hadoop常见面试题
Q1.什么是 Hadoop?
Hadoop 是一个开源软件框架,用于存储大量数据,并发处理/查询在具有多个商用硬件(即低成本硬件)节点的集群上的那些数据。总之,Hadoop 包括以下内容:
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统):HDFS 允许你以一种分布式和冗余的方式存储大量数据。例如,1 GB(即 1024 MB)文本文件可以拆分为 16 * 128MB 文件,并存储在 Hadoop 集群中的 8 个不同节点上。每个分裂可以复制 3 次,以实现容错,以便如果 1 个节点故障的话,也有备份。HDFS 适用于顺序的“一次写入、多次读取”的类型访问。
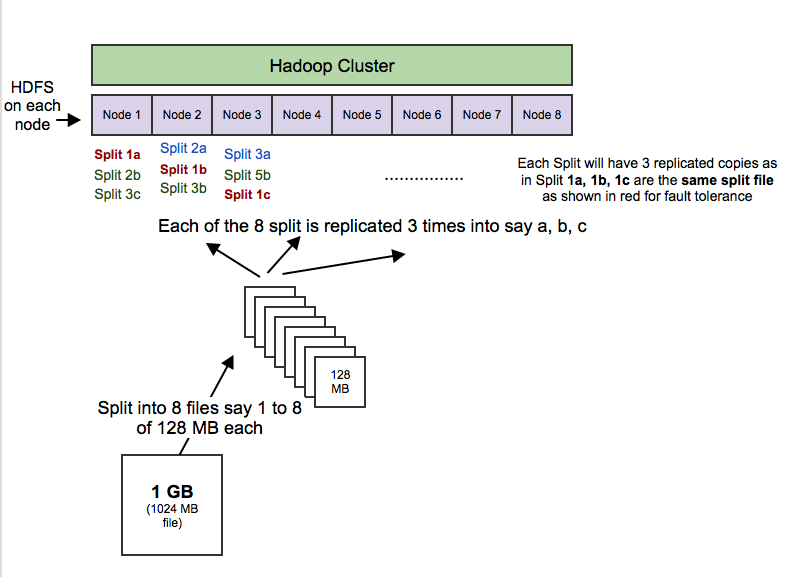
MapReduce:一个计算框架。它以分布式和并行的方式处理大量的数据。当你对所有年龄> 18 的用户在上述 1 GB 文件上执行查询时,将会有“8 个映射”函数并行运行,以在其 128 MB 拆分文件中提取年龄> 18 的用户,然后“reduce”函数将运行以将所有单独的输出组合成单个最终结果。
YARN(Yet Another Resource Nagotiator,又一资源定位器):用于作业调度和集群资源管理的框架。
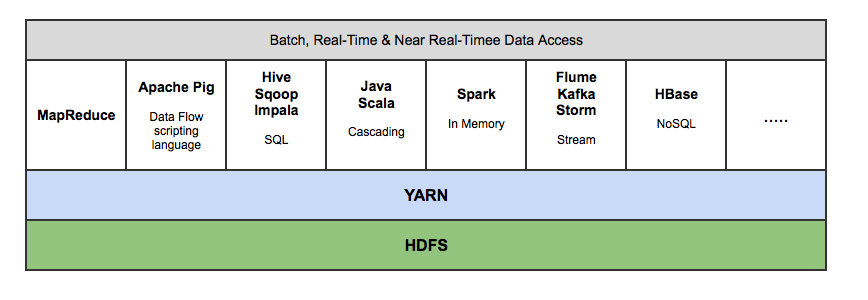
Hadoop 生态系统,拥有 15 多种框架和工具,如 Sqoop,Flume,Kafka,Pig,Hive,Spark,Impala 等,以便将数据摄入 HDFS,在 HDFS 中转移数据(即变换,丰富,聚合等),并查询来自 HDFS 的数据用于商业智能和分析。某些工具(如 Pig 和 Hive)是 MapReduce 上的抽象层,而 Spark 和 Impala 等其他工具则是来自 MapReduce 的改进架构/设计,用于显著提高的延迟以支持近实时(即 NRT)和实时处理。
Q2.为什么组织从传统的数据仓库工具转移到基于 Hadoop 生态系统的智能数据中心?
Hadoop 组织正在从以下几个方面提高自己的能力:
现有数据基础设施:
- 主要使用存储在高端和昂贵硬件中的“structured data,结构化数据”
- 主要处理为 ETL 批处理作业,用于将数据提取到 RDBMS 和数据仓库系统中进行数据挖掘,分析和报告,以进行关键业务决策。
- 主要处理以千兆字节到兆字节为单位的数据量
基于 Hadoop 的更智能的数据基础设施,其中
- 结构化(例如 RDBMS),非结构化(例如 images,PDF,docs )和半结构化(例如 logs,XMLs)的数据可以以可扩展和容错的方式存储在较便宜的商品机器中。
- 可以通过批处理作业和近实时(即,NRT,200 毫秒至 2 秒)流(例如 Flume 和 Kafka)来摄取数据。
- 数据可以使用诸如 Spark 和 Impala 之类的工具以低延迟(即低于 100 毫秒)的能力查询。
- 可以存储以兆兆字节到千兆字节为单位的较大数据量。
这使得组织能够使用更强大的工具来做出更好的业务决策,这些更强大的工具用于获取数据,转移存储的数据(例如聚合,丰富,变换等),以及使用低延迟的报告功能和商业智能。
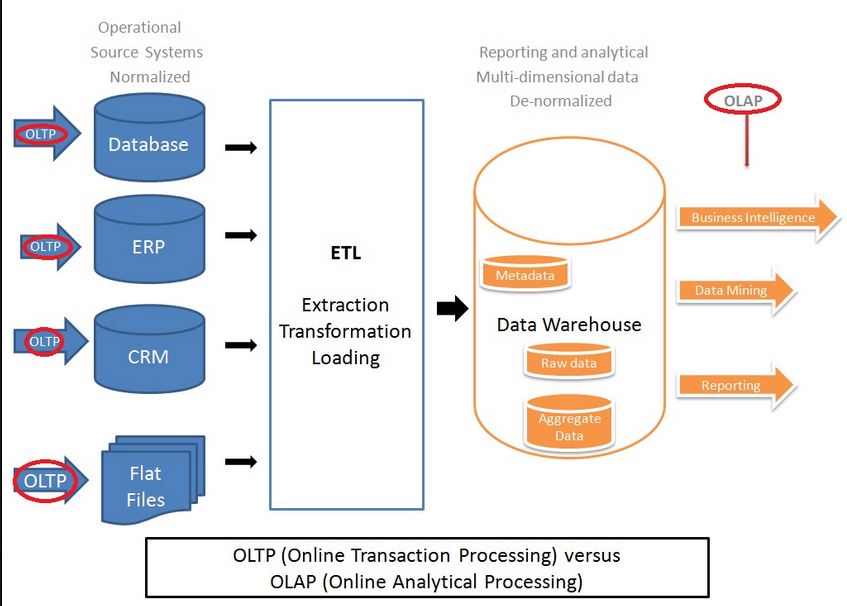
Q3.更智能&更大的数据中心架构与传统的数据仓库架构有何不同?
传统的企业数据仓库架构
基于 Hadoop 的数据中心架构
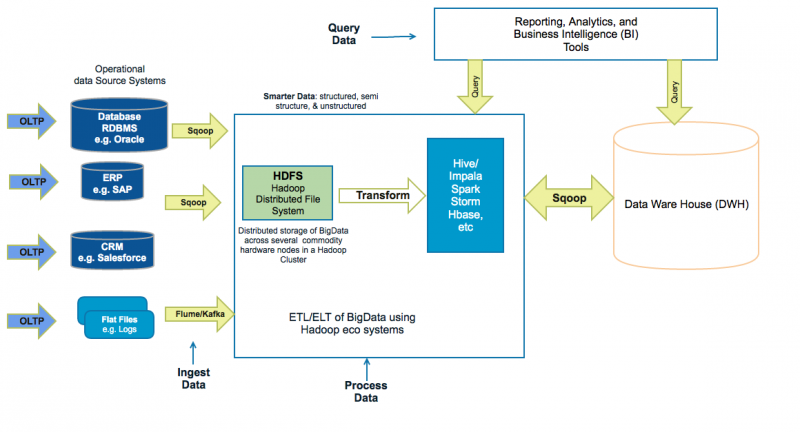
Q4.基于 Hadoop 的数据中心的好处是什么?
随着数据量和复杂性的增加,提高了整体 SLA(即服务水平协议)。例如,“Shared Nothing”架构,并行处理,内存密集型处理框架,如 Spark 和 Impala,以及 YARN 容量调度程序中的资源抢占。
缩放数据仓库可能会很昂贵。添加额外的高端硬件容量以及获取数据仓库工具的许可证可能会显著增加成本。基于 Hadoop 的解决方案不仅在商品硬件节点和开源工具方面更便宜,而且还可以通过将数据转换卸载到 Hadoop 工具(如 Spark 和 Impala)来补足数据仓库解决方案,从而更高效地并行处理大数据。这也将释放数据仓库资源。
探索新的渠道和线索。Hadoop 可以为数据科学家提供探索性的沙盒,以从社交媒体,日志文件,电子邮件等地方发现潜在的有价值的数据,这些数据通常在数据仓库中不可得。
更好的灵活性。通常业务需求的改变,也需要对架构和报告进行更改。基于 Hadoop 的解决方案不仅可以灵活地处理不断发展的模式,还可以处理来自不同来源,如社交媒体,应用程序日志文件,image,PDF 和文档文件的半结构化和非结构化数据。
Q5.大数据解决方案的关键步骤是什么?
提取数据,存储数据(即数据建模)和处理数据(即数据加工,数据转换和查询数据)。
提取数据
从各种来源提取数据,例如:
- RDBM(Relational Database Management Systems)关系数据库管理系统,如 Oracle,MySQL 等。
- ERPs(Enterprise Resource Planning)企业资源规划(即 ERP)系统,如 SAP。
- CRM(Customer Relationships Management)客户关系管理系统,如 Siebel,Salesforce 等
- 社交媒体 Feed 和日志文件。
- 平面文件,文档和图像。
并将其存储在基于“Hadoop 分布式文件系统”(简称 HDFS)的数据中心上。可以通过批处理作业(例如每 15 分钟运行一次,每晚一次,等),近实时(即 100 毫秒至 2 分钟)流式传输和实时流式传输(即 100 毫秒以下)去采集数据。
Hadoop 中使用的一个常用术语是“Schema-On-Read”。这意味着未处理(也称为原始)的数据可以被加载到 HDFS,其具有基于处理应用的需求在处理之时应用的结构。这与“Schema-On-Write”不同,后者用于需要在加载数据之前在 RDBM 中定义模式。
存储数据
数据可以存储在 HDFS 或 NoSQL 数据库,如 HBase。HDFS 针对顺序访问和“一次写入和多次读取”的使用模式进行了优化。HDFS 具有很高的读写速率,因为它可以将 I / O 并行到多个驱动器。HBase 在 HDFS 之上,并以柱状方式将数据存储为键/值对。列作为列家族在一起。HBase 适合随机读/写访问。在 Hadoop 中存储数据之前,你需要考虑以下几点:
- 数据存储格式:有许多可以应用的文件格式(例如 CSV,JSON,序列,AVRO,Parquet 等)和数据压缩算法(例如 snappy,LZO,gzip,bzip2 等)。每个都有特殊的优势。像 LZO 和 bzip2 的压缩算法是可拆分的。
- 数据建模:尽管 Hadoop 的无模式性质,模式设计依然是一个重要的考虑方面。这包括存储在 HBase,Hive 和 Impala 中的对象的目录结构和模式。Hadoop 通常用作整个组织的数据中心,并且数据旨在共享。因此,结构化和有组织的数据存储很重要。
- 元数据管理:与存储数据相关的元数据。
- 多用户:更智能的数据中心托管多个用户、组和应用程序。这往往导致与统治、标准化和管理相关的挑战。
处理数据
Hadoop 的处理框架使用 HDFS。它使用“Shared Nothing”架构,在分布式系统中,每个节点完全独立于系统中的其他节点。没有共享资源,如 CPU,内存以及会成为瓶颈的磁盘存储。Hadoop 的处理框架(如 Spark,Pig,Hive,Impala 等)处理数据的不同子集,并且不需要管理对共享数据的访问。 “Shared Nothing”架构是非常可扩展的,因为更多的节点可以被添加而没有更进一步的争用和容错,因为每个节点是独立的,并且没有单点故障,系统可以从单个节点的故障快速恢复。
Q6.你会如何选择不同的文件格式存储和处理数据?
设计决策的关键之一是基于以下方面关注文件格式:
- 使用模式,例如访问 50 列中的 5 列,而不是访问大多数列。
- 可并行处理的可分裂性。
- 块压缩节省存储空间 vs 读/写/传输性能
- 模式演化以添加字段,修改字段和重命名字段。
CSV 文件
CSV 文件通常用于在 Hadoop 和外部系统之间交换数据。CSV 是可读和可解析的。 CSV 可以方便地用于从数据库到 Hadoop 或到分析数据库的批量加载。在 Hadoop 中使用 CSV 文件时,不包括页眉或页脚行。文件的每一行都应包含记录。CSV 文件对模式评估的支持是有限的,因为新字段只能附加到记录的结尾,并且现有字段不能受到限制。CSV 文件不支持块压缩,因此压缩 CSV 文件会有明显的读取性能成本。
JSON 文件
JSON 记录与 JSON 文件不同;每一行都是其 JSON 记录。由于 JSON 将模式和数据一起存储在每个记录中,因此它能够实现完整的模式演进和可拆分性。此外,JSON 文件不支持块级压缩。
序列文件
序列文件以与 CSV 文件类似的结构用二进制格式存储数据。像 CSV 一样,序列文件不存储元数据,因此只有模式进化才将新字段附加到记录的末尾。与 CSV 文件不同,序列文件确实支持块压缩。序列文件也是可拆分的。序列文件可以用于解决“小文件问题”,方式是通过组合较小的通过存储文件名作为键和文件内容作为值的 XML 文件。由于读取序列文件的复杂性,它们更适合用于在飞行中的(即中间的)数据存储。
注意:序列文件是以 Java 为中心的,不能跨平台使用。
Avro 文件
适合于有模式的长期存储。Avro 文件存储具有数据的元数据,但也允许指定用于读取文件的独立模式。启用完全的模式进化支持,允许你通过定义新的独立模式重命名、添加和删除字段以及更改字段的数据类型。Avro 文件以 JSON 格式定义模式,数据将采用二进制 JSON 格式。Avro 文件也是可拆分的,并支持块压缩。更适合需要行级访问的使用模式。这意味着查询该行中的所有列。不适用于行有 50+ 列,但使用模式只需要访问 10 个或更少的列。Parquet 文件格式更适合这个列访问使用模式。
Columnar 格式,例如 RCFile,ORC
RDBM 以面向行的方式存储记录,因为这对于需要在获取许多列的记录的情况下是高效的。如果在向磁盘写入记录时已知所有列值,则面向行的写也是有效的。但是这种方法不能有效地获取行中的仅 10% 的列或者在写入时所有列值都不知道的情况。这是 Columnar 文件更有意义的地方。所以 Columnar 格式在以下情况下工作良好
- 在不属于查询的列上跳过 I / O 和解压缩
- 用于仅访问列的一小部分的查询。
- 用于数据仓库型应用程序,其中用户想要在大量记录上聚合某些列。
RC 和 ORC 格式是专门用 Hive 写的而不是通用作为 Parquet。
Parquet 文件
Parquet 文件是一个 columnar 文件,如 RC 和 ORC。Parquet 文件支持块压缩并针对查询性能进行了优化,可以从 50 多个列记录中选择 10 个或更少的列。Parquet 文件写入性能比非 columnar 文件格式慢。Parquet 通过允许在最后添加新列,还支持有限的模式演变。Parquet 可以使用 Avro API 和 Avro 架构进行读写。
所以,总而言之,相对于其他,你应该会更喜欢序列,Avro 和 Parquet 文件格式;序列文件用于原始和中间存储,Avro 和 Parquet 文件用于处理。
1、海量日志数据提取出某日访问百度次数最多的IP,怎么做?

2、有一个1G大小的文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。

3、更智能&更大的数据中心架构与传统的数据仓库架构有何不同?
传统的企业数据仓库架构

基于 Hadoop 的数据中心架构

4、运行Hadoop集群需要哪些守护进程?
DataNode,NameNode,TaskTracker和JobTracker都是运行Hadoop集群需要的守护进程。
5、Hadoop支持哪些操作系统部署?
Hadoop的主要操作系统是Linux。 但是,通过使用一些额外的软件,也可以在Windows平台上部署,但这种方式不被推荐。
6、Hadoop常见输入格式是什么?
三种广泛使用的输入格式是:
·文本输入:Hadoop中的默认输入格式。
·Key值:用于纯文本文件
·序列:用于依次读取文件
7、RDBMS和Hadoop的主要区别是什么?
RDBMS用于事务性系统存储和处理数据,而Hadoop可以用来存储大量数据。
8、给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的URL?


9、如何在生产环境中部署Hadoop的不同组件?
需要在主节点上部署jobtracker和namenode,然后在多个从节点上部署datanode。
10、添加新datanode后,作为Hadoop管理员需要做什么?
需要启动平衡器才能在所有节点之间重新平均分配数据,以便Hadoop集群自动查找新的datanode。要优化集群性能,应该重新启动平衡器以在数据节点之间重新分配数据。
11、namenode的重要性是什么?
namenonde的作用在Hadoop中非常重要。它是Hadoop的大脑,主要负责管理系统上的分配块,还为客户提出请求时的数据提供特定地址。
12、判断:Block Size是不可以修改的。(错误)
分析:

13、当NameNode关闭时会发生什么?
如果NameNode关闭,文件系统将脱机。
14、是否可以在不同集群之间复制文件?如果是的话,怎么能做到这一点?
是的,可以在多个Hadoop集群之间复制文件,这可以使用分布式复制来完成。
15、是否有任何标准方法来部署Hadoop?
现在有使用Hadoop部署数据的标准程序,所有Hadoop发行版都没有什么通用要求。但是,对于每个Hadoop管理员,具体方法总是不同的。
16、HDFS,replica如何定位?

17、distcp是什么?
Distcp是一个Hadoop复制工具,主要用于执行MapReduce作业来复制数据。 Hadoop环境中的主要挑战是在各集群之间复制数据,distcp也将提供多个datanode来并行复制数据。
18、什么是检查点?
对文件数据的修改不是直接写回到磁盘的,很多操作是先缓存到内存的Buffer中,当遇到一个检查点Checkpoint时,系统会强制将内存中的数据写回磁盘,当然此时才会记录日志,从而产生持久的修改状态。因此,不用重放一个编辑日志,NameNode可以直接从FsImage加载到最终的内存状态,这肯定会降低NameNode启动时间。
19、什么是机架感知?
这是一种决定如何根据机架定义放置块的方法。Hadoop将尝试限制存在于同一机架中的datanode之间的网络流量。为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。 综合考虑这两点的基础上Hadoop设计了机架感知功能。
20、有哪些重要的Hadoop工具?
“Hive”,HBase,HDFS,ZooKeeper,NoSQL,Lucene / SolrSee,Avro,Oozie,Flume,和SQL是一些增强大数据性能的Hadoop工具。
21、什么是投机性执行?
如果一个节点正在执行比主节点慢的任务。那么就需要在另一个节点上冗余地执行同一个任务的一个实例。所以首先完成的任务会被接受,另一个可能会被杀死。这个过程被称为“投机执行”。
22、Hadoop及其组件是什么?
当“大数据”出现问题时,Hadoop发展成为一个解决方案。这是一个提供各种服务或工具来存储和处理大数据的框架。这也有助于分析大数据,并做出用传统方法难以做出的商业决策。
23、Hadoop的基本特性是什么?
Hadoop框架有能力解决大数据分析的许多问题。它是基于Google大数据文件系统的Google MapReduce设计的。
24、是否可以在Windows上运行Hadoop?
可以,但是最好不要这么做,Red Hat Linux或者是Ubuntu才是Hadoop的最佳操作系统。在Hadoop安装中,Windows通常不会被使用,因为会出现各种各样的问题。因此,Windows绝不是Hadoop推荐系统。
25、主动和被动“名称节点”是什么?
在HA(高可用性)架构中,我们有两个NameNodes - Active“NameNode”和被动“NameNode”。
· 活动“NameNode”是在集群中运行的“NameNode”。
· 被动“NameNode”是一个备用的“NameNode”,与“NameNode”有着相似的数据。
当活动的“NameNode”失败时,被动“NameNode”将替换群集中的活动“NameNode”。因此,集群永远不会没有“NameNode”,所以它永远不会失败。
hadoop常见面试题的更多相关文章
- java常见面试题及答案 1-10(基础篇)
java常见面试题及答案 1.什么是Java虚拟机?为什么Java被称作是"平台无关的编程语言"? Java 虚拟机是一个可以执行 Java 字节码的虚拟机进程.Java 源文件被 ...
- Web开发的常见面试题HTML和HTML5等
作为一名前端开发人员,HTML,HTML5以及网站优化都是必须掌握的技术,下面列举一下HTML, HTML5, 网站优化等常见的面试题: HTML常见面试题: 1. 什么是Semantic HTML( ...
- 常见面试题之ListView的复用及如何优化
经常有人问我,作为刚毕业的要去面试,关于安卓开发的问题,技术面试官会经常问哪些问题呢?我想来想去不能一股脑的全写出来,我准备把这些问题单独拿出来写,并详细的分析一下,这样对于初学者是最有帮助的.这次的 ...
- iOS常见面试题汇总
iOS常见面试题汇总 1. 什么是 ARC? (ARC 是为了解决什么问题而诞生的?) ARC 是 Automatic Reference Counting 的缩写, 即自动引用计数. 这是苹果在 i ...
- JDBC常见面试题
以下我是归纳的JDBC知识点图: 图上的知识点都可以在我其他的文章内找到相应内容. JDBC常见面试题 JDBC操作数据库的步骤 ? JDBC操作数据库的步骤 ? 注册数据库驱动. 建立数据库连接. ...
- Mybatis常见面试题
Mybatis常见面试题 #{}和${}的区别是什么? #{}和${}的区别是什么? 在Mybatis中,有两种占位符 #{}解析传递进来的参数数据 ${}对传递进来的参数原样拼接在SQL中 #{}是 ...
- JavaSE:数据类型之间的转换(附常见面试题)
数据类型之间的转换 分为以下几种情况: 1)低级到高级的自动类型转换: 2)高级到低级的强制类型转换(会导致溢出或丢失精度): 3)基本类型向类类型转换: 4)基本类型向字符串的转换: 5)类类型向字 ...
- 整理的最全 python常见面试题(基本必考)
整理的最全 python常见面试题(基本必考) python 2018-05-17 作者 大蛇王 1.大数据的文件读取 ① 利用生成器generator ②迭代器进行迭代遍历:for line in ...
- PHP常见面试题汇总(二)
PHP常见面试题汇总(二) //第51题:统计一维数组中所有值出现的次数?返回一个数组,其元素的键名是原数组的值;键值是该值在原数组中出现的次数 $array=array(4,5,1,2,3,1, ...
随机推荐
- (转)Applications of Reinforcement Learning in Real World
Applications of Reinforcement Learning in Real World 2018-08-05 18:58:04 This blog is copied from: h ...
- 怎么在父窗口调用它页面的iframe里面数据,进行操作?
注:在服务器下操作有效果,本地无效 document.getElementById("taskdetail1").contentWindow.test(a) document.ge ...
- Unity3D学习笔记(三十三):矩阵
矩阵 矩阵就是一行和列组织起来的矩形数字块. 矩阵可以理解为是向量的数组. 矩阵的维度和记法 矩阵的维度是包含多少行多少列!例如1行2列的矩阵 记法:矩阵m中,对于第1行第2列的元素,我们记为m1 ...
- Kubernetes之容器
Images You create your Docker image and push it to a registry before referring to it in a Kubernetes ...
- python学习 day10打卡 函数的进阶
本节主要内容: 1.函数参数--动态参数 2.名称空间,局部名称空间,全局名称空间,作用域,加载顺序. 3.函数的嵌套 4.gloabal,nonlocal关键字 一.函数参数--动态传参 形参的第三 ...
- python学习 day07打卡 文件操作
本节主要内容: 初识文件操作 只读(r,rb) 只读(w,wb) 追加(a,ab) r+读写 w+写读 a+追加写读 其他操作方法 文件的修改以及另一种打开文件句柄的方法 一. 初识文件操作 使用py ...
- mysql行转列(多行转一列)
场景 比如说一个订单对应多条数据,当状态(status)=1的时候, 数量(num)=25,当状态(status)=2的时候, 数量(num)=45,现在想用一条sql记录下不同状态对应的数量为多 ...
- 七牛云存储上传自有证书开启https访问
虽然七牛云存储也提供免费SSL证书申请,但我就喜欢用其他平台申请的,于是在腾讯云申请了免费SSL证书,正准备在七牛上传,弹出的界面却让我傻了眼,如下图所示: 腾讯免费SSL证书提供了不同服务器环境的版 ...
- ajax 怎么重新加载页面
$.ajax({ type:"post", url:url, data:{xxx:xx}, dataType: "json", success : functi ...
- Android自定义权限
一.自定义权限 自定义权限,一般是考虑到应用共享组件时的安全问题.我们知道在四大组件 AndroidManifest 中注册的时候,添加 exported = "true" 这一属 ...