spark 关联source
IDEA就自动把jar包中的字节码反编译为Java源码,并且,我们可以直接下个断点调试程序,但是对于Scala,IDEA的反编译效果并不是很好,如下图所示:
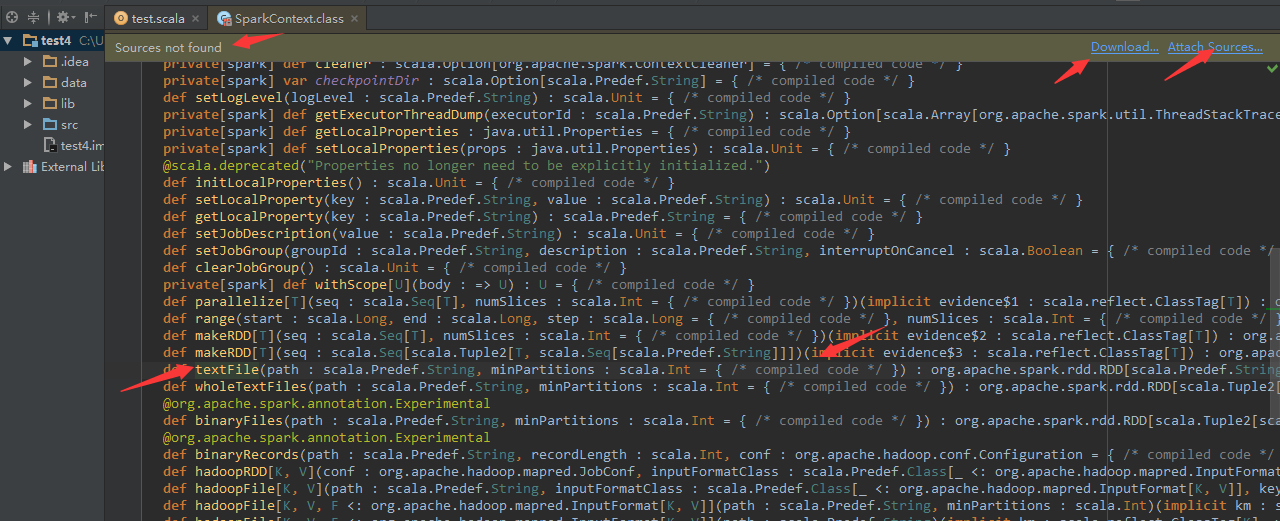
2)提示“Source not found”,我们在看textFile()方法,只可以看到方法的参数列表,方法体的内容却看不到,只能看到“compiled code”也就是“编译后的代码”。解决方法如下:
a.下载 源码 eg: https://archive.apache.org/dist/spark/spark-2.0.2/
b.然后点击右上角的“Attach Source”,添加源码,如下所示:
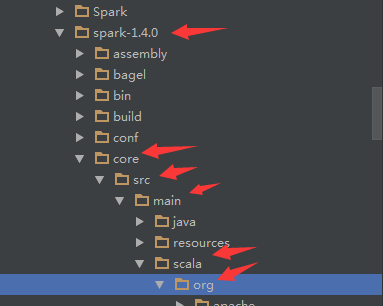
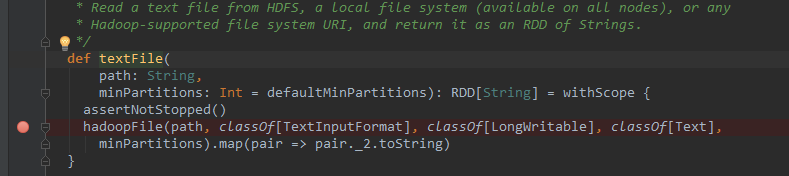
添加路径是“spark1.4.0/core/src/main/scala/org”,然后点击OK确定。“Attching”完成之后,我们就可以看到textFile()的方法体了,并且可以像之前调试hadoop一样,在这个方法下断点,运行程序的时候,会在这里命中断点,如下所示(这里只是加了个断点,没有调试):
spark 关联source的更多相关文章
- ubuntu 12.04 下 eclipse关联 source code
一.JDK source code 命令行中: sudo apt-get install openjdk-7-source 下好的jdk源码在 Linux 在目录 usr/lib/jvm/openjd ...
- Spark Streaming、Kafka结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收Kafka发送过来的数据与关系型数据库中的表进行相关的查询操作: Kafka发送过来的数据格式为:id.name.cityId,分隔符为tab zhangs ...
- Spark Streaming、HDFS结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收HDFS上的文件数据与关系型数据库中的表进行相关的查询操作: 使用技术:Spark Streaming + Spark JDBC External Data ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- Spark SQL编程指南(Python)
前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询.它的核心是一个特殊类型的Spark RDD:SchemaRDD. SchemaRDD类似于传统关 ...
- Spark SQL编程指南(Python)【转】
转自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询 ...
- 搭建Spark的单机版集群
一.创建用户 # useradd spark # passwd spark 二.下载软件 JDK,Scala,SBT,Maven 版本信息如下: JDK jdk-7u79-linux-x64.gz S ...
- spark on yarn 提交任务出错
Application ID is application_1481285758114_422243, trackingURL: http://***:4040Exception in thread ...
- Spark On Yarn中spark.yarn.jar属性的使用
今天在测试spark-sql运行在yarn上的过程中,无意间从日志中发现了一个问题: spark-sql --master yarn // :: INFO Client: Requesting a n ...
随机推荐
- [daily][archlinux][pacman] 删除所有孤立包(orphan)
[:] <tong> sudo pacman -Rsun `pacman -Qdt |cut -d` [:] <tong> 我每次都这么删, 有没有高级点的 ...
- NOIP 2018 day1 题解
今年noip的题和去年绝对是比较坑的题了,但是打好的话就算是普通水准也能350分以上吧. t1: 很显然这是一个简单的dp即可. #include<iostream> #include&l ...
- (未完成)在block内如何修改block外部变量
变量必须用__block修饰,否则编译不通过 block内部会把变量拷贝到堆区 变量从栈区copy->堆区 通过对对象取地址,打印出对象在内存中的地址 &a block不允许修改外部变量 ...
- DBCHART
dbchart1.Series[0].DataSource := adoquery1; dbchart1.Series[0].XLabelsSource := 'aaaa'; dbchart1.Ser ...
- 内部排序->交换排序->快速排序
文字描述 快速排序是对起泡排序的一种改进.它的基本思想是,通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个 ...
- 洛谷P2747周游加拿大Canada Tour [USACO5.4] dp
正解:dp 解题报告: 传送门! 其实这题是我做网络流的时候发现了这题,感觉有点像双倍经验,,,? 但是我还不想写网络流的题解,,,因为网络流24题都还麻油做完,,,想着全做完了再写个总的题解什么的( ...
- kali蓝牙连接
http://blog.csdn.net/hailangnet/article/details/47723181 http://www.aiuxian.com/article/p-3012084.ht ...
- uarts裸机程序
硬件平台:JZ2440 实现功能:向串口软件实现输出putchar函数 start.s --> 设置堆栈,关闭看门狗,初始化时钟,初始化sdram init.c -->初始化 ...
- ES6面试题总结
1.说出至少5个ES6的新特性,并简述它们的作用.(简答题) 1.let关键字,用于声明只在块级作用域起作用的变量: 2.const关键字,用于声明一个常量: 3.结构赋值,一种新的变量赋值方式.常用 ...
- Java 堆外内存
入口ByteBuffer.allocateDirect public static ByteBuffer allocateDirect(int capacity) { return new Direc ...