梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART
用 CART 决策树来作为 Adaboost 的基础学习器

但是问题在于,需要把决策树改成能接收带权样本输入的版本。(need: weighted DTree(D, u(t)) )
这样可能有点麻烦,有没有简单点的办法?尽量不碰基础学习器内部,想办法在外面把数据送进去的时候做处理,能等价于给输入样本权重。(boostrapping)

例如权重 u 的占比是30%的样本,对应的 sampling 的概率就设定为 0.3。
每一个基础学习器在整体模型中的重要性还是用 αt 来衡量(gt 在 G 中的系数)。另外,这个方法中仍然是 boosting, CART 一定不能太强(剪枝比较多、简单点就限制树高度;训练每棵树都只用一部分训练数据)

极端情况,限制树的高度只有1,那就直接退化成 decision stump ,也就不用做 sampling 了(因为几乎不会只用 stump 就能让 error rate = 0)

GBDT
梯度提升树(GBDT)也是一种前向分步算法,但基础模型限定了使用 CART 回归树。在学习过程中,第 t 轮迭代的目标是找到一个 CART 回归树 gt(x) 让本轮的损失函数 L(y, Gt(x)) = L(y, Gt-1(x) + gt(x)) 尽量小。
从 Adaboost 到 general boosting
负梯度拟合的优势就是可以在通用框架下拟合各种损失误差,这样分类回归都能做。在 ensemble https://www.cnblogs.com/chaojunwang-ml/p/11208164.html 分析过,这里再回顾一遍。
统一每次更新样本权重的形式(gt-1(x) 正确分类的样本权重减小,错误分类的样本权重增加)

那么根据递推公式,unT+1 可以从 un1 推得,而表达式中正好可以发现 G(x) 的 logit(voting score)。

而 yn * voting score 可以理解为点到分割平面的一种距离衡量,类似于 SVM 中的 margin,只不过没有归一化。而模型的训练目标就是想要让 margin 正的越大越好,等价于让 unT+1 越小越好。也就是说,adaboost 中所有样本的 un 之和会随着时间步推移越来越小(让每一个点的 margin 都越来越正、越来越大)。

这样就可以看出 adaboost 整体模型的要最小化的目标函数,是所有时间步的所有样本权重之和,即0/1损失函数的upper bound(指数损失函数)。
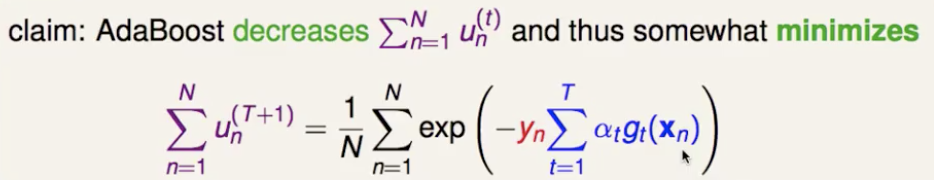

就用梯度下降(泰勒一阶展开)来实现这个最小化(不同的是,这里要求 loss 函数对 gt(x) 函数的梯度,approximate functional gradient)。把1/N拿进去,紫色部分凑成 unt ,对剩下的exp部分用泰勒公式一阶逼近,整理得到最终要对 h 求梯度的目标函数。

那就来看一下,发现最小化整体模型的目标函数,就等价于最小化 Einu(t) ,就是要优化基础分类器(也就是说,adaboost中前向分步训练基础分类器,其实正是在为整体模型的梯度下降优化找最好的gt(x) )


再来就是要确定学习率,能不能每步都找到一个最好的学习率(短期内比固定的学习率下降的快)?steepest descent:loss 对其求导并另为0。得到的最好的学习率,正是 adaboost 中的 αt
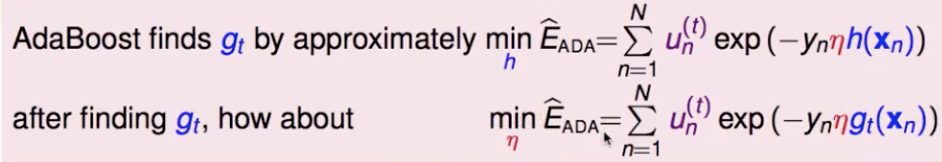

从梯度下降的角度再次总结 adaboost 做分类

gradient boosting
负梯度拟合的扩展,不只用指数损失函数,用其他的损失函数(符合平滑条件)也可以。从目前已经达到的 G(xn) ,向某一个方向(h(xn))走一小步(η),使得新的 logit 与给定的 yn 之间的某种 error 变小。

以平方误差举例,error = (s-y)2

如果在某处往某个方向走了一小步,就要乘上 gradient 在那个地方的分量(error 对 s 偏微分,在sn 处取值)。然后就是找一个 h,让下面式子的第二项越小越好(第一项与h无关)。直接的想法是:如果 s-y 是正的,就给一个负的 h ;如果 s-y 是负的,就给一个正的 h 。那么就让 h 取到 s-y 的负方向。
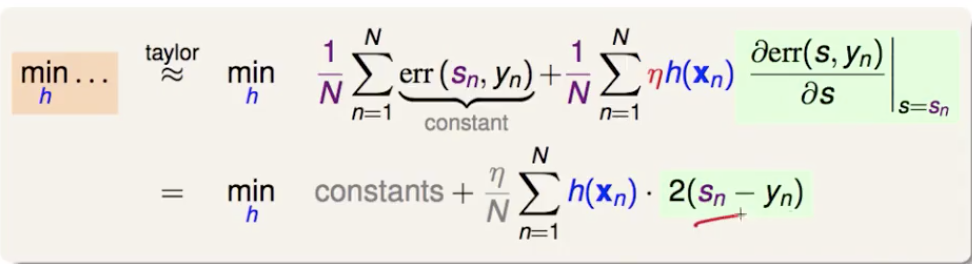
但 h 的大小呢?如果不加约束,h(xn) = - ∞ * (sn-yn) ,可是我们这里找 h 只是要找一个方向,所以步长靠 η 决定。加一个正则化惩罚项即可。然后凑一个 (h(xn) - (yn - sn))2 出来,配上一个和 h 无关的常数项。要最小化这个式子,就是要令 h(xn) 和 (yn - sn) 之间的均方误差最小,那就是以残差 residual 为目标训练一个回归器。

然后决定 η 的大小,单变量最优化问题。但这里除了求偏微分令其等于0,还有一种简洁的求法。把 gt(xn) 看成是feature,residual 看成简单线性回归的目标, 求这个一维的权重。


optimal η 的解为

加入 CART 作为 base learner,总结一下 GBDT

关于 GBDT 做分类的详解:https://www.cnblogs.com/pinard/p/6140514.html
梯度提升树 Gradient Boosting Decision Tree的更多相关文章
- Gradient Boosting Decision Tree学习
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple ...
- GBDT(Gradient Boosting Decision Tree) 没有实现仅仅有原理
阿弥陀佛.好久没写文章,实在是受不了了.特来填坑,近期实习了(ting)解(shuo)到(le)非常多工业界经常使用的算法.诸如GBDT,CRF,topic model的一些算 ...
- 论文笔记:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
引言 GBDT已经有了比较成熟的应用,例如XGBoost和pGBRT,但是在特征维度很高数据量很大的时候依然不够快.一个主要的原因是,对于每个特征,他们都需要遍历每一条数据,对每一个可能的分割点去计算 ...
- GBDT(Gradient Boosting Decision Tree)算法&协同过滤算法
GBDT(Gradient Boosting Decision Tree)算法参考:http://blog.csdn.net/dark_scope/article/details/24863289 理 ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- Gradient Boosting Decision Tree
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类.当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式 ...
- 后端程序员之路 10、gbdt(Gradient Boosting Decision Tree)
1.GbdtModelGNode,含fea_idx.val.left.right.missing(指向left或right之一,本身不分配空间)load,从model文件加载模型,xgboost输出的 ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- 梯度提升树(GBDT)原理小结(转载)
在集成学习值Adaboost算法原理和代码小结(转载)中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boos ...
随机推荐
- Maven快速入门(四)Maven中的pom.xml文件详解
上一章,我们讲了Maven的坐标和仓库的概念,介绍了Maven是怎么通过坐标找到依赖的jar包的.同时也介绍了Maven的中央仓库.本地仓库.私服等概念及其作用.这些东西都是Maven最基本.最核心的 ...
- 使用script打开页面
<script src="x" onerror=javascript:window.open("http://192.168.38.1/csrf.html" ...
- [U3D + GAD]Egametang开源服务器框架资源管理系统
Egametang开源服务器框架资源管理系统详解 http://m.gad.qq.com/article/detail/36409 ET GitHub https://github.com/egame ...
- MinGW-w64安装过程中出现ERROR res错误的问题
使用 mingw-get-setup.exe 安装.在官网http://www.mingw.org/上搜索download/installer,点击下载. 如果使用 mingw-w64-install ...
- Unity 移动平台自己编写Shader丢失问题
问题一:使用AB加载资源,资源中包含有第三方shader,加载出的资源出现shader丢失的显示问题 这是因为Unity在打包的时候,会进行资源精简,默认情况下,是不会将第三方shader打包进入包体 ...
- Pets(匈牙利算法)
Are you interested in pets? There is a very famous pets shop in the center of the ACM city. There ar ...
- hacker101 CTF 学习记录(二)
前言 无 Easy-Postbook 拿到功能有点多,先扫一遍目录 .Ds_Store没有啥东西,page是个静态页面 随便注册个账号,登录后已经有2篇文章,第一篇文章的id是1 自己创建文章,将ur ...
- 3.CDN加速简介
什么是CDN CDN的全称是Content Delivery Network,即内容分发网络.CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问 ...
- MySQL隐式转换的坑
MySQL以以下规则描述比较操作如何进行转换: 两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做 ...
- CentOS7使用PackageCloud安装RabbitMQ
环境:CentOS Linux release 7.6.1810 (Core) RabbitMQ:3.7.17Erlang: 22.0.7 使用PackageCloud安装RabbitMQ是最简单的安 ...