Python淘宝商品比价定向爬虫
1.项目基本信息
目标: 获取淘宝搜索页面的信息,提取其中的商品名称和价格
理解: 淘宝的搜索接口、翻页的处理
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
URL样式: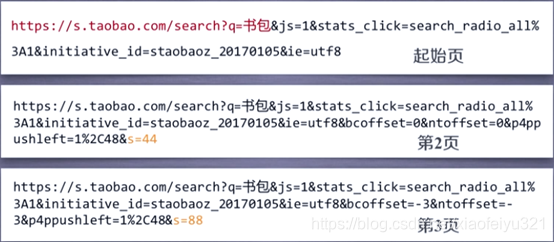
2.程序的结构设计
步骤1:提交商品搜索请求,循环获取页面
步骤2:对于每个页面,提取商品名称和价格信息
步骤3:将信息输出到屏幕上
3.Cookie内容的获取
由于淘宝的反爬机制,需要修改请求头,添加Cookie信息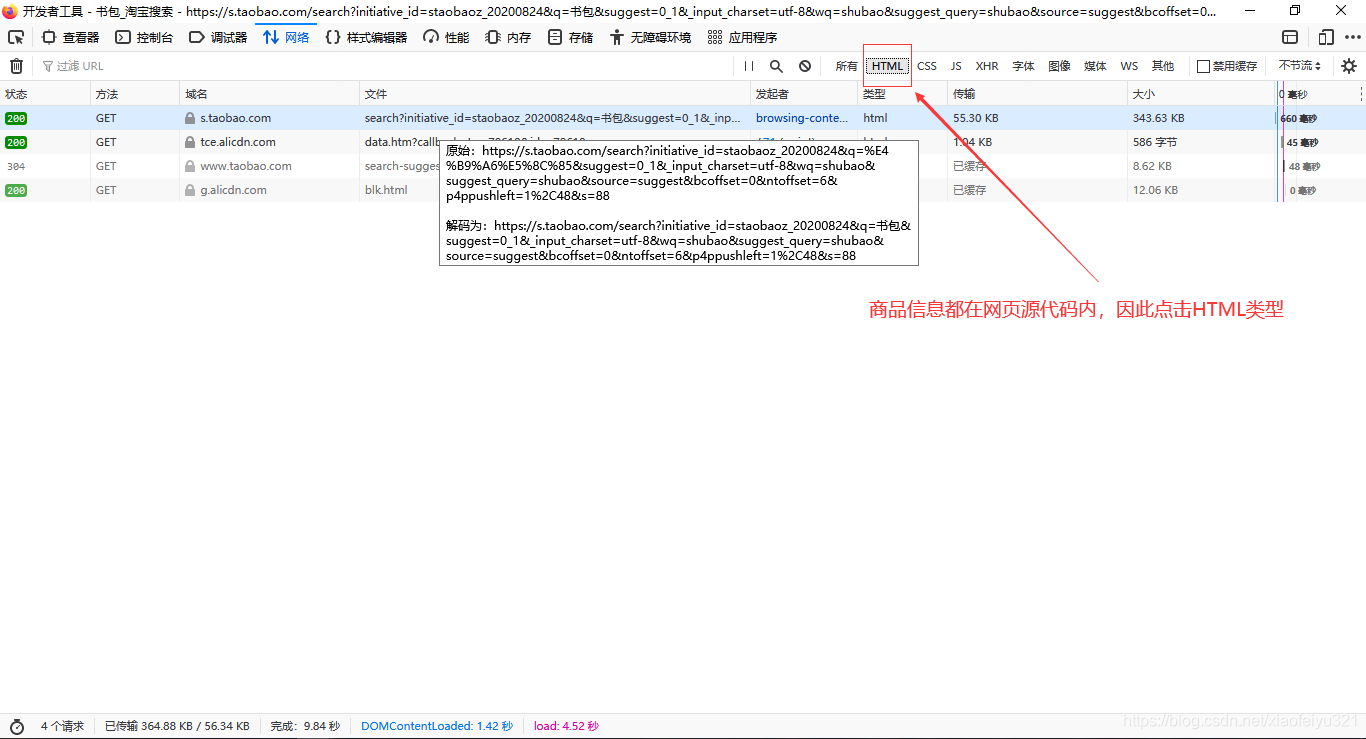
运行结果:
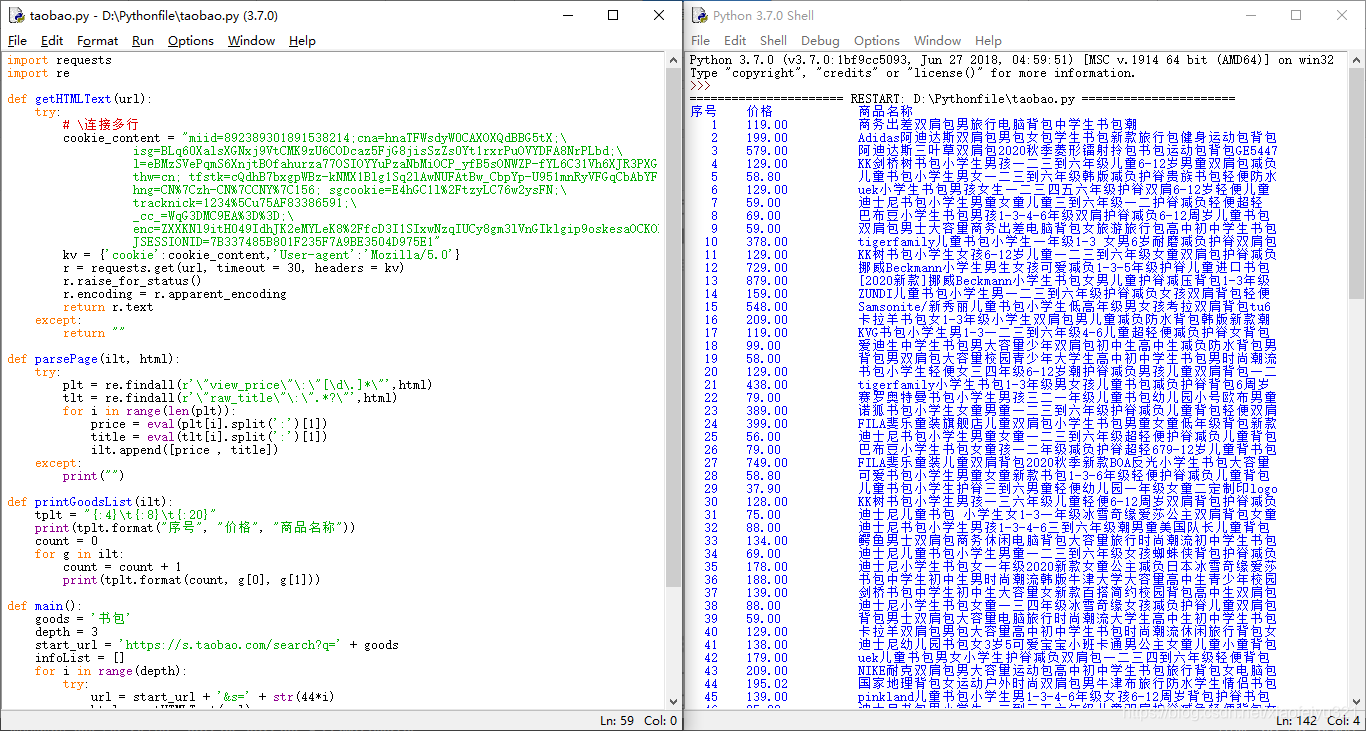
4.代码
import requests
import re
def getHTMLText(url):
try:
# \连接多行
cookie_content = "miid=892389301891538214;cna=hnaTFWsdyW0CAXOXQdBBG5tX;\
isg=BLq60XalsXGNxj9VtCMK9zU6CODcaz5FjG8jisSzZs0Yt1rxrPuOVYDFA8NrPLbd;\
l=eBMzSVePqmS6XnjtBOfahurza77OSIOYYuPzaNbMiOCP_yfB5sONWZP-fYL6C31Vh6XJR3PXGizJBeYBqQAonxv92j-la_kmn;\
thw=cn; tfstk=cQdhB7bxgpWBz-kNMX1Blg1Sq2lAwNUFAtBw_CbpYp-U951mnRyVFGqCbAbYF;\
hng=CN%7Czh-CN%7CCNY%7C156; sgcookie=E4hGC1l%2FtzyLC76w2ysFN;\
tracknick=1234%5Cu75AF83386591;\
_cc_=WqG3DMC9EA%3D%3D;\
enc=ZXXKNl9itH049IdhJK2eMYLeK8%2FfcD3I1SIxwNzqIUCy8gm3lVnGIklgip9oskesaOCKOk1XtRfY96Hi%2F%2FhdKw%3D%3D;\
JSESSIONID=7B337485B801F235F7A9BE3504D975E1"
kv = {'cookie':cookie_content,'User-agent':'Mozilla/5.0'}
r = requests.get(url, timeout = 30, headers = kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:20}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()Python淘宝商品比价定向爬虫的更多相关文章
- python3----练习题(爬取电影天堂资源,大学排名,淘宝商品比价)
import requests import re url = 'http://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html' for n in range ...
- 手把手教你写电商爬虫-第四课 淘宝网商品爬虫自动JS渲染
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
- Python 中国大学排名定向爬虫
代码来自于中国大学Mooc北京理工大学Pythont教学团队:https://www.icourse163.org/learn/BIT-1001870001#/learn/content?type=d ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- selenium+chrome抓取淘宝宝贝-崔庆才思路
站点分析 源码及遇到的问题 在搜索时,会跳转到登录界面 step1:干起来! 先取cookie step2:载入cookie step3:放飞自我 关于phantomJS浏览器的问题 源码 站点分析 ...
- 淘宝API总结
1. 淘宝客API https://open.alimama.com/?spm=a219t.11816995.1998910419.d8546b700.2a8f75a5C0NajI#!/documen ...
- Python天猫淘宝评论爬虫
说明 由于Github 打包的exe某些文件上传被.gitignore了,所以不提供windows二进制包 https://github.com/hunterhug/taobaocomment 一个抓 ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- Python的几个爬虫代码整理(网易云、微信、淘宝、今日头条)
整理了一下网易云歌曲评论抓取.分析好友信息抓取.淘宝宝贝抓取.今日头条美图抓取的一些代码 抓取网易云评论 进入歌曲界面: http://music.163.com/#/song?id=45318582 ...
随机推荐
- 基于asp.net core 从零搭建自己的业务框架(二)
前言 对于项目的迭代,如何降低复杂性的要求高于性能以及技术细节的 一个易用的项目,才能迭代到比拼性能,最后拼刺刀的阶段 传统单体项目,都是传统三层,直接请求响应的模式,这类称为Rpc模式,易用性上非常 ...
- .net core下获取自身服务器地址
网上的例子千篇一律都是Request.HttpContext.Connect.Connection.XX这种 或者依赖于IHttpContextAccessor的 而我的场景是在非控制器流程获取自身服 ...
- demo3同通讯录展示的方式分组排序
按A-Z顺序分组展示 有些项目中会需要这样的需求.形成类似于上述的界面.类似于通讯录里边的排序.实现的效果:所有的数据展示的时候,能够分组展示.顺序按照A-Z的书序进行排列.如果不是以A-Z开头,则默 ...
- tree命令编译使用
有天在linux中使用tree命令时候显示--未找到命令 记下解决过程: wget ftp://mama.indstate.edu/linux/tree/tree-1.6.0.tgz tar xzv ...
- Ubuntu定时执行任务(定时爬取数据)
cron是一个Linux下的后台进程,用来定期的执行一些任务.因为我用的是Ubuntu,所以这篇文章中的所有命令也只能保证在Ubuntu下有效. 1:编辑crontab文件,用来存放你要执行的命令 s ...
- Android Studio项目组织结构
任何一个新建的项目都会默认使用一个Android模式的项目结构,这个结构是被Android Studio转换过的,适合快速开发,但不易于理解,切换到Project模式后如下: 重点认识一下重要的几个文 ...
- windows系统下python setup.py install ---出现cl问题,cpp_extension.py:237: UserWarning: Error checking compiler version for cl: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
将cpp_extension.py文件中的 原始的是 compiler_info.decode() try: if sys.platform.startswith('linux'): minimu ...
- XCTF-WEB-高手进阶区-Web_python_template_injection-笔记
Web_python_template_injection o(╥﹏╥)o从这里开始题目就变得有点诡谲了 网上搜索相关教程的确是一知半解,大概参考了如下和最后的WP: http://shaobaoba ...
- java 异常二
一 捕获异常try…catch…finally 捕获:Java中对异常有针对性的语句进行捕获,可以对出现的异常进行指定方式的处理 捕获异常格式: try { //需要被检测的语句. } catch(异 ...
- Manacher(马拉车)算法(jekyll迁移)
layout: post title: Manacher(马拉车)算法 date: 2019-09-07 author: xiepl1997 cover: 'assets/img/manacher.p ...