搭建Spark的单机版集群
一、创建用户
# useradd spark
# passwd spark
二、下载软件
JDK,Scala,SBT,Maven
版本信息如下:
JDK jdk-7u79-linux-x64.gz
Scala scala-2.10.5.tgz
SBT sbt-0.13.7.zip
Maven apache-maven-3.2.5-bin.tar.gz
注意:如果只是安装Spark环境,则只需JDK和Scala即可,SBT和Maven是为了后续的源码编译。
三、解压上述文件并进行环境变量配置
# cd /usr/local/
# tar xvf /root/jdk-7u79-linux-x64.gz
# tar xvf /root/scala-2.10.5.tgz
# tar xvf /root/apache-maven-3.2.5-bin.tar.gz
# unzip /root/sbt-0.13.7.zip
修改环境变量的配置文件
# vim /etc/profile
export JAVA_HOME=/usr/local/jdk1..0_79
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export SCALA_HOME=/usr/local/scala-2.10.
export MAVEN_HOME=/usr/local/apache-maven-3.2.
export SBT_HOME=/usr/local/sbt
export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin:$MAVEN_HOME/bin:$SBT_HOME/bin
使配置文件生效
# source /etc/profile
测试环境变量是否生效
# java –version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) -Bit Server VM (build 24.79-b02, mixed mode)
# scala –version
Scala code runner version 2.10. -- Copyright -, LAMP/EPFL
# mvn –version
Apache Maven 3.2. (12a6b3acb947671f09b81f49094c53f426d8cea1; --15T01::+:)
Maven home: /usr/local/apache-maven-3.2.
Java version: 1.7.0_79, vendor: Oracle Corporation
Java home: /usr/local/jdk1..0_79/jre
Default locale: en_US, platform encoding: UTF-
OS name: "linux", version: "3.10.0-229.el7.x86_64", arch: "amd64", family: "unix"
# sbt --version
sbt launcher version 0.13.
四、主机名绑定
[root@spark01 ~]# vim /etc/hosts
192.168.244.147 spark01
五、配置spark
切换到spark用户下
下载hadoop和spark,可使用wget命令下载
spark-1.4.0 http://d3kbcqa49mib13.cloudfront.net/spark-1.4.0-bin-hadoop2.6.tgz
Hadoop http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
解压上述文件并进行环境变量配置
修改spark用户环境变量的配置文件
[spark@spark01 ~]$ vim .bash_profile
export SPARK_HOME=$HOME/spark-1.4.-bin-hadoop2.
export HADOOP_HOME=$HOME/hadoop-2.6.
export HADOOP_CONF_DIR=$HOME/hadoop-2.6./etc/hadoop
export PATH=$PATH:$SPARK_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置文件生效
[spark@spark01 ~]$ source .bash_profile
修改spark配置文件
[spark@spark01 ~]$ cd spark-1.4.0-bin-hadoop2.6/conf/
[spark@spark01 conf]$ cp spark-env.sh.template spark-env.sh
[spark@spark01 conf]$ vim spark-env.sh
在后面添加如下内容:
export SCALA_HOME=/usr/local/scala-2.10.
export SPARK_MASTER_IP=spark01
export SPARK_WORKER_MEMORY=1500m
export JAVA_HOME=/usr/local/jdk1..0_79
有条件的童鞋可将SPARK_WORKER_MEMORY适当设大一点,因为我虚拟机内存是2G,所以只给了1500m。
配置slaves
[spark@spark01 conf]$ cp slaves slaves.template
[spark@spark01 conf]$ vim slaves
将localhost修改为spark01
启动master
[spark@spark01 spark-1.4.0-bin-hadoop2.6]$ sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /home/spark/spark-1.4.-bin-hadoop2./sbin/../logs/spark-spark-org.apache.spark.deploy.master.Master--spark01.out
查看上述日志的输出内容
[spark@spark01 spark-1.4.0-bin-hadoop2.6]$ cd logs/
[spark@spark01 logs]$ cat spark-spark-org.apache.spark.deploy.master.Master-1-spark01.out
Spark Command: /usr/local/jdk1..0_79/bin/java -cp /home/spark/spark-1.4.-bin-hadoop2./sbin/../conf/:/home/spark/spark-1.4.-bin-hadoop2./lib/spark-assembly-1.4.-hadoop2.6.0.jar:/home/spark/spark-1.4.-bin-hadoop2./lib/datanucleus-core-3.2..jar:/home/spark/spark-1.4.-bin-hadoop2./lib/datanucleus-api-jdo-3.2..jar:/home/spark/spark-1.4.-bin-hadoop2./lib/datanucleus-rdbms-3.2..jar:/home/spark/hadoop-2.6./etc/hadoop/ -Xms512m -Xmx512m -XX:MaxPermSize=128m org.apache.spark.deploy.master.Master --ip spark01 --port --webui-port
========================================
// :: INFO master.Master: Registered signal handlers for [TERM, HUP, INT]
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO spark.SecurityManager: Changing view acls to: spark
// :: INFO spark.SecurityManager: Changing modify acls to: spark
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
// :: INFO slf4j.Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkMaster@spark01:7077]
// :: INFO util.Utils: Successfully started service 'sparkMaster' on port .
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SelectChannelConnector@spark01:
// :: INFO util.Utils: Successfully started service on port .
// :: INFO rest.StandaloneRestServer: Started REST server for submitting applications on port
// :: INFO master.Master: Starting Spark master at spark://spark01:7077
// :: INFO master.Master: Running Spark version 1.4.
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'MasterUI' on port .
// :: INFO ui.MasterWebUI: Started MasterWebUI at http://192.168.244.147:8080
// :: INFO master.Master: I have been elected leader! New state: ALIVE
从日志中也可看出,master启动正常
下面来看看master的 web管理界面,默认在8080端口
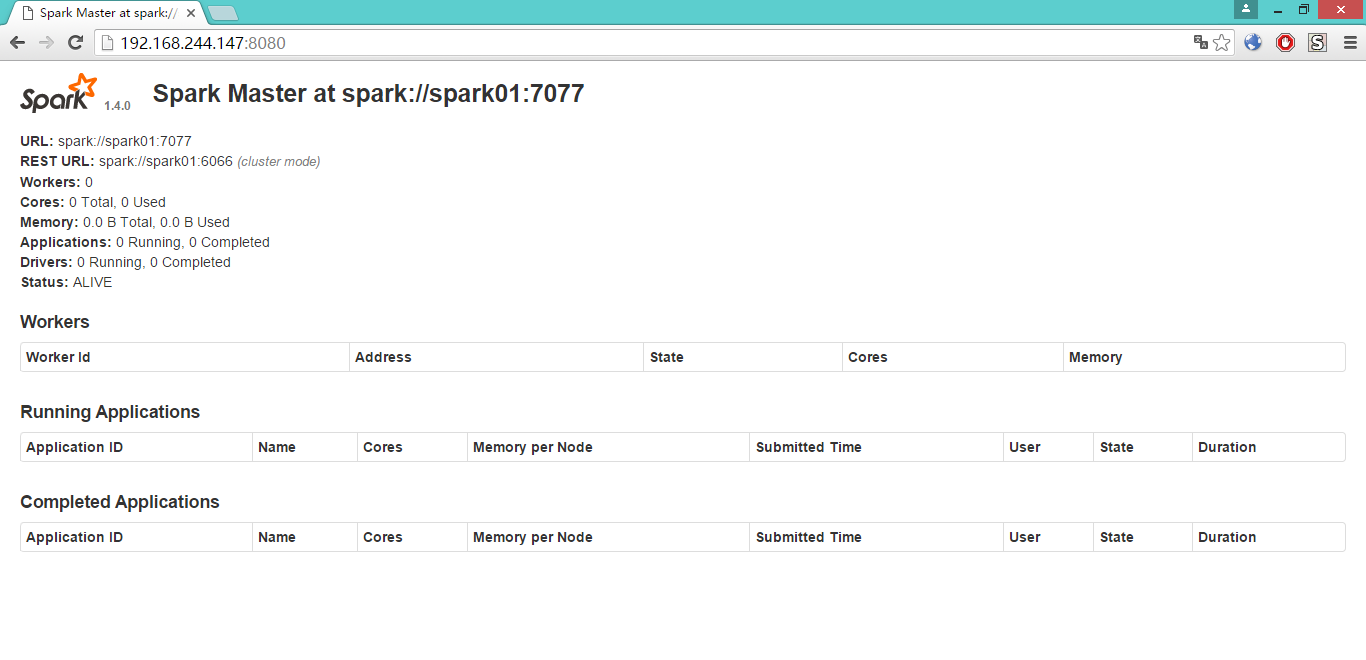
启动worker
[spark@spark01 spark-1.4.0-bin-hadoop2.6]$ sbin/start-slaves.sh spark://spark01:7077
spark01: Warning: Permanently added 'spark01,192.168.244.147' (ECDSA) to the list of known hosts.
spark@spark01's password:
spark01: starting org.apache.spark.deploy.worker.Worker, logging to /home/spark/spark-1.4.-bin-hadoop2./sbin/../logs/spark-spark-org.apache.spark.deploy.worker.Worker--spark01.out
输入spark01上spark用户的密码
可通过日志的信息来确认workder是否正常启动,因信息太多,在这里就不贴出了。
[spark@spark01 spark-1.4.0-bin-hadoop2.6]$ cd logs/
[spark@spark01 logs]$ cat spark-spark-org.apache.spark.deploy.worker.Worker-1-spark01.out
启动spark shell
[spark@spark01 spark-1.4.0-bin-hadoop2.6]$ bin/spark-shell --master spark://spark01:7077
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO spark.SecurityManager: Changing view acls to: spark
// :: INFO spark.SecurityManager: Changing modify acls to: spark
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
// :: INFO spark.HttpServer: Starting HTTP Server
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'HTTP class server' on port .
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.
/_/ Using Scala version 2.10. (Java HotSpot(TM) -Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
// :: INFO spark.SparkContext: Running Spark version 1.4.
// :: INFO spark.SecurityManager: Changing view acls to: spark
// :: INFO spark.SecurityManager: Changing modify acls to: spark
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(spark); users with modify permissions: Set(spark)
// :: INFO slf4j.Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.244.147:43850]
// :: INFO util.Utils: Successfully started service 'sparkDriver' on port .
// :: INFO spark.SparkEnv: Registering MapOutputTracker
// :: INFO spark.SparkEnv: Registering BlockManagerMaster
// :: INFO storage.DiskBlockManager: Created local directory at /tmp/spark-7b7bd4bd-ff20-4e3d-a354-61a4ca7c4b2f/blockmgr-0e855210---b5e3-151e0c096c15
// :: INFO storage.MemoryStore: MemoryStore started with capacity 265.4 MB
// :: INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-7b7bd4bd-ff20-4e3d-a354-61a4ca7c4b2f/httpd-56ac16d2-dd82-41cb-99d7-4d11ef36b42e
// :: INFO spark.HttpServer: Starting HTTP Server
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'HTTP file server' on port .
// :: INFO spark.SparkEnv: Registering OutputCommitCoordinator
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'SparkUI' on port .
// :: INFO ui.SparkUI: Started SparkUI at http://192.168.244.147:4040
// :: INFO client.AppClient$ClientActor: Connecting to master akka.tcp://sparkMaster@spark01:7077/user/Master...
// :: INFO cluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app--
// :: INFO client.AppClient$ClientActor: Executor added: app--/ on worker--192.168.244.147- (192.168.244.147:) with cores
// :: INFO cluster.SparkDeploySchedulerBackend: Granted executor ID app--/ on hostPort 192.168.244.147: with cores, 512.0 MB RAM
// :: INFO client.AppClient$ClientActor: Executor updated: app--/ is now LOADING
// :: INFO client.AppClient$ClientActor: Executor updated: app--/ is now RUNNING
// :: INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO netty.NettyBlockTransferService: Server created on
// :: INFO storage.BlockManagerMaster: Trying to register BlockManager
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.244.147: with 265.4 MB RAM, BlockManagerId(driver, 192.168.244.147, )
// :: INFO storage.BlockManagerMaster: Registered BlockManager
// :: INFO cluster.SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
// :: INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
// :: INFO hive.HiveContext: Initializing execution hive, version 0.13.
// :: INFO metastore.HiveMetaStore: : Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore
// :: INFO metastore.ObjectStore: ObjectStore, initialize called
// :: INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
// :: INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
// :: INFO cluster.SparkDeploySchedulerBackend: Registered executor: AkkaRpcEndpointRef(Actor[akka.tcp://sparkExecutor@192.168.244.147:46741/user/Executor#-2043358626]) with ID 0
// :: WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.244.147: with 265.4 MB RAM, BlockManagerId(, 192.168.244.147, )
// :: WARN DataNucleus.Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
// :: INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"
// :: INFO metastore.MetaStoreDirectSql: MySQL check failed, assuming we are not on mysql: Lexical error at line , column . Encountered: "@" (), after : "".
// :: INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO DataNucleus.Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table.
// :: INFO metastore.ObjectStore: Initialized ObjectStore
// :: WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 0.13.1aa
// :: INFO metastore.HiveMetaStore: Added admin role in metastore
// :: INFO metastore.HiveMetaStore: Added public role in metastore
// :: INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
// :: INFO session.SessionState: No Tez session required at this point. hive.execution.engine=mr.
// :: INFO repl.SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext. scala>
打开spark shell以后,可以写一个简单的程序,say hello to the world
scala> println("helloworld")
helloworld
再来看看spark的web管理界面,可以看出,多了一个Workders和Running Applications的信息
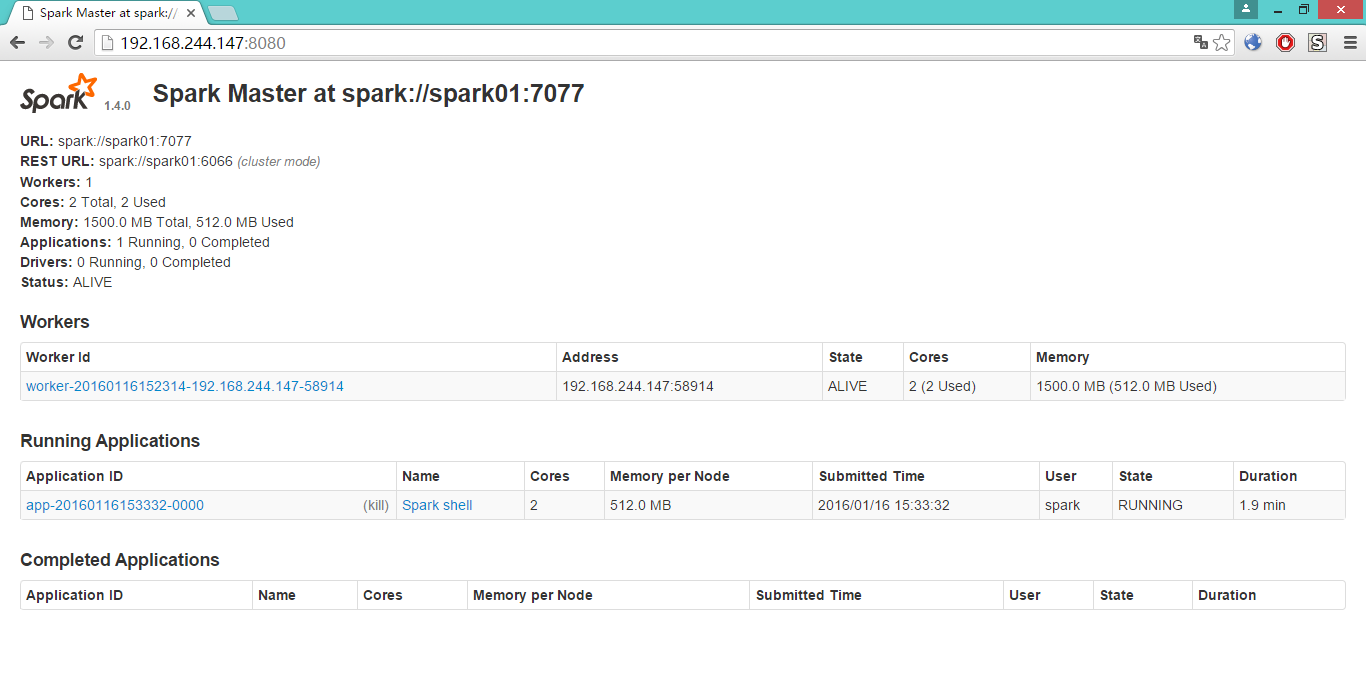
至此,Spark的伪分布式环境搭建完毕,
有以下几点需要注意:
1. 上述中的Maven和SBT是非必须的,只是为了后续的源码编译,所以,如果只是单纯的搭建Spark环境,可不用下载Maven和SBT。
2. 该Spark的伪分布式环境其实是集群的基础,只需修改极少的地方,然后copy到slave节点上即可,鉴于篇幅有限,后文再表。
搭建Spark的单机版集群的更多相关文章
- 搭建Spark高可用集群
Spark简介 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于AI人工智能 sp ...
- 高效搭建Spark全然分布式集群
写在前面一: 本文具体总结Spark分布式集群的安装步骤,帮助想要学习Spark的技术爱好者高速搭建Spark的学习研究环境. 写在前面二: 使用软件说明 约定,Spark相关软件存放文件夹:/usr ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- spark教程(一)-集群搭建
spark 简介 建议先阅读我的博客 大数据基础架构 spark 一个通用的计算引擎,专门为大规模数据处理而设计,与 mapreduce 类似,不同的是,mapreduce 把中间结果 写入 hdfs ...
- CentOS7.5搭建spark2.3.1集群
一 下载安装包 1 官方下载 官方下载地址:http://spark.apache.org/downloads.html 2 安装前提 Java8 安装成功 zookeeper 安 ...
随机推荐
- Spring MVC篇一、搭建Spring MVC框架
本项目旨在搭建一个简单的Spring MVC框架,了解Spring MVC的基础配置等内容. 一.项目结构 本项目使用idea intellij创建,配合maven管理.整体的目录结构如图: 其中ja ...
- 理解AUC
本文主要讨论了auc的实际意义,并给出了auc的常规计算方法及其证明 转载请注明出处:http://www.cnblogs.com/van19/p/5494908.html 1 ROC曲线和auc 从 ...
- Redis 的安装与使用(linux)
官方教程:http://www.redis.io/download 1.下载Redis # wget http://download.redis.io/releases/redis-3.0.4.tar ...
- 线性分式变换(linear fractional transformation)
线性分式变换(linear fractional transformation)的名称来源于其定义的形式:(ax+b)/(cx+d),其中分子分母是线性的,然后最外层是一个分式形式,所以叫做这个名字, ...
- Struct2 csv文件上传读取中文内容乱码
网络上搜索下,发现都不适合 最终改写代码: FileInputStream fis = null; InputStreamReader isr = null; BufferedReader br= n ...
- [原创]MySQL RR隔离级别下begin或start transaction开启事务后的可重复读?
Server version: 5.6.21-log MySQL Community Server (GPL) 前提提要: 我们知道MySQL的RR(repeatable read)隔 ...
- Excel数据导入数据库的SQL快速生成
=CONCATENATE("insert into table_name(id, code, name, remark) values (uuid(),'",B2,"', ...
- PHP常用算法
//二维数组的按某字段来排序(从小到大排序) function number_array_sort_asc($array,$key_name){ $arr = array(); foreach ($a ...
- .NET开源OpenID和OAuth解决方案Thinktecture IdentityServer
现代的应用程序看起来像这样: 典型的交互操作包括: 浏览器与 web 应用程序进行通信 Web 应用程序与 web Api (有时是在他们自己的有时代表用户) 通信 基于浏览器的应用程序与 web A ...
- Python黑帽编程2.2 数值类型
Python黑帽编程2.2 数值类型 数值类型,说白了就是处理各种各样的数字,Python中的数值类型包括整型.长整型.布尔.双精度浮点.十进制浮点和复数,这些类型在很多方面与传统的C类型有很大的区 ...