Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的《统计学习方法(第二版)》,对AdaBoost算法进行了学习。
在第八章的8.1.3小节中,举了一个具体的算法计算实例。美中不足的是书上只给出了数值解,这里用代码将它实现一下,算作一个课后作业。
一、算法简述
Adaboost算法最终输出一个全局分类模型,由多个基本分类模型组成,每个分类模型有一定的权重,用于表示该基本分类模型的可信度。最终根据各基本分类模型的预测结果乘以其权重,通过表决来生成最终的预测(分类)结果。
AdaBoost算法的训练流程图如下:
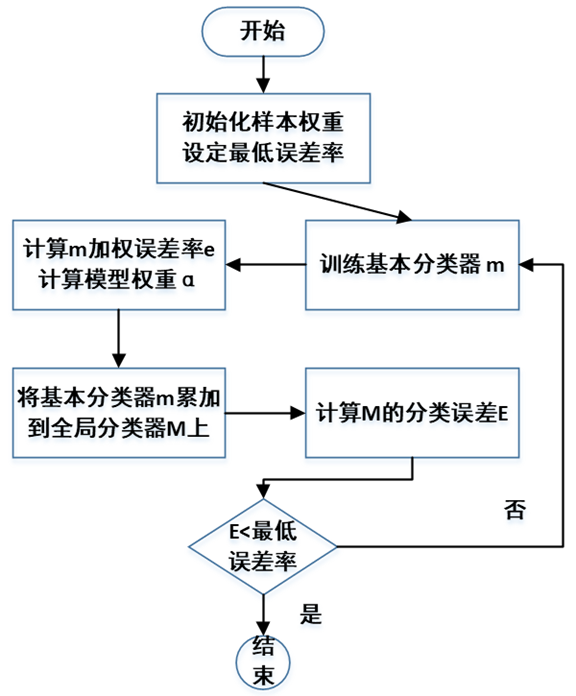 AdaBoost在训练过程中,每一轮循环生成一个基本分类器,并计算其权重,并将其加权累加到全局分类器中,最终在全局分类器的分类误差小于预设值时,结束训练,输出全局分类器。
AdaBoost在训练过程中,每一轮循环生成一个基本分类器,并计算其权重,并将其加权累加到全局分类器中,最终在全局分类器的分类误差小于预设值时,结束训练,输出全局分类器。
流程图中几个符合的含义和计算公式说明如下:
训练样本:共计10组数值,输入(X),输出(Y)如下:
1 data_X = [0,1,2,3,4,5,6,7,8,9]
2 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1]
m:即基本分类器,这里用的是一个决策树桩,即在X<v时,分类为-1或1,当X>v时,分类为1或-1。
e:基本分类器的加权误差率,权重为10个样本各自对应的权重。即统计预测错的样本其权重之和。书中公式如下:
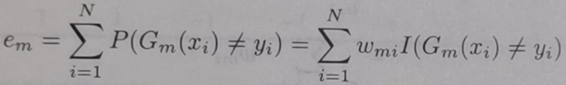
α:基本分类器的权重,就是其预测结果的可信度。书中公式如下:

M:全局分类器,由多个基本分类器与其可信度的乘积加和后得到。
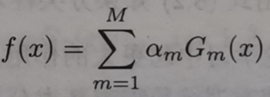
全局分类器在上述公式中即 f(x)。
另外还需要样本权值更新的公式,其中w即各个样本对应的权重,共N个样本,本例中N=10:
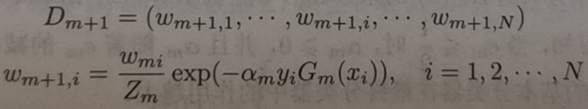
这里简单的引用公式讲解算法,具体可以看书中第八章的描述。不知道粘太多书中的内容会不会侵权=,=
二、代码讲解
下面讲一下代码。
考虑到后续有可能会将其他机器学习算法应用到AdaBoost中,为保证其有一定的拓展性,定义AdaBoost类。
1 class Adaboost(object):
2 def __init__(self,minist_error_rate):
3 self.minist_error_rate = minist_error_rate # 临界误差值,小于该误差即停止训练
4 self.model_list = [] # 记录模型,每一个模型包括[权重,v,方向]三个参数
这里仅初始了两个变量,一个是最低误差率,用来决定什么时候结束训练;另一个是全局分类器对象,list类型;而基本分类器也是list,格式为[权重,v,方向],其中,v就是决策树桩m的分界值。
定义权重初始化函数:
1 def ini_weight(self,sample_x,sample_y): # 初始化样本权重 D ,即D1
2 self.D = [float(1)/len(sample_y)]
3 self.D = self.D*len(sample_y)
使用均值法来进行初始化,10个样本,每个样本的初始权重设为0.1。
之后,再定义单样本预测函数及基本分类器的训练函数。其中,基本分类器训练函数将初始的v值设为0.5,每循环自增1来遍历所有可能性,寻找加权错误率(e)最低的v值。
1 def prediction(self,v_num,direct,input_num):
2 if(input_num<v_num):
3 return direct
4 else:
5 return -direct
6
7 def train_op(self,sample_x,sample_y): # 获取在样本权重下的训练结果
8 error_temp = 9999.9
9 v_record = 0.0
10 direct = 0 # 预测方向,即输入小于v_record时, 样本的预测值为 1 还是 -1 ,
11 for i in range(len(sample_x)-1):
12 v_num = float(i)+0.5
13 # 正向计算一次,即小于v_num 为-1,否则1
14 error_1 = 0.0
15 for j in range(len(sample_x)):
16 pred = self.prediction(v_num,-1,sample_x[j])
17 if(pred!=sample_y[j]):
18 error_1 += self.D[j]*1
19 if(error_1<error_temp):
20 v_record = v_num
21 direct = -1
22 error_temp = error_1
23 # 相反方向再计算一次,即小于v_num 为1,否则-1
24 error_1 = 0.0
25 for j in range(len(sample_x)):
26 pred = self.prediction(v_num,1,sample_x[j])
27 if(pred!=sample_y[j]):
28 error_1 += self.D[j]*1
29 if(error_1<error_temp):
30 v_record = v_num
31 direct = 1
32 error_temp = error_1
33 return error_temp,v_record,direct
有了单个基本训练器的计算函数,下面就需要构建AdaBoost算法的主循环,即计算该基本训练器的权重α并将其纳入全局分类器M。主要依靠update函数实现。
1 def update(self,sample_x,sample_y):
2 error_now,v_record,direct = self.train_op(sample_x,sample_y)
3 print(error_now,v_record,direct)
4 alpha = 0.5*math.log((1-error_now)/error_now)
5 print(alpha)
6 self.model_list.append([alpha,v_record,direct])
7 err_rate = self.error_rate(sample_x,sample_y)
8 while(err_rate>self.minist_error_rate):
9 Zm = 0.0
10 for i in range(len(sample_x)):
11 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i])
12 # 更新 样本权重向量self.D
13 for i in range(len(sample_y)):
14 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm
15 error_now,v_record,direct = self.train_op(sample_x,sample_y)
16 alpha = 0.5*math.log((1-error_now)/error_now)
17 self.model_list.append([alpha,v_record,direct])
18 err_rate = self.error_rate(sample_x,sample_y)
主循环靠while循环来实现,全局模型分类误差率小于设定的最低误差率时,停止循环,输出全局分类器。
最终在main函数中,调用该类,按顺序执行初始化样本权重、执行主循环、打印模型结构。
1 if __name__ == "__main__":
2 ada_obj = Adaboost(0.005)
3 ada_obj.ini_weight(data_X,data_Y)
4 ada_obj.update(data_X,data_Y)
5 ada_obj.print_model()
其中,最低误差率设为0.005,在本例中即要求10个样本全部分类正确。最终程序输出:

可以看出全局分类器由3个基本分类器组成,权重即为基本分类器的可信度,临界值则为v值,方向则设定为输入小于v值时,分类的结果。即第一个模型(0 layer)为当输入小于2.5时,分类结果为1;否则为-1。解得的答案也与书中结果相同。
下面是全部代码,感兴趣同学可以在python环境中试一试。
1 # coding:utf-8
2
3 import math
4 import numpy as np
5
6 data_X = [0,1,2,3,4,5,6,7,8,9]
7 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1]
8
9 # data_X = [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
10 # data_Y = [1,1,1,-1,-1,-1,1,1,1,-1,1,1,-1,-1]
11
12 print(len(data_X),len(data_Y))
13
14 class Adaboost(object):
15 def __init__(self,minist_error_rate):
16 self.minist_error_rate = minist_error_rate # 临界误差值,小于该误差即停止训练
17 self.model_list = [] # 记录模型,每一个模型包括[权重,v,方向]三个参数
18
19 def ini_weight(self,sample_x,sample_y): # 初始化样本权重 D ,即D1
20 self.D = [float(1)/len(sample_y)]
21 self.D = self.D*len(sample_y)
22
23 def prediction(self,v_num,direct,input_num):
24 if(input_num<v_num):
25 return direct
26 else:
27 return -direct
28
29 def train_op(self,sample_x,sample_y): # 获取在样本权重下的训练结果
30 error_temp = 9999.9
31 v_record = 0.0
32 direct = 0 # 预测方向,即输入小于v_record时, 样本的预测值为 1 还是 -1 ,
33 for i in range(len(sample_x)-1):
34 v_num = float(i)+0.5
35 # 正向计算一次,即小于v_num 为-1,否则1
36 error_1 = 0.0
37 for j in range(len(sample_x)):
38 pred = self.prediction(v_num,-1,sample_x[j])
39 if(pred!=sample_y[j]):
40 error_1 += self.D[j]*1
41 if(error_1<error_temp):
42 v_record = v_num
43 direct = -1
44 error_temp = error_1
45 # 相反方向再计算一次,即小于v_num 为1,否则-1
46 error_1 = 0.0
47 for j in range(len(sample_x)):
48 pred = self.prediction(v_num,1,sample_x[j])
49 if(pred!=sample_y[j]):
50 error_1 += self.D[j]*1
51 if(error_1<error_temp):
52 v_record = v_num
53 direct = 1
54 error_temp = error_1
55 return error_temp,v_record,direct
56
57 def one_model_pred(self,input_num,model_num): # 计算单个子模型的预测结果
58 m = self.model_list[model_num]
59 return self.prediction(m[1],m[2],input_num)
60
61 def error_rate(self,sample_x,sample_y): # 计算各子模型投票表决的错误率
62 wrong_num = 0
63 for i in range(len(sample_y)):
64 out = 0.0
65 for j in range(len(self.model_list)):
66 out_temp = self.model_list[j][0]*self.one_model_pred(sample_x[i],j)
67 out += out_temp
68 if(out>=0):
69 out = 1
70 else:
71 out = -1
72 if(out==sample_y[i]):
73 pass
74 else:
75 wrong_num += 1
76 return float(wrong_num)/len(sample_y)
77
78 def update(self,sample_x,sample_y):
79 error_now,v_record,direct = self.train_op(sample_x,sample_y)
80 # print(error_now,v_record,direct)
81 alpha = 0.5*math.log((1-error_now)/error_now)
82 # print(alpha)
83 self.model_list.append([alpha,v_record,direct])
84 err_rate = self.error_rate(sample_x,sample_y)
85 while(err_rate>self.minist_error_rate):
86 Zm = 0.0
87 for i in range(len(sample_x)):
88 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i])
89 # 更新 样本权重向量self.D
90 for i in range(len(sample_y)):
91 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm
92 error_now,v_record,direct = self.train_op(sample_x,sample_y)
93 alpha = 0.5*math.log((1-error_now)/error_now)
94 self.model_list.append([alpha,v_record,direct])
95 err_rate = self.error_rate(sample_x,sample_y)
96
97 def print_model(self):
98 print('模型打印: 权重 临界值 方向')
99 for i in range(len(self.model_list)):
100 print(str(i)+' layer :'+str(self.model_list[i][0])+' '+str(self.model_list[i][1])+' '+str(self.model_list[i][2]))
101
102 if __name__ == "__main__":
103 ada_obj = Adaboost(0.005)
104 ada_obj.ini_weight(data_X,data_Y)
105 ada_obj.update(data_X,data_Y)
106 ada_obj.print_model()
参考:
Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章的更多相关文章
- 通过Dapr实现一个简单的基于.net的微服务电商系统(六)——一步一步教你如何撸Dapr之Actor服务
我个人认为Actor应该是Dapr里比较重头的部分也是Dapr一直在讲的所谓"stateful applications"真正具体的一个实现(个人认为),上一章讲到有状态服务可能很 ...
- struts1:(Struts重构)构建一个简单的基于MVC模式的JavaWeb
在构建一个简单的基于MVC模式的JavaWeb 中,我们使用了JSP+Servlet+JavaBean构建了一个基于MVC模式的简单登录系统,但在其小结中已经指出,这种模式下的Controller 和 ...
- 一个简单的基于 DirectShow 的播放器 2(对话框类)
上篇文章分析了一个封装DirectShow各种接口的封装类(CDXGraph):一个简单的基于 DirectShow 的播放器 1(封装类) 本文继续上篇文章,分析一下调用这个封装类(CDXGrap ...
- 一个简单的基于 DirectShow 的播放器 1(封装类)
DirectShow最主要的功能就是播放视频,在这里介绍一个简单的基于DirectShow的播放器的例子,是用MFC做的,今后有机会可以基于该播放器开发更复杂的播放器软件. 注:该例子取自于<D ...
- 并发编程概述 委托(delegate) 事件(event) .net core 2.0 event bus 一个简单的基于内存事件总线实现 .net core 基于NPOI 的excel导出类,支持自定义导出哪些字段 基于Ace Admin 的菜单栏实现 第五节:SignalR大杂烩(与MVC融合、全局的几个配置、跨域的应用、C/S程序充当Client和Server)
并发编程概述 前言 说实话,在我软件开发的头两年几乎不考虑并发编程,请求与响应把业务逻辑尽快完成一个星期的任务能两天完成绝不拖三天(剩下时间各种浪),根本不会考虑性能问题(能接受范围内).但随着工 ...
- 构建一个简单的基于MVC模式的JavaWeb
零晨三点半了,刚刚几个兄弟一起出去吼歌,才回来,这应该是我大学第二次去K歌,第一次是大一吧,之后每次兄弟喊我,我都不想去,因为我还是很害怕去KTV,或许是因为那里是我伤心的地方,也或许是因为我在那里失 ...
- 从零开始搭建一个简单的基于webpack的vue开发环境
原文地址:https://segmentfault.com/a/1190000012789253?utm_source=tag-newest 从零开始搭建一个简单的基于webpack的react开发环 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(四)——一步一步教你如何撸Dapr之订阅发布
之前的章节我们介绍了如何通过dapr发起一个服务调用,相信看过前几章的小伙伴已经对dapr有一个基本的了解了,今天我们来聊一聊dapr的另外一个功能--订阅发布 目录:一.通过Dapr实现一个简单的基 ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统
本来想在Dpar 1.0GA时发布这篇文章,由于其他事情耽搁了放到现在.时下微服务和云原生技术如何如荼,微软也不甘示弱的和阿里一起适时推出了Dapr(https://dapr.io/),园子里关于da ...
随机推荐
- async-await和Promise的关系
关于异步处理,ES5的回调使我们陷入地狱,ES6的Promise使我们脱离魔障,终于.ES7的async-await带我们走向光明.今天就来学习一下 async-await. 经常会看到有了 asyn ...
- 正式班D9
2020.10.16星期五 正式班D9 一.vmware workstation的使用 虚拟机管理软件 定义 虚拟机(Virtual Machine)软件是一套特殊的软件,它可以作为操作系统独立运行, ...
- 干货分享:用一百行代码做一个C/C++表白小程序,程序员的浪漫!
前言:很多时候,当别人听到你是程序员的时候.第一印象就是,格子衫.不浪漫.直男.但是程序员一旦浪漫起来,真的没其他人什么事了.什么纪念日,生日,情人节,礼物怎么送? 做一个浪漫的程序给她,放上你们照片 ...
- Pytest学习(四) - fixture的使用
前言 写这篇文章,整体还是比较坎坷的,我发现有知识断层,理解再整理写出来,还真的有些难. 作为java党硬磕Python,虽然对我而言是常事了(因为我比较爱折腾,哈哈),但这并不能影响我的热情. 执念 ...
- ES index not_analyzed
在最初创建索引mapping时,未指定index:not_analyzed "exact_value": { "type": "string" ...
- 【应用服务 App Service】App Service中上传文件/图片(> 2M)后就出现500错误(Maximum request length exceeded).
问题描述 在使用App Service (Windows)做文件/图片上传时候,时常遇见上传大文件时候出现错误,这是因为IIS对文件的大小由默认限制.当遇见(Maximum request lengt ...
- ES6字符串随笔
ES6对JavaScript的变动的很大,增加了一些新特性. 字符串模板: 字符串模块使用``来表示,相比原来使用双引号来标记,多了许多便利性 1 // 原始的标记使用+来连接,遇到一些复杂的字符串会 ...
- JSP标签语法、JSTL标签库、EL表达式辨析
<一.JSP > JSP 语法语法格式: <% 代码片段 %>或者<jsp:scriptlet> 代码片段</jsp:scriptlet> JSP声明 ...
- oracle 日常删除多余数据
查询及删除重复记录的SQL语句 1.查找表中多余的重复记录,重复记录是根据单个字段(Id)来判断 select * from 表 where Id in (select Id from 表 g ...
- SpringBoot+Mybatis_Plus Generator
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity.Mapper.Mapper XML.Service.Control ...