# Python3微博爬虫[requests+pyquery+selenium+mongodb]
Python3微博爬虫[requests+pyquery+selenium+mongodb]
大数据时代,数据的获取对是研究的基础,而获取海量的数据自然不能通过人工获取,爬虫因运而生。微博作为新时代国内火爆的社交媒体平台,拥有大量用户行为和商户数据,学会通过爬虫获取所需数据将是将来研究学者的必备技能。由于微博的反爬取措施较为完善,PC端的微博API限制太多,不易于爬虫获取数据,本次选择爬取手机端的彩版微博,手机端含有所需的所有数据,并且对爬虫较为友好。
程序在Ubuntu18.04.5下编写,Python版本为3.6.7,通过设置请求头信息和使用代理IP和代理账号,对爬虫进行包装,使用selenium驱动Chrome完成页面的获取,通过pyquery解析页面获取数据,并且存入非关系型数据MongoDB。
主要技术
Requests库:第三方请求库,用于抓取页面,模拟浏览器向服务器发送请求。
Selenium库:一个自动化测试工具,配合Chrome浏览器和ChromeDrive驱动来模拟浏览器完成特定的动作,如点击,下拉等。
Pyquery库:一个强大的解析库,抓取网页代码之后,配合CSS选择器从网页中提取需要的信息。
MongoDB数据库:一种非关系型数据库,基于键值对,数据之间没有耦合性,性能高,存储形式类似JSON对象,非常灵活。
PyMongo库:存储库,用于实现和MongoDB之间进行数据交互。
Python线程:线程是操作系统能够进行运算调度的最小单位,被包含在进程之中,一条线程指的是进程中一个单一顺序的控制流,程序中通过推迟线程实现等待效果。
需要代理IP和代理账号,IP代理最好不要使用免费的,例如西刺,免费代理多数挂的快,不稳定而且速度慢,速度慢就无法再超时设置的规定时间内加载出网页,导致出现异常,程序终止
微博账号购买:http://www.xiaohao.fun/或者http://www.xiaohao.live/,1毛5一个号

站点分析
首先观察URL,可以发现在页面跳转过程中有一串数字保持不变,这串数字就是用户的唯一标识符,也就是用户的uid,一个uid可以唯一确定一个用户。

用户的微博数,关注数,粉丝数存在于类名为tip2的div标签下的类名为tc的span标签中。
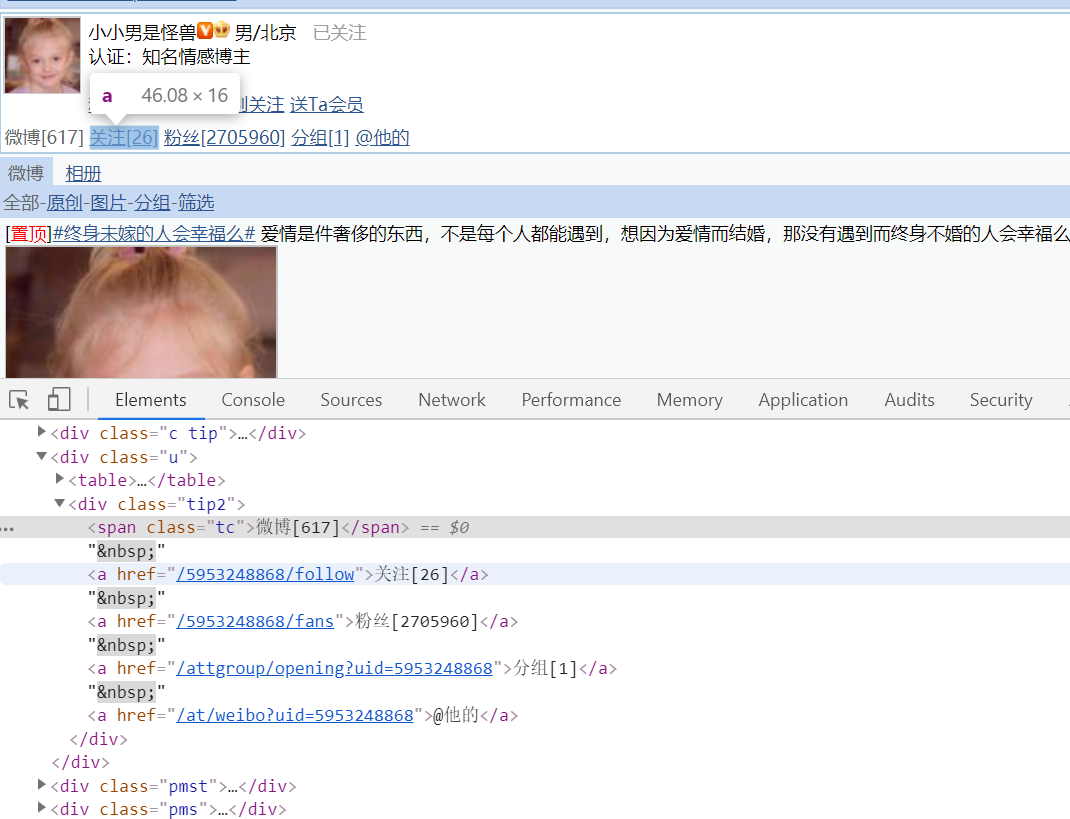
每条微博的信息存在于类名为c的div标签中。
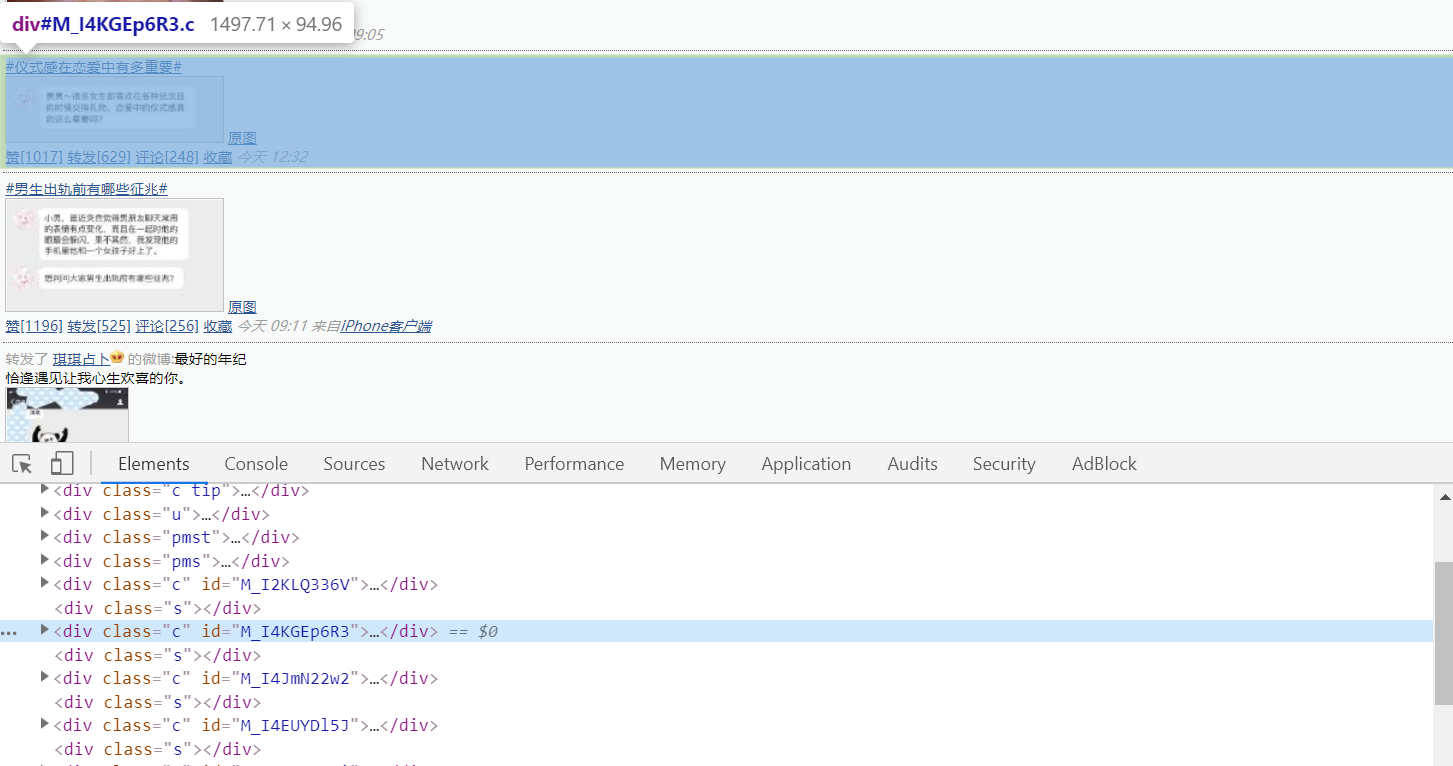
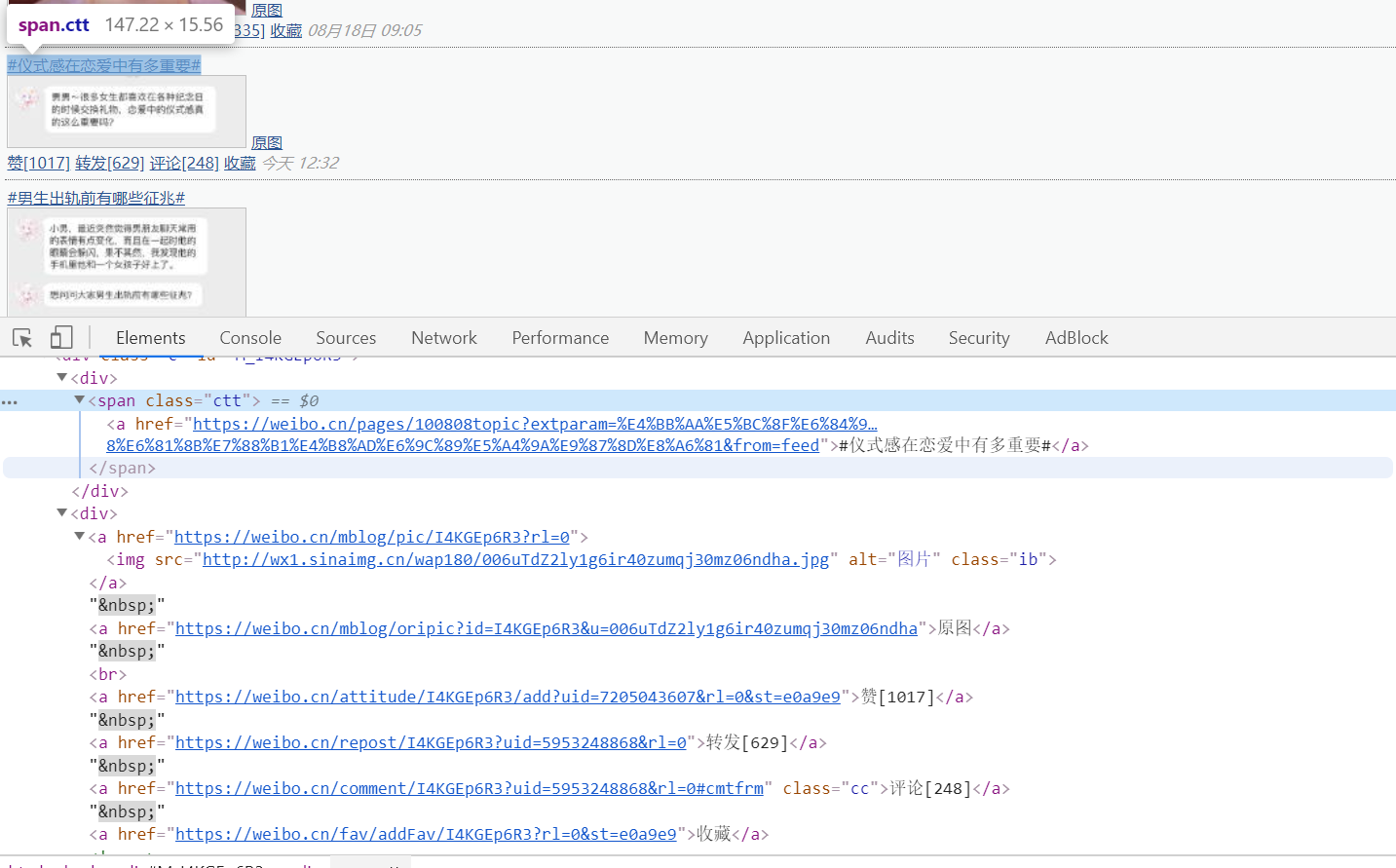
类名为c的div标签下分有两个div标签,一个用来显示文字,一个用来显示图片。
在标识为pagelist的div标签下有总页数的信息,获取总页数用于循环翻页,爬取所有微博信息。
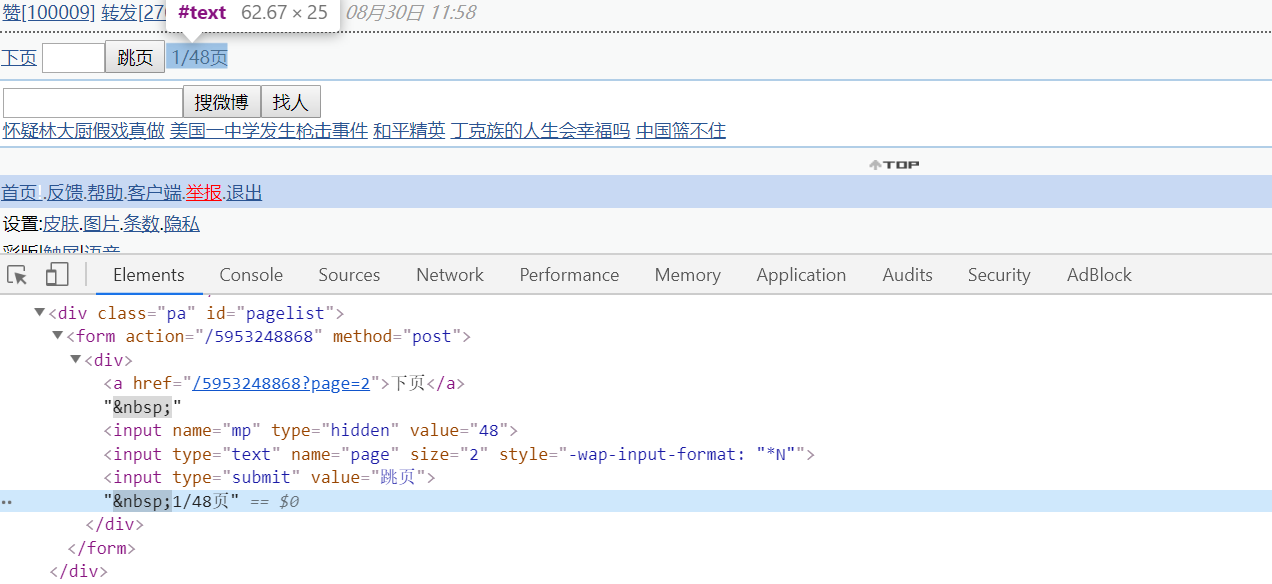
执行翻页操作观察发现URL只有尾部page变量有变化,使用page变量可以达到翻页操作。


进入用户的详情页面,可以发现只要在原来的URL下加入info的后缀,即可访问用户的详情页面。
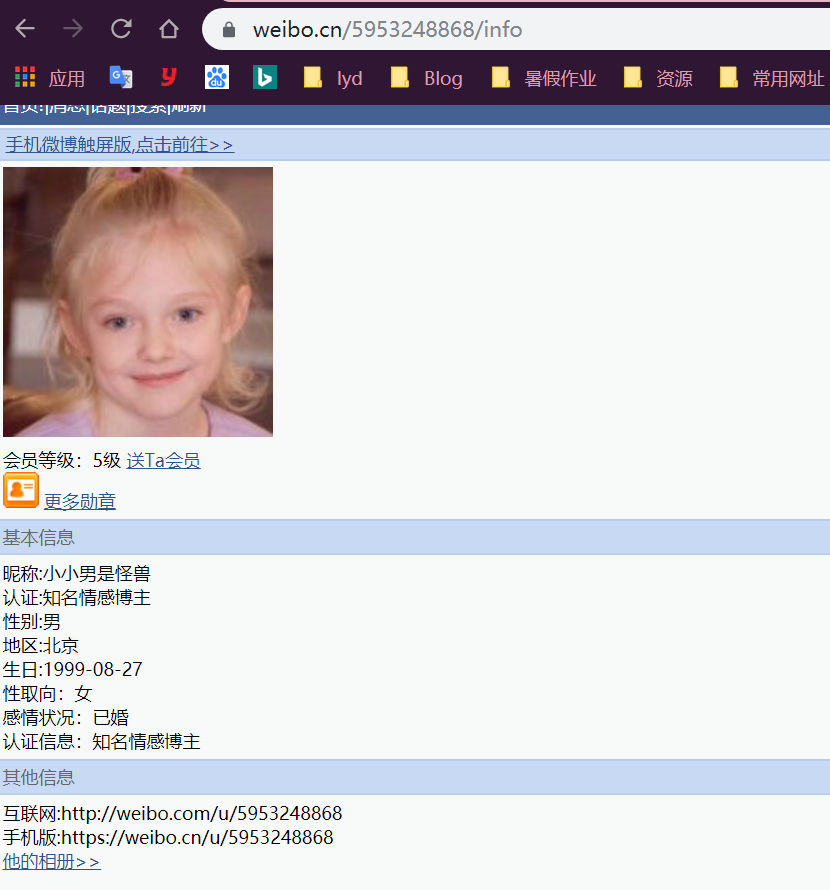
在用户详情页面相应标签内可以得到用户的所有信息。
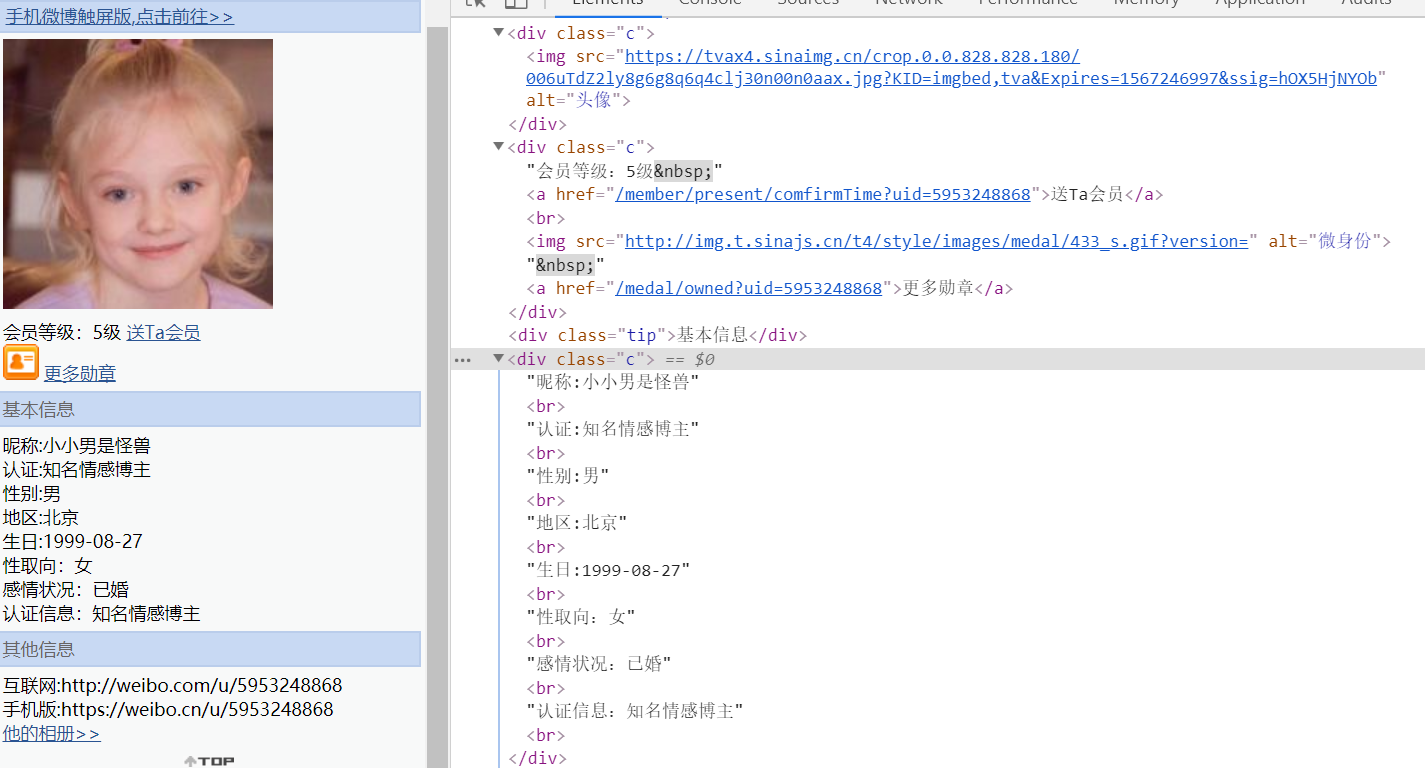
程序流程图
ProcessOn在线绘制
编程实现
数据库选择
数据库使用非关系型数据库MongoDB,基于键值对,数据之间没有耦合性,性能高,存储形式类似JSON对象,非常灵活。对于爬虫的数据存储来说,一条数据可能存在某些字段提取失败而缺失的情况,可能是由于网络问题,可能是由于有些字段本来就没有提供,而且字段可能随时调整。另外,数据之间还存在嵌套关系,如果使用关系型数据库存储,一是需要提前建表,二是如果存在数据嵌套关系的话,需要进行序列化操作才可以存储,非常不方便,而如果使用非关系型数据库,就可以避免一些麻烦,更加简单高效。
其中文本信息及图片URL全部存储在weibo数据库中,数据库下以用户昵称为名称新建集合,集合里面每一条数据以微博发布时间命名,图片无法存入数据库,所以单独下载保存在以用户昵称命名的文件夹中,图片名称也为微博发布时间,方便从某一条微博找到该微博对应的图片。
client=pymongo.MongoClient(host=’localhost’,port=27017)
db=client.weibo #指定数据库
id = input(‘请输入微博用户id:’)
global collection
collection=db[id]
代理IP测试
微博对爬虫的限制较为严格,为防止在调试过程中频繁的访问微博服务器而识别为爬虫访问导致本地ip被封,一般使用代理ip。考虑到大多数免费ip使用人数过多,速度慢,易被检测,本程序使用芝麻http代理的付费ip,通过访问一个可以测试访问ip的网站,一方面检测代理ip的速度,另一方面可以测试代理ip是否使用成功,同时代码中加入的异常处理模块。
# 测试代理IP
def check_ip():
print(r'正在检查代理IP是否可用...')
# 测试ip是否可用
proxies = {
'http': proxy,
'https': proxy,
}
print('当前测试的代理IP为:' + proxy)
print('...')
print('测试结果:')
try:
# 超时设置,避免使用不稳定的IP
r = requests.get('http://ip111.cn/',
proxies=proxies,timeout=3)
r.encoding = 'utf-8'
doc = pq(r.text)
# print(doc)
ip = doc('body > div.container '
'> div.card-deck.mb-3.text-center')
ip = str(ip.find('div:nth-child(1) > div.card-header').text()) + \
" : " + \
str(ip.find('div:nth-child(1) > div.card-body > p:nth-child(1)').text())
print(ip)
print('ip可正常使用...')
except:
print("抱歉,此IP无法使用,请更换IP重试")
os._exit(0)
模拟登录
模拟登录板块使用selenium配合ChromeDrive驱动Chrome完成相关操作,为了应对微博的反爬取措施,设置了代理和伪装的请求头,为避免账号被封,使用代理账号爬取所需信息。一般网站为了减少服务器压力,会对访问速度过快的用户进行封ip操作,因此在程序中适当的加入了推迟线程操作,通过推迟线程,实现等待操作,使爬虫的操作更像是人类。
判断是否登录成功是通过尝试获取用户的详情页面,如果登录失败,尝试获取详情页面会跳转到登录页面,此时能返回的源代码中可以找到类名为login-wrapper的div标签,如果找到此标签则表示当前代理ip节点速度过慢或者生命周期将至,提示更换代理ip,关闭浏览器,并且直接结束程序。
至于这里为什么不考虑递归调用登录函数,是因为此次的登录失败是由代理ip节点异常导致的,递归调用重新登录很大可能还是登录失败,即使登录成功,之后获取信息的时候也会出现由于网络问题而导致获取页面失败的情况,所以选择提示更换ip并且直接结束程序。
如果使用的本地ip,而非代理ip,则考虑递归调用重新登录才是更好的选择,本地ip登录失败很有可能是某一刻的网络问题,恰好在登录的时候碰到了网络堵塞问题,在后续获取信息的操作中则不会受到影响。
def log_in():
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument("--proxy-server={0}".format(proxy))#设置代理
chromeOptions.add_argument('lang=zh_CN.UTF-8')
chromeOptions.add_argument(
'User-Agent:"Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/76.0.3809.100 Safari/537.36"'
)
global browser
browser = webdriver.Chrome(chrome_options=chromeOptions)
try:
print(u'正在登陆新浪微博手机端...')
#给定登陆的网址
url = 'https://passport.weibo.cn/signin/login'
browser.get(url)
time.sleep(3)
#找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('2vg58g0y3b@touzi580.com')#输入自己的账号
#找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('91ih6d7j')
#点击登录
browser.find_element_by_css_selector('#loginAction').click()
#这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个验证码,
#下图有,通过程序执行的话会有点麻烦,这里就手动
time.sleep(15)
except:
print('登录出现错误,请检查网速或者代理IP是否稳定!!!')
os._exit(0)
browser.get('http://weibo.cn/' + id + '/info')
doc = pq(browser.page_source, parser='html')
if doc.find('.login-wrapper'):
print('登录出现错误,请检查网速或者代理IP是否稳定!!!')
browser.close()
os._exit(0)
print('完成登陆!')
获取用户详细信息
通过观察URL发现,在微博域名后面添加用户uid转到用户的主页,在用户uid后面添加info字段转到用户详细信息页面。通过这个信息可以很容易获取到用户详情页面的源代码。本模块中有两个地方可能出现异常,一个是请求用户详情页面,请求页面可能因为网路问题像网速慢等情况,或者代理ip节点寿命到期或者节点不稳定的情况出发异常,这些异常暗示着网络中断,另一个是存储进MongoDB时会出现异常,这种异常可以暂时跳过,获取后面的数据,而无需从头开始执行程序。
本模块的处理是通过先构造一个空字典用于临时存储信息,通过驱动Chrome浏览器请求页面,并返回页面源代码,通过网页源码构造pyquery对象,进行源码的解析提取数据提取数据使用css选择器。
def get_basic_info(id):
dict = {
'_id':'基本信息'
}
global url
url = 'http://weibo.cn/' + id
try:
browser.get(url + '/info')#这里可能出现获取不到页面的情况
except TimeoutError:
print("请求超时,节点可能不太稳定,请跟换节点")
os._exit(0)
except:
print("出现错误,错误uid")
os._exit(0)
doc = pq(browser.page_source,parser='html')
if doc.find('.tm'): j=1
else : j=0
info = doc('body > div:nth-child('+str(6+j)+')').text()
nickname = str(info).split('\n', 1)[0]
print(nickname)
dict[nickname.split(':')[0]] = nickname.split(':')[1]
#创建存储该用户图片的文件夹,命名为用户昵称
make_dir(dict[nickname.split(':')[0]])
dict['uid'] = id
other_info = str(info).split('\n', 1)[1].strip()[:-5]
img = doc('body > div:nth-child('+str(3+j)+')> img').attr('src')
img = '头像:' + str(img)
print(img)
dict[img.split(':',1)[0]] = img.split(':',1)[1]
rank = doc('body > div:nth-child('+str(4+j)+')').text()
rank = str(rank).split('\n', 1)[0].split(':')[1].strip()[:2]
rank = '会员等级:' + rank
print(rank)
dict[rank.split(':')[0]] = rank.split(':')[1]
other_info=other_info.replace(':',':')
print(other_info)
other_info=other_info.strip()
for a in other_info.split('\n'):
dict[a.split(':')[0]]=a.split(':')[1]
browser.get(url)
doc = pq(browser.page_source, parser='html')
follow_and_fans = str(doc('body > div.u > div').text()).strip().split('分')[0]
follow_and_fans=follow_and_fans.strip() #去处前后空格
for a in follow_and_fans.split():
t = a.split('[')[1]
dict[a.split('[')[0]+'数']=t.split(']')[0]
if save_image(nickname.split(':')[1]+'的头像',dict[img.split(':',1)[0]]):
print(nickname.split(':')[1]+'的头像下载成功')
try:
collection.insert_one(dict)
except:
print('基本信息存储进mongodb出现错误')
os._exit(0)
finally:
tot_page = doc('#pagelist > form > div').text()
tot_page = str(tot_page).split('/')[1][:-1]
return tot_page
获取用户全部微博
通过研究源码可以发现,微博存在类名为c的div标签中,通过源码中这种标签的数量可以得到每一页的微博数,其中要去除第一个div标签和倒数前两个标签。在每一个获取的标签中可以获取微博的文字和图片,其中图片的有无会影响到赞数,转发数和评论数的获取,如果获取到的图片不为空,则下载图片,这里使用if-else处理。图片的下载,源码中提供了两种下载地址,原图的下载地址需要传递cookies,而源码中还提供了流畅图的下载地址,源码中的原图的下载地址点击之后下载URL发生变化,通过和流畅图的URL下载地址相比较,发现只要把流畅图的下载地址中的wap180转化为large即可获取到原图的下载地址,这里巧妙的获取到了原图。通过修改URL可以遍历所有微博,获取数据,每次获取完一页的数据之后,推迟线程0.5s,模拟人工查看微博时出现的网络等待时间。
def get_weibo(tot_page):
for k in range(1,int(tot_page)+1):
browser.get(url+'?page='+str(k))
doc=pq(browser.page_source,parser='html')
c = doc('.c')
lens = len(c)
c = c.items()
i = 0;j=1
for cc in c:
dict = {}
i = i + 1
if (i == 1): continue
if (i == lens - 1): break
print("正在爬取第"+str(k)+"页,第"+str(j)+"条微博...")
dict['_id'] = cc.find('div > span.ct').text()
dict['info'] = cc.find('.ctt').text()
dict['img'] = cc.find('div:nth-child(2) > a:nth-child(1) > img').attr('src')
if dict['img']:
dict['img']=dict['img'].replace('wap180', 'large')
if save_image(dict['_id'], dict['img']):
print("微博图片下载成功...")
dict['active'] = str(cc.find('div:nth-child(2) > a:nth-child(4)').text()) + ',' + str(cc.find('div:nth-child(2) > a:nth-child(5)').text()) + ',' + str(cc.find('.cc').text())
else:
dict['active'] = str(cc.find('div > a:nth-child(3)').text()) + ',' + str(cc.find('div > a:nth-child(4)').text()) + ',' + str(cc.find('.cc').text())
try:
collection.insert_one(dict)
print("第" + str(k) + "页,第" + str(j) + "条微博存储成功...")
except:
print("第" + str(k) + "页,第" + str(j) + "条微博存储失败!!!")
j = j + 1
print('')
time.sleep(0.5)
运行结果
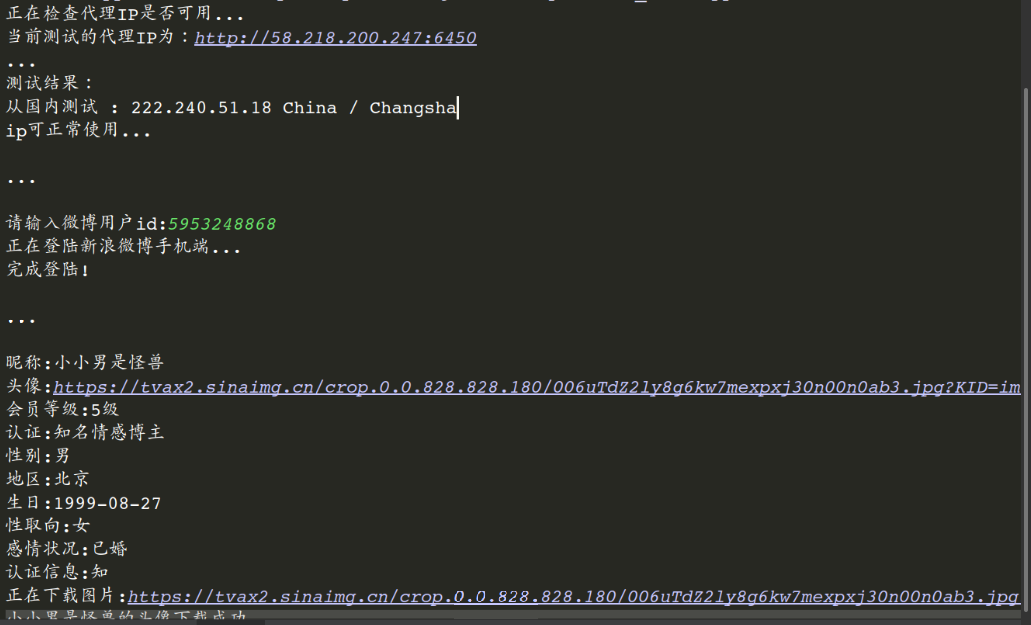
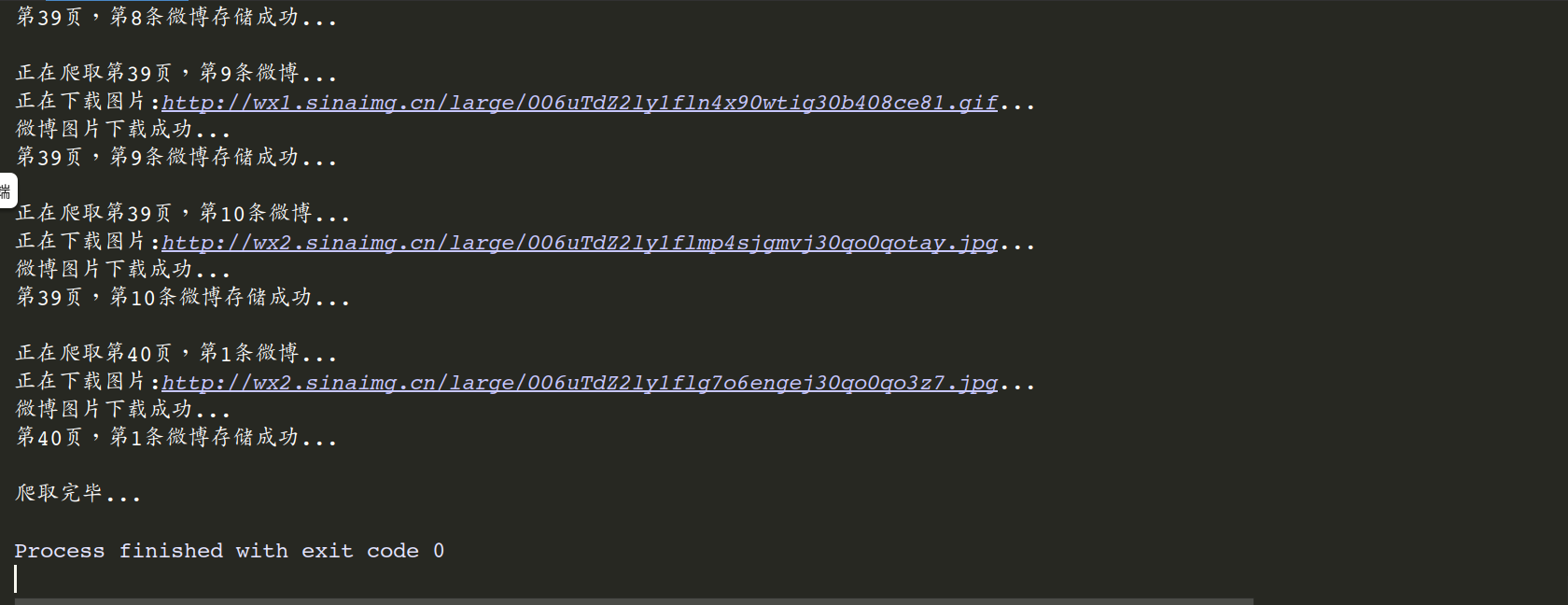

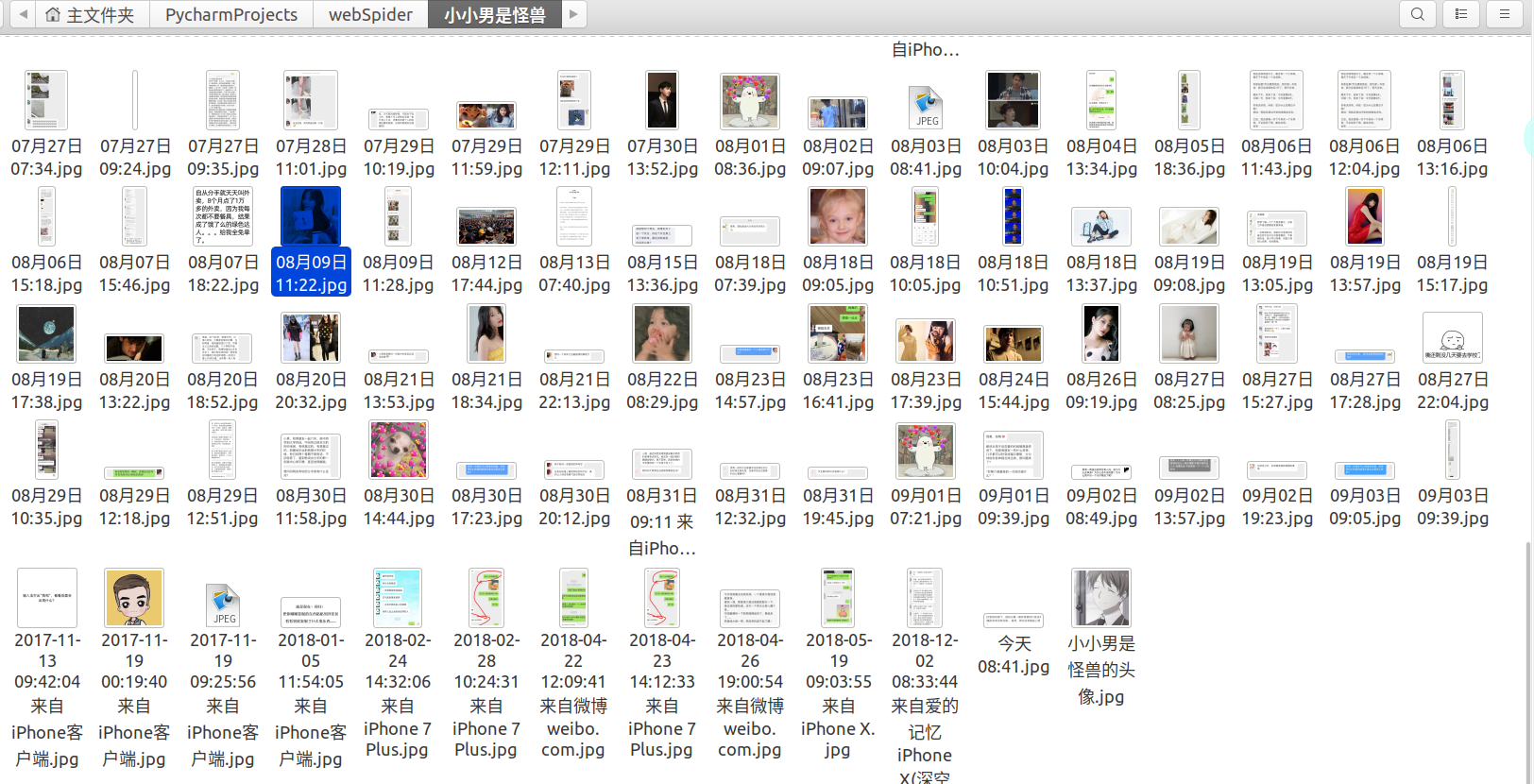
由于robo 3t查询本身有bug,只能显示前50条记录,可以MongoDB命令行下使用查询命令查看所有数据。

# Python3微博爬虫[requests+pyquery+selenium+mongodb]的更多相关文章
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- python3.7爬虫:使用Selenium带Cookie登录并且模拟进行表单上传文件
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_142 前文再续,书接上一回,之前一篇文章我们尝试用百度api智能识别在线验证码进行模拟登录:Python3.7爬虫:实时api(百 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- Python3 常用爬虫库的安装
Python3 常用爬虫库的安装 1 简介 Windows下安装Python3常用的爬虫库:requests.selenium.beautifulsoup4.pyquery.pymysql.pymon ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- python3网络爬虫系统学习:第一讲 基本库urllib
在python3中爬虫常用基本库为urllib以及requests 本文主要描述urllib的相关内容 urllib包含四个模块:requests——模拟发送请求 error——异常处理模块 pars ...
随机推荐
- 数据结构实验之链表八:Farey序列(SDUT 3331)
#include <bits/stdc++.h> using namespace std; typedef struct node { int data2; int data1;//mu ...
- 腾讯域名防封 微信/QQ域名检测,域名防封的原理
微信屏蔽网页的依据是什么?明面上的原因是网页内容有诱导.诈骗等不和谐的内容时候,被用户举报就会封闭.实际上这只是表面现象,因为我们能明确的感受到不同的阶段,同样的内容,被封杀的频率差别很大的,也就是说 ...
- 服务器多进程powershell导致服务器瘫痪问题解决
1.公司服务器多次无法访问,经查多由于开启了多个powershell进程,网上查询是被挖矿了,可通过将powershell应用程序重命名解决. 2.然而重命名的时候发现需要trustedInstall ...
- Java和python中的面向对象
Python与Java中的示例类 Java类是在与类同名的文件中定义的.因此,必须将该类保存在一个名为Car.java的文件中.每个文件中只能定义一个类. public class Car { pri ...
- airflow自动生成dag
def auto_create_dag(): dag_list=[] dag = DAG() dag_list.append(dag) return dag_list dags = auto_crea ...
- Leetcode题目94.二叉树的中序遍历(中等)
题目描述: 给定一个二叉树,返回它的中序遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗? 思路解析: 1 ...
- LeetCode 20. 有效的括号(Valid Parentheses )
题目描述 给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效. 有效字符串需满足: 左括号必须用相同类型的右括号闭合. 左括号必须以正确的顺序闭合. 注意空字 ...
- .net reflector
https://www.red-gate.com/dynamic/products/dotnet-development/reflector/download https://github.com/s ...
- android data binding jetpack VIII BindingConversion
android data binding jetpack VIII BindingConversion android data binding jetpack VII @BindingAdapter ...
- <JavaScript>如何阅读《JavaScript高级程序设计》(一)
题外话 最近在看<JavaScript高级程序设计>这本书,面对着700多页的厚书籍,心里有点压力,所以我决定梳理一下..探究一下到底怎么读这本书.本书的内容好像只有到ES5...所以只能 ...