mycat水平分表
和垂直分库不同,水平分表,是将那些io频繁,且数据量大的表进行水平切分。
基本的配置和垂直分库一样,我们需要改的就是我们的
schema.xml和rule.xml文件配置(server.xml不用做任何修改)
除此之外,我们还需要在两个分片数据库服务器上建立分片用的数据库10.0.4.181上建立(orderdb01,orderdb02),10.0.4.183上建立(orderdb03,orderdb04)
现在我们对配置文件进行配置。
其中schema.xml这样配置。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="imooc_db" checkSQLschema="false" sqlMaxLimit="100">
<table name="mytest" primaryKey="id" dataNode="dn1" />
<table name="testfp" primaryKey="id" dataNode="dn2" />
<table name="order_list" primaryKey="id" dataNode="orderdb01,orderdb02,orderdb03,orderdb04" rule="order_list" />
</schema>
<dataNode name="dn1" dataHost="mysql4181" database="imooc_db" />
<dataNode name="dn2" dataHost="mysql4183" database="imooc_db" />
<dataNode name="orderdb01" dataHost="mysql4181" database="orderdb01" />
<dataNode name="orderdb02" dataHost="mysql4181" database="orderdb02" />
<dataNode name="orderdb03" dataHost="mysql4183" database="orderdb03" />
<dataNode name="orderdb04" dataHost="mysql4183" database="orderdb04" />
<dataHost name="mysql4181" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>select user()</heartbeat>
<writeHost host="10.0.4.181" url="10.0.4.181:3306" user="im_mycat" password="123456"></writeHost>
</dataHost>
<dataHost name="mysql4183" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>select user()</heartbeat>
<writeHost host="10.0.4.183" url="10.0.4.183:3306" user="im_mycat" password="123456"></writeHost>
</dataHost>
</mycat:schema>
rule.xml这样配置
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="order_list">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<property name="count">4</property>
</function>
</mycat:rule>
配置好后,进行mycat的重启。
mycat restart
登录mycat
mysql -uapp_imooc -p123456 -h10.0.4.180 -P8066
插入数据。
mysql> insert into order_list(id,order_name,order_type) values(1,'order01',1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into order_list(id,order_name,order_type) values(2,'order01',1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into order_list(id,order_name,order_type) values(3,'order01',1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into order_list(id,order_name,order_type) values(4,'order01',1);
Query OK, 1 row affected (0.01 sec)
mysql> insert into order_list(id,order_name,order_type) values(5,'order01',1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into order_list(id,order_name,order_type) values(6,'order01',1);
Query OK, 1 row affected (0.01 sec)
mysql> insert into order_list(id,order_name,order_type) values(7,'order01',1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into order_list(id,order_name,order_type) values(8,'order01',1);
Query OK, 1 row affected (0.01 sec)
mysql> insert into order_list(id,order_name,order_type) values(9,'order01',1);
Query OK, 1 row affected (0.01 sec)
mysql> insert into order_list(id,order_name,order_type) values(10,'order01',1);
Query OK, 1 row affected (0.00 sec)
我们可以看到,我们在mycat上插入的数据,最终通过对id的取模算法,分别插入到了orderdb01,orderdb02,orderdb03,orderdb04
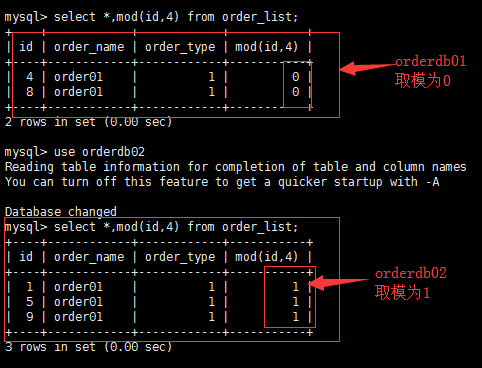
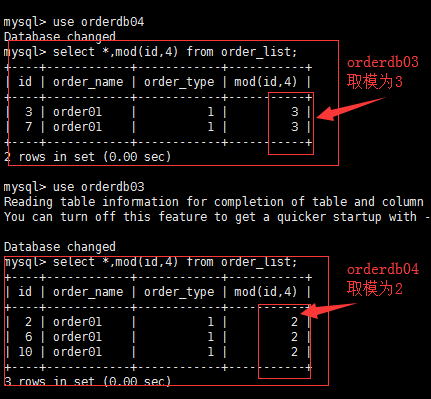
通过以上结果,我们可以看到,数据被平均的分配到了4各数据库中。
但是,做到这里还不算完,并不能用于生产环境,因为还有很多问题,比如全局自增主键的问题和联合查询的问题。上面我的实例之所以分配的很平均是因为,我在插入的时候规定了主键值。所以后端的四个数据库中的全部数据中没有主键重复的,
如果我不规定主键,则order_list中可能出现四个id为1的记录,或四个id为2的记录。
mycat水平分表的更多相关文章
- mycat - 水平分表
相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中.水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分 ...
- mysql中的优化, 简单的说了一下垂直分表, 水平分表(有几种模运算),读写分离.
一.mysql中的优化 where语句的优化 1.尽量避免在 where 子句中对字段进行表达式操作select id from uinfo_jifen where jifen/60 > 100 ...
- mysql 水平分表技术
这里做的是我的一个笔记. 水平分表比较简单, 理解就是: 合并的表使用的必须是MyISAM引擎 表的结构必须一致,包括索引.字段类型.引擎和字符集 数据表 user1 CREATE TABLE `us ...
- 玩转SpringBoot之整合Mybatis拦截器对数据库水平分表
利用Mybatis拦截器对数据库水平分表 需求描述 当数据量比较多时,放在一个表中的时候会影响查询效率:或者数据的时效性只是当月有效的时候:这时我们就会涉及到数据库的分表操作了.当然,你也可以使用比较 ...
- MySQL常见水平分表技术方案
根据经验,Mysql表数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉:水平分表能够很大程度较少这些压力. 1.按时间分表 这种分表方式有一定的局限性,当数据有较强的实效 ...
- mysql使用MRG_MyISAM(MERGE)实现水平分表
在MySQL中数据的优化尤其是大数据量的优化是一门很大的学问,当然其它数据库也是如此,即使你不是DBA,做为一名程序员掌握一些基本的优化信息,也可以让你在自己的程序开发中受益匪浅.当然数据库的优化有很 ...
- mysql数据库的水平分表与垂直分表实例讲解
mysql语句的优化有局限性,mysql语句的优化都是围绕着索引去优化的,那么如果mysql中的索引也解决不了海量数据查询慢的状况,那么有了水平分表与垂直分表的出现(我就是记录一下自己的理解) 水平分 ...
- TDSQL MySQL版基本原理-水平分表 读写分离 弹性扩展 强同步
TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分.Shared Nothing 架构的分布式数据库.TDSQL MySQL版 即业务获取的是完整的逻辑库 ...
- Sharding-JDBC 实现水平分表
1.搭建环 (1) 技术: SpringBoot2.2.1+ MyBatisPlus + Sharding-JDBC + Druid 连接池(2)创建 SpringBoot 工程
随机推荐
- JS快速入门
字符串 模板字符串 需要特别注意的是,字符串是不可变的,如果对字符串的某个索引赋值,不会有任何错误,但是,也没有任何效果: var s = 'Test'; s[0] = 'X'; alert(s); ...
- gerrit设置非小组成员禁止下载代码
对gerrit有所了解的同学,都知道gerrit 是我们常用的一个来做代码审核的工具,其中的权限管理,是一个非常重要的环节,关于每个权限的使用范围,可以参考博客https://blog.csdn.ne ...
- phpstudy安装redis
php安装扩展,首先要在php官网下载相应的库文件, http://pecl.php.net/package/redis 下载相应版本的文件,首先phpinfo()看看当前的php环境版本等等 我 ...
- 利用yum升级Centos6的gcc版本,使其支持C++11
下面的可以在centos6下工作,centos7下有问题.可能是因为centos下的scl我是拷贝的文件,没有完全验证centos6下肯定没问题. https://my.oschina.net/u/5 ...
- Express web框架 upload file
哈哈,敢开源,还是要有两把刷子的啊 今天,看看node.js 的web框架 Express的实际应用 //demo1 upload file <html><head><t ...
- 使用pycharm调试django项目
要使用pycharm调试django 打断点调试后台代码,首先要进行一下配置: 1.debug 配置 打开debug界面 2.选择python点+加号,然后选择python 3.名字debug,这个看 ...
- RNN通俗理解
让数据间的关联也被 NN 加以分析,我们人类是怎么分析各种事物的关联,?最基本的方式,就是记住之前发生的事情. 那我们让神经网络也具备这种记住之前发生的事的能力. 再分析 Data0 的时候, 我们把 ...
- sqli-labs(十二)(and和or的过滤)
第二十五关: 这关是过滤了and 和or 输入?id=1' or '1'='1 发现or被过滤了,将or换成and也一样. 输入?id=1' oorr '1'='1 这样就可以了,将一个or置空后,o ...
- React创建组件的不同方式(ES5 & ES6)
一. 首先缕清楚React.createElement.React.createClass.React.Component之间的关系 1. React.createElement(HTML eleme ...
- webpack 解决跨域问题
一.webpack 内置了 http-proxy-middleware 可以解决 请求的 URL 代理的问题 安装:npm install --save http-proxy-middleware 二 ...