Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二、merge:通过键拼接列
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。
该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
参数介绍:
left和right:两个不同的DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y');
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况
案例1
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1

random = np.random.RandomState(0)
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2
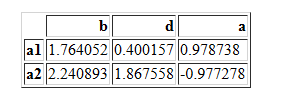
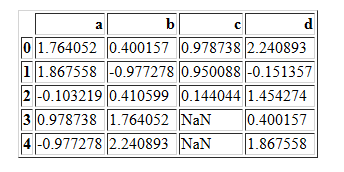
pd.merge(df1,df2)

pd.merge(df1,df2,how="outer")
案例2 默认按相同的列名键join
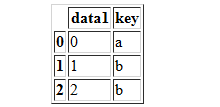
df3=pd.DataFrame({'key':['a','b','b'],'data1':range(3)})
df3
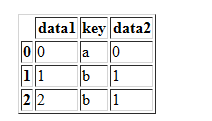
df4=pd.DataFrame({'key':['a','b','c'],'data2':range(3)})
df4

pd.merge(df3,df4)
案例三
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df1

df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
df2
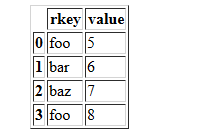
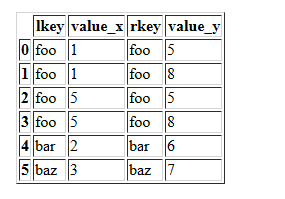
df1.merge(df2)

Merge df1 and df2 on the lkey and rkey columns. The value columns have the default suffixes, _x and _y,
df1.merge(df2,left_on="lkey",right_on="rkey")
>>> df1.merge(df2, left_on='lkey', right_on='rkey', suffixes=(False, False))
Traceback (most recent call last):
...
ValueError: columns overlap but no suffix specified:
Index(['value'], dtype='object')
Pandas中DataFrame数据合并、连接(concat、merge、join)之merge的更多相关文章
- Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一.concat:沿着一条轴,将多个对象堆叠到一起 concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, key ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- 将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy
将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy import pandas as pd from sqlalchemy import create_engine ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
- pandas中,dataframe 进行数据合并-pd.concat()
``# 通过数据框列向(左右)合并 a = pd.DataFrame(X_train) b = pd.DataFrame(y_train) # 合并数据框(合并前需要将数据设置成DataFrame格式 ...
随机推荐
- Reactor系列(一)基本概念
基本概念 视频讲解:https://www.bilibili.com/video/av78731069/ 关注公众号,坚持每天3分钟视频学习
- 在win7下安装PowerShell 5.0遇到的坑
升级安装 安装.NET Framework 4.6.2下载NDP462-KB3151800-x86-x64-AllOS-ENU.exe,进行安装 安装PowerShell 4.0(5.0依赖4.0) ...
- 15.sqoop数据从mysql里面导入到HDFS里面
表数据 在mysql中有一个库userdb中三个表:emp, emp_add和emp_contact 表emp id name deg salary dept 1201 gopal manager 5 ...
- PAT A1009 Product of Polynomials(25)
课本AC代码 #include <cstdio> struct Poly { int exp;//指数 double cof; } poly[1001];//第一个多项式 double a ...
- Linux就该这么学——新手必须掌握的命令之打包压缩与搜索命令组
tar命令 用途 : 对文件进行打包或者解压 格式 : tar [选项] [文件] 表 tar命令的参数及作用 参数 作用 -c 创建压缩文件 -x 解开压缩文件 -t 查看压缩包内有哪些文件 -z ...
- 今天遇到了不能创建mysql函数
今天用navicat 不能创建函数,查询了 MySQL函数不能创建,是未开启功能: mysql> show variables like '%func%'; +----------------- ...
- linux下安装anconda3
Liunx下安装anconda3其实特变简单,只需这几步骤 1. 首先要到网上下载一个ancoda3的安装包.然后在上传到linux上面即可 3. 是不是特别简单呢?哈哈
- 嵌套泛型参数IList<IList<Object>>如何传参
在调用第三方库的时候,有这么一个泛型参数,如下图: 按照经验,使用两个List嵌套声明变量即可: IList<IList<AnnotatedPoint2D>> outImag ...
- log4j rootLogger配置示例(log4j.properties)
log4j.rootLogger=INFO,commonLogger, log4j.appender.commonLogger=org.apache.log4j.ConsoleAppenderlog4 ...
- X86逆向9:通过关键常量破解
本章将讲解一下关于关键全局变量的一些内容,关键的全局变量对于软件的破解非常的有用,找到了关键全局变量并改写它同样可以完成完美爆破一个程序,这里我将使用CM小例子来讲解搜索关键变量的一些技巧,最后我们来 ...