从softmax,contrastive loss,triplet loss,center loss,normface,large margin loss , Asoftmax loss , coco loss,以及今年的AM,AAM,InsightFace。
这些在聚类上大致上可以分为下面两个类:
1.单纯聚类:contrasitve loss,center loss,normface, coco loss
2.加Margin聚类:triplet loss,large margin loss,Asoftmax loss,AM,AAM,InsightFace
在距离度量上可以分为下面两个类:
1.欧式距离:contrastive loss,center loss,normface,triplet loss
2.cosine距离/角度距离:large margin loss,Asoftmax loss,coco loss,AM,AAM,InsightFace
可以看到,目前的主要方向,在从euler距离往cosine距离发展的同时中间出现了像normface,sphereface,coco loss这些进行了Feature Normalization,Weight Normalization操作的loss,但是这几篇论文,除了sphereface稍稍介绍了缘由之外,其余的更像是一个实验性的结果,没有办法从理论上来说明。
必须注意到,无论哪种loss,其目的是为了更好的学习trainning dataset的分布,如果我们的trainning set 与 test set的数据分布一致的话,我们的才能说真正的学到了人脸的分布。在这里,我们不去分析各种loss的好坏,而是从数据分布上分析为什么要进行Feature Normalization,Weight Normalization以及triplet,以及到底有没有用。
当然,我以上提及到的数据,网络都是公开、能够获取到的东西。目前的商业公司里面的积累已经远远超过了公开的东西。
在我们进行分析之前,先将上面提及到的论文及其地址给出来以供读者更好读阅:
triplet loss: FaceNet: A Unified Embedding for Face Recognition and Clustering
center loss : A Discriminative Feature Learning Approach for Deep Face Recognition
normface :NormFace: L2 Hypersphere Embedding for Face Verification
Large Margin softmax loss: Large-Margin Softmax Loss for Convolutional Neural Networks
sphereface : SphereFace: Deep Hypersphere Embedding for Face Recognition
coco loss : Rethinking Feature Discrimination and Polymerization for Large-scale Recognition
AM : Additive Margin Softmax for Face Verification
AAM : Face Recognition via Centralized Coordinate Learning
ArcFace: ArcFace: Additive Angular Margin Loss for Deep Face Recognition
先说Weight Normalization
Weight Normalization
什么是Weight Normalization,顾名思义就是归一化的权重,当然我们这里讨论的Weight Normalization和之前的WN还不一样,我们这里主要是归一化分类层的权重。
如果以x表示输出特征,以y表示分类层的输出,那么分类层一般可以表示为:
其中这个W就是weight,b就是bias(偏置项)。
那么有人会问了,b怎么办,其实很早就一些炼金家发现对于softmax而言,加不加bias项其实对最后的结果没有什么影响。于是,Weight Normalization就将分类层写成以下形式:
那么Weight Normalization有没有效,我的结论是:有效
为什么有效?我们从3个方面来简单的分析一下:
1.
考虑以下情形:假设我们有60亿个id,每个id有1W张不同场景下的人脸图片,我们把这个做成一个训练集,直接用softmax去学习其分布,我们能不能说我们学到了全世界的人脸分布?答案是可以的,因为我们的test set再大,其id也不会超过全球的总人数,加之我们每个id下面的人脸图片足够多(1W)张,我们有理由确信这个分布是可信的。
2.
考虑以下情形:假设现在我们只有3个id,其中第一,第二个id下面有100张很相似的人脸图片,第三个id下面只有1张。现在我们用softmax去学习其分布,并用一个2维向量表示学到的特征,那么它的分布应该是下面这样的(二维可视化):
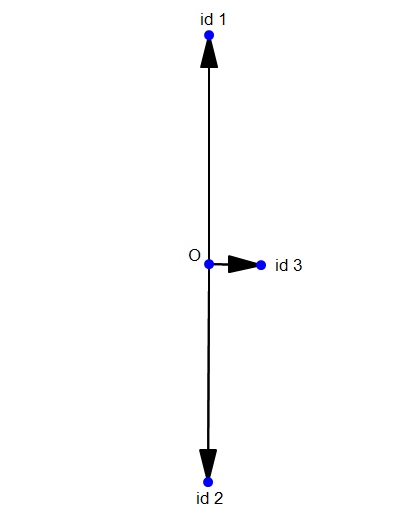
可以自己模拟一下,会发现这种情况下的softmax loss是最小的。也就是说,由于id1和id2的图片数量远大于id3的图片数量,导致id3在分类的时候基本处于一个随波逐流的状态。那么id3肯定不乐意的,同样都是人,为什么差距就那么大呢?没办法,谁让你底下只有1张图片呢?
但是我们自己肯定是有个判断的:id3是绝对可以拿出100张人脸图片的,只是在这个训练集中他没有拿出100张,他只拿出了1张。
这就好比我们丢硬币猜正反面,我们丢了10次硬币,其中有9次是正面,1次是背面。那么我们会预测下一次是正面的概率是90%吗?不是,我们知道概率是50%。相比于贝叶斯的先验概率,我们有一个更强的先验概率。
对于人脸同样如此,我们做Weight Normalization,正是因为我们可以主观上判定:每一个人都可以拿出同样多的人脸图片。
那么做了Weight Normalization,上面的可视化会变成这样的:
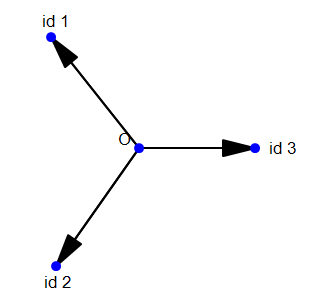
是不是瞬间就感觉合理多了。
3.
上面这个例子还缺少一个充分条件,那就是id的weight长度是和id下面的人脸图片数量是成正比的。
关于这一点,Guo Yandong在其论文里面做了详细的实验:
论文: One-shot Face Recognition by Promoting Underrepresented Classes
作者自己建了一个人脸base数据集,也就是我之前提到的MS_20K,包括20K个id,每个id下面有50-100张人脸图片;然后作者建立了一个novel数据集,包括1K个id,每个id下面有20张图片,作者称其为low shot learning,也就是为了探究样本不均衡的问题。
如果直接用softmax去学习这些图片,会得到如下结果:
 class index的weight norm
class index的weight norm
可以发现最后1k个类的weight norm明显小于前面20k个类的,于是作者设计了一个loss,称为UP loss,这个loss最后达到的效果是这样的:
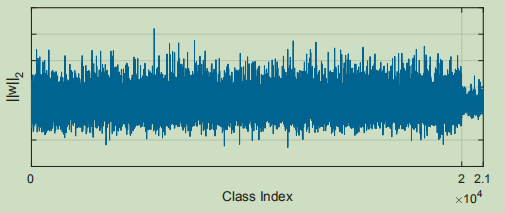
然后比较了一下这两种情况的区别:没有加loss的模型最后1K个类的分类准确率只有20%多,然后加了loss之后的模型最后1k个类的分类准确率有70%多,也就说明weight normalization确实是有效的,至于为什么分类准确率不是100%呢,这个我们后面再讨论。
另外一个说明weight normalization有效的例子即使Liu weiyang的Large Margin softmax与sphereface的对比,sphereface相较Large Margin softmax,其实就采用了Weight Normalization,最后的在LFW上的精度提升巨大。同样,作者在sphereface的v3版本里面的附录给出了weight Normalization的一些实验,感兴趣可以去浏览。
可能你看完上面的分析你就明白我要讲什么了,对的,那就是:
没有海量数据的情况下怎么办?数据不够,先验来凑。
Feature Normalization
1.Feature Norm
在讲Feature Normalization之前我们必须清楚的了解到Feature Norm到底代表什么含义,简单点来说,Feature Norm就是特征向量x的长度。所以,我们先要弄懂特征向量x的每一个维度代表什么。
先看一个简单的例子,人脸检测,最后输出一个1维的特征x,即置信度,当我们认为这个区域里面一定存在人的时候,输出1;当我们认为这个区域里面不存在人的时候,输出0。或者换一种说法,整个检测器就是一个相关判断器,整个CNN提取特征的网络就是一个扫描器,扫描感兴趣的东西(在这里也就是人脸)。扫到人脸,就是相关,输出的feature norm接近于1;没有扫到人脸,就是不相关,输出的feature norm接近于0.
对于人脸识别来说,同样如此。人脸识别最后的特征维度一般从128到512不等,一般认为512维已经足够表示人脸的分布了。我们把特征x拆开,可以认为x的每一个维度都是一个检测器,至于是什么检测器,就要看它对什么东西感兴趣了,可能是人眼大小的检测器,也可能是山羊胡须检测器。总的来说是人脸的一些局部特征的检测器,那合在一起是什么呢?其实也就是人脸检测器。
我们可以说,如果人脸特征x的norm越大,那么它就越像一张人脸;如果人脸特征x的norm越小,那么它就越不像一张人脸。
你觉得我可能在瞎BB,凭什么就能把人脸特征当成检测器呢?
2.为什么分类器能够把人脸分开?
这个问题很难回答,我们从反方向来思考一下:什么样的人脸难以被区分?
看一个极端的例子:
 黑色图片
黑色图片
这个和谁比较像?嗯,可能和非洲人有点像。
那这个呢:
 白色图片
白色图片
嗯,可能后欧洲人比较像。

事实上,上面那张黑色图片和白色图片的feature norm都接近于0。
我同样也测试过其他很多图片,其feature norm如下:

结论就是:如果脸部特征丢失(例如模糊,光照,侧脸,遮挡),此时该人脸变得难以区分,其feature norm就会相应减少。
3.那么要不要feature normalization呢?
我的结论是不需要,因为模糊,遮挡这些并不是人脸的正常状态,其对分类的影响力自然无法与正常的人脸相比。进行feature normalization反而会破坏整体的分布。
3.Triplet
在Weight Normalization里面我们遗留了一个问题,那就是Guo Yandong论文里面提及到的最后1K个id的分类准确率是70%多而不是接近100%,这又是为什么呢?
Weight Normalization真的解决了样本不均衡的问题吗?
不然,样本不均衡的问题仍然存在,还是看之前Weight Normalization提到的一个简单的例子:
现在我们变成了4个id,前两个id有100张图片,后两个id只有1张图片,如果按照Weight Normalization的方法,我们的分类会变成这样的:
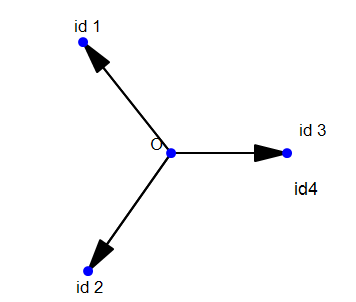
也就是说除非我们把id3,id4的图片数量增加到100个,才能完全消除样本不均衡的影响,这也就是某些论文中要将图片数小于30个的类去除的原因。
我们能够这样说:
如果这个id没有足够多的样本,那么这个id是不能被当成一个类的
什么叫做不能被当成一个类呢?就是说这个类不应该存在分类类中心。
如果我们要做one-shot learning,比如我们现在有全国每一个人的身份证照,但是只有一张,怎么办,我们又不能把这些图片给删掉。
不计算类中心最为简单的办法就是triplet。
这里的tirplet不是指triplet loss,而是指triplet的a,p,n三元组。
对于triplet loss我是不怎么看好的,因为它同时更新a,p,n,走了样本不均衡的老路。
但是a,p,n这个属性,确实极好的。比如我们上面提到的one-shot learning。采用triplet的一种简单方式就是把只有1张的id全部当成n,把有足够多张图片的id当成a,p。同时为了避免样本不均衡带来的影响,我们只对a进行梯度回传,对于p,n则不进行梯度回传。
我在我github项目里的Angular Triplet Loss(https://github.com/KaleidoZhouYN/Angular-Triplet-Loss)里面的MarginInnerProduct.cpp/.cu里面就实现了上面这种triplet的形式,我称其为easy triplet,感兴趣的读者可以浏览一下。
那么我们讲的东西到这里就结束了,第一次写文章,排版不是很会,希望不影响阅读。
为什么叫深度挖坑呢,因为这个东西确实比较坑了,都叫深度学习了,结果没有海量数据,还要和有限的数据做斗争。
最后,本人并非CS出身,上面这些都只是个人的一些感悟,如果发现了文章里的问题,欢迎在留言里面提出来,非常感谢。
===========================更新=========================
1.Q:为什么可视化会变成那种样子?
A:可以手动计算softmax loss,在保证特征可分的情况下那种情况softmax loss最小
2.Q :为什么质量差的图片feature norm小呢?
A :考虑两点:
1.质量差的图片难以被分类,一张模糊的图片(看不清五官)可能和所有的人都像,怎么样才能让他和所有的人都像呢?在空间上只能让他的feature norm小。
2.质量差的图片不能学习特征,比如一张戴了墨镜的人脸图片,如果给墨镜提取了一维特征的话,那么一个戴墨镜人脸和另外一个戴墨镜人脸的相似度就会提高。因为像遮挡这种,并非人的本质特征,所以我们不需要给他提特征,其feature norm自然就小。
3.Q:暴力进行Weight Norm是否会有什么不同?
A :见 https://github.com/wy1iu/sphereface ,对于梯度回传做了详细的分析
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用的更多相关文章
- 机器学习:PCA(人脸识别中的应用——特征脸)
一.思维理解 X:原始数据集: Wk:原始数据集 X 的前 K 个主成分: Xk:n 维的原始数据降维到 k 维后的数据集: 将原始数据集降维,就是将数据集中的每一个样本降维:X(i) . WkT = ...
- (转载)人脸识别中Softmax-based Loss的演化史
人脸识别中Softmax-based Loss的演化史 旷视科技 近期,人脸识别研究领域的主要进展之一集中在了 Softmax Loss 的改进之上:在本文中,旷视研究院(上海)(MEGVII Re ...
- 浅谈人脸识别中的loss 损失函数
浅谈人脸识别中的loss 损失函数 2019-04-17 17:57:33 liguiyuan112 阅读数 641更多 分类专栏: AI 人脸识别 版权声明:本文为博主原创文章,遵循CC 4.0 ...
- 人脸识别中的重要环节-对齐之3D变换-Java版(文末附开源地址)
一.人脸对齐基本概念 人脸对齐通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐 ...
- 从源码的角度看 React JS 中批量更新 State 的策略(下)
这篇文章我们继续从源码的角度学习 React JS 中的批量更新 State 的策略,供我们继续深入学习研究 React 之用. 前置文章列表 深入理解 React JS 中的 setState 从源 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 知物由学 | 基于DNN的人脸识别中的反欺骗机制
"知物由学"是网易云易盾打造的一个品牌栏目,词语出自汉·王充<论衡·实知>.人,能力有高下之分,学习才知道事物的道理,而后才有智慧,不去求问就不会知道."知物 ...
- 从源码的角度看 React JS 中批量更新 State 的策略(上)
在之前的文章「深入理解 React JS 中的 setState」与 「从源码的角度再看 React JS 中的 setState」 中,我们分别看到了 React JS 中 setState 的异步 ...
- 深度召回模型在QQ看点推荐中的应用实践
本文由云+社区发表 作者:腾讯技术工程 导语:最近几年来,深度学习在推荐系统领域中取得了不少成果,相比传统的推荐方法,深度学习有着自己独到的优势.我们团队在QQ看点的图文推荐中也尝试了一些深度学习方法 ...
随机推荐
- oracle sql insert插入字符&
最近遇到insert 语句插入&字符报弹出框,如下: sql: insert into test_ldl001 (ID, NAME) values (', '/test/test.do?act ...
- Python_BDD概念
BDD概念 全称 Behavior-driven development 中文 行为驱动开发 概念 是敏捷软件开发技术的一种,鼓励各方人员在一个软件项目里交流合作,包括开发人员.测试人员和非技术人员或 ...
- Qtcreator远程调试出现“The selected build of GDB does not support Python scripting.It cannot be used .."
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/aristolto/article/details/77370853 之前使用的是Qt4.7后来换 ...
- Delphi BASE64单元EncdDecd的修改
Delphi BASE64单元EncdDecd的修改 EncdDecd.pas两个函数声明: procedure EncodeStream(Input, Output: TStream);proced ...
- NLog用法
NLog是什么 NLog是一个基于.NET平台编写的类库,我们可以使用NLog在应用程序中添加极为完善的跟踪调试代码.NLog是一个简单灵活的.NET日志记录类库.通过使用NLog,我们可以在任何一种 ...
- daoliu平台:测试线路图
1.进行需求收集及分析 搜索关键字:导流平台 同类产品体验及熟悉 搞清楚,业务流.数据流.用户焦点 2.初步熟悉原型 初步熟悉.遍历原型, 初步进行测试需求分析 3.聆听及和权威的人进行沟通 测试人员 ...
- 软件:IIS上配置CGI
本文的内容是:在Windows7中的IIS6.1中配置CGI功能. 我先讲步骤,步骤全用图来说明,以方便技术还是不熟练的朋友,以下是在Windows7系统来完成的. 目录 一.安装IIS步骤: 0X0 ...
- 解决com.android.support版本冲突问题
原文:https://www.jianshu.com/p/0fe985a7e17e 项目中不同Module的support包版本冲突怎么办? 只需要将以下代码复制到每个模块的build.gradle( ...
- 手把手教你MyEclipseUML建模(上)
手把手教你MyEclipseUML建模(上) 转 https://blog.csdn.net/qq_37939251/article/details/83444359 1.用UML 1建模 MyEcl ...
- js事件函数中(ev)是什么鬼?
首先,从ev所在的位置就可以得知,ev是参数. 在ev中包含了事件触发时的函数, 比如: click事件的ev中包含着e.pageX,e.pageY keydown事件中包含着ev.keyCode等 ...