利用Python进行数据分析_Pandas_数据结构
申明:本系列文章是自己在学习《利用Python进行数据分析》这本书的过程中,为了方便后期自己巩固知识而整理。
首先,需要导入pandas库的Series和DataFrame
In [21]: from pandas import Series,DataFrame In [22]: import pandas as pd
Series
是一种类似一维数组的对象,是一组数据与索引的组合。如果没设置索引,默认会加上。
In [23]: obj = Series([4,3,5,7,8,1,2]) In [24]: obj
Out[24]:
0 4
1 3
2 5
3 7
4 8
5 1
6 2
dtype: int64
自定义索引
In [28]: obj = Series([4,3,2,1],index=['a','b','c','d']) In [29]: obj
Out[29]:
a 4
b 3
c 2
d 1
dtype: int64
获取values和index的值
In [30]: obj.index
Out[30]: Index(['a', 'b', 'c', 'd'], dtype='object') In [31]: obj.values
Out[31]: array([4, 3, 2, 1], dtype=int64)
通过索引获取Series的元素值
In [32]: obj['c']
Out[32]: 2
还能当字典
In [33]: if 'a' in obj:
...: print("a在对象里!")
...:
a在对象里!
也能将字段转换成Series对象(有序)
In [56]: data = {'a':1,'b':2,'c':3,'d':4}
In [57]: obj = Series(data)
In [58]: obj
Out[58]:
a 1
b 2
c 3
d 4
dtype: int64
In [59]: data = {'a':1,'b':2,'d':3,'c':4}
In [60]: obj = Series(data)
In [61]: obj
Out[61]:
a 1
b 2
c 4
d 3
dtype: int64
字典data中,我加一个index会怎样?
In [72]: datas = {'a','b','d','c','e'}
In [73]: objs = Series(data,index=datas)
In [74]: objs
Out[74]:
c 4.0
e NaN
b 2.0
d 3.0
a 1.0
dtype: float64
isnull 检测缺失
In [75]: pd.isnull(objs)
Out[75]:
c False
e True
b False
d False
a False
dtype: bool
notnull 检测不缺失
In [76]: pd.notnull(objs)
Out[76]:
c True
e False
b True
d True
a True
dtype: bool
Series的检测缺失方法
In [78]: objs.isnull()
Out[78]:
c False
e True
b False
d False
a False
dtype: bool In [79]: objs.notnull()
Out[79]:
c True
e False
b True
d True
a True
dtype: bool
DataFrame
DataFrame 是表格型数据结构,含有一组有序的列。
In [86]: data = {'class':['语文','数学','英语'],'score':[120,130,140]}
In [87]: frame = DataFrame(data)
In [88]: frame
Out[88]:
class score
0 语文 120
1 数学 130
2 英语 140
In [95]: frame = DataFrame(data) In [96]: frame
Out[96]:
class score
0 语文 120
1 数学 130
2 英语 140
按指定序列进行排序
In [98]: DataFrame(data,columns={'score','class'})
Out[98]:
score class
0 120 语文
1 130 数学
2 140 英语
NaN补充
In [99]: DataFrame(data,columns={'score','class','teacher'})
Out[99]:
score class teacher
0 120 语文 NaN
1 130 数学 NaN
2 140 英语 NaN
给NaN批量赋值
方法一:
In [107]: frame['teacher'] = '周老师' In [108]: frame
Out[108]:
score class teacher
0 120 语文 周老师
1 130 数学 周老师
2 140 英语 周老师
方法二:
In [110]: frame.teacher = '应老师' In [111]: frame
Out[111]:
score class teacher
0 120 语文 应老师
1 130 数学 应老师
2 140 英语 应老师
通过字典标记的方式,可以将DataFrame的列转成一个Series
In [112]: frame.teacher
Out[112]:
0 应老师
1 应老师
2 应老师
Name: teacher, dtype: object
将列表或数组赋值给Frame的某一列
In [114]: val = Series(['周老师','应老师','小周周'],index=[0,1,2]) In [115]: frame['teacher'] = val In [116]: frame
Out[116]:
score class teacher
0 120 语文 周老师
1 130 数学 应老师
2 140 英语 小周周
为Frame创建一个新的列
In [125]: frame['yesorno'] =0 In [126]: frame
Out[126]:
score class teacher yesorno
0 False 语文 周老师 0
1 True 数学 应老师 0
2 False 英语 小周周 0
创建一个新列,并赋值一个布尔类型的Series
In [119]: frame['yesorno'] = frame.teacher == '应老师' In [120]: frame
Out[120]:
score class teacher yesorno
0 False 语文 周老师 False
1 True 数学 应老师 True
2 False 英语 小周周 False
删除Frame的列
In [122]: del frame['yesorno'] In [123]: frame
Out[123]:
score class teacher
0 False 语文 周老师
1 True 数学 应老师
2 False 英语 小周周
嵌套字典
外层字典的键作为Frame的列,内层键作为行索引。
In [10]: from pandas import DataFrame,Series
In [11]: data = {'a':{'aa':2,'aaa':3},'b':{'bb':4,'bbb':5}}
In [12]: frame = DataFrame(data)
In [13]: frame
Out[13]:
a b
aa 2.0 NaN
aaa 3.0 NaN
bb NaN 4.0
bbb NaN 5.0
索引对象
pandas的索引index其实也是一个对象。由index类继承而衍生出来的还有Int64Index\MultiIndex\DatetimeIndex\PeriodIndex等。
In [31]: frame.index
Out[31]: Index(['aa', 'aaa', 'bb', 'bbb'], dtype='object')
index对象有以下属性(方法):
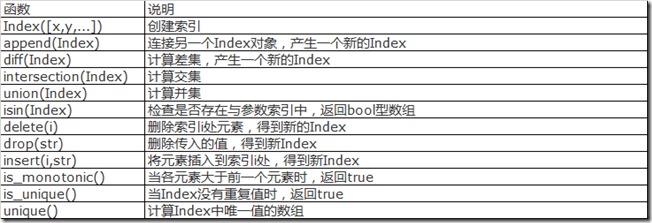
insert(i,str)属性的使用案例:
In [31]: frame.index
Out[31]: Index(['aa', 'aaa', 'bb', 'bbb'], dtype='object') In [32]: frame.index.insert(5,'fff')
Out[32]: Index(['aa', 'aaa', 'bb', 'bbb', 'fff'], dtype='object')
利用Python进行数据分析_Pandas_数据结构的更多相关文章
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- 利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 读取excel数据 import pandas as pd import ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python进行数据分析_Pandas_基本功能
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 第一 重新索引 Series的reindex方法 In [15]: obj = ...
- 利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑
1 合并数据集 pandas.merge pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, le ...
- 利用Python进行数据分析_Pandas_绘图和可视化_Matplotlib
1 认识Figure和Subplot import matplotlib.pyplot as plt matplotlib的图像都位于Figure对象中 fg = plt.figure() 通过add ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
随机推荐
- [Codeforces1148C]Crazy Diamond——构造
题目链接: [Codeforces1148C]Crazy Diamond 题目大意: 给出一个$1\sim n$的排列要求将其排序,每次能交换两个位置的数当且仅当这两个位置下标差的绝对值大于等于$\f ...
- vue怎么将一个组件引入另一个组件?
项目是由的vue-cli搭建 1.这里有两个组件,需求是把newComponents.vue里面的东西引入到helloWorld里面 2.index.js里面的配置 3.newComponents里面 ...
- combobox放入数据
页面 <th width="15%">国际分类号</th><td width="30%"> <select cla ...
- Vue-cli 构建项目后 npm run build 如何在本地运行查看
当你在本地直接打开index.html 你会发现了一丢丢404,这时候你有两个办法解决问题: 1:改变路径为相对路径. 在config 文件夹中index.js的 build对象里, 把 assets ...
- 查看日志tail命令
打开终端,连接jboss: 命令: tail -f -n 500 /var/log/wildfly/wrapper.log
- elasticsearch自定义动态映射
https://www.elastic.co/guide/cn/elasticsearch/guide/current/custom-dynamic-mapping.html如果你想在运行时增加新的字 ...
- Linux中系统状态检测命令
1.ifconfig用于获取网卡配置与网络状态等信息,格式为:ifconfig [网络设备] [参数] 2.uname命令用于查看系统内核版本等信息,格式为:uname [-a] 查看系统的内核名称. ...
- UVA:1600 巡逻机器人
机器人要从一个m*n(m和n的范围都在1到20的闭区间内)的网格的左上角(1,1)走到右下角(m,n).网格中的一些格子是空地,用0表示,其它格子是障碍,用1表示.机器人每次可以往四个方向走一格,但不 ...
- python笔记7 logging模块 hashlib模块 异常处理 datetime模块 shutil模块 xml模块(了解)
logging模块 日志就是记录一些信息,方便查询或者辅助开发 记录文件,显示屏幕 低配日志, 只能写入文件或者屏幕输出 屏幕输出 import logging logging.debug('调试模式 ...
- leetcode 127. Word Ladder、126. Word Ladder II
127. Word Ladder 这道题使用bfs来解决,每次将满足要求的变换单词加入队列中. wordSet用来记录当前词典中的单词,做一个单词变换生成一个新单词,都需要判断这个单词是否在词典中,不 ...