Trino总结
文章目录
- 1.Trino与Spark SQL的区别分析
- 2.Trino与Spark SQL解析过程对比
- 3.Trino基本概念
- 4.Trino架构
- 5.Trino SQL执行流程
- 6.Trino Task执行流程
- 相关参考:
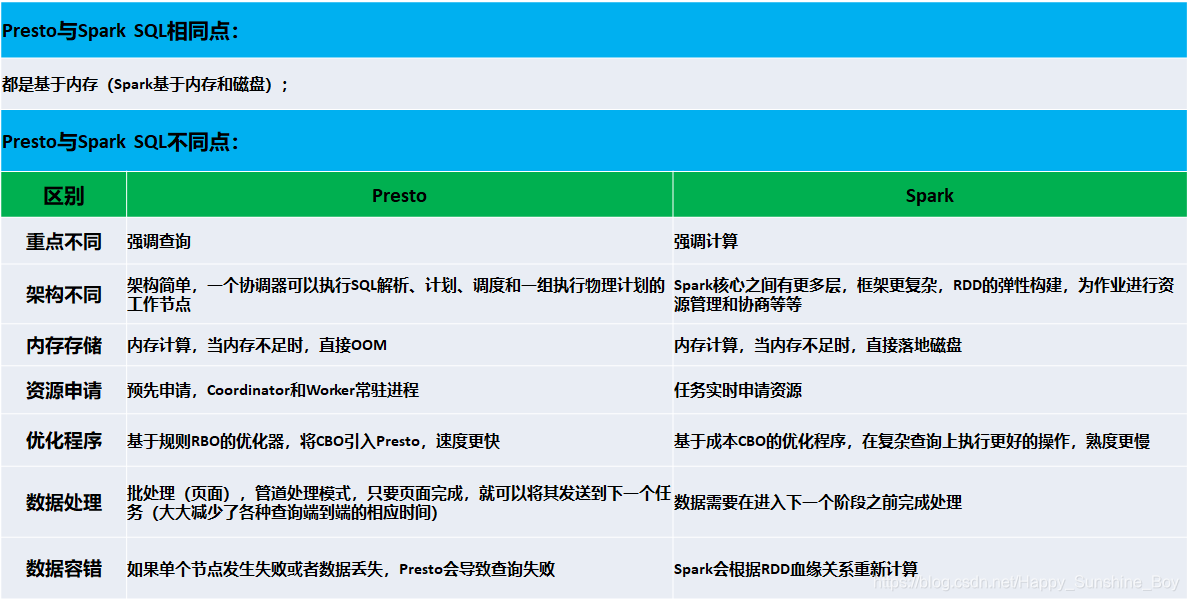
1.Trino与Spark SQL的区别分析
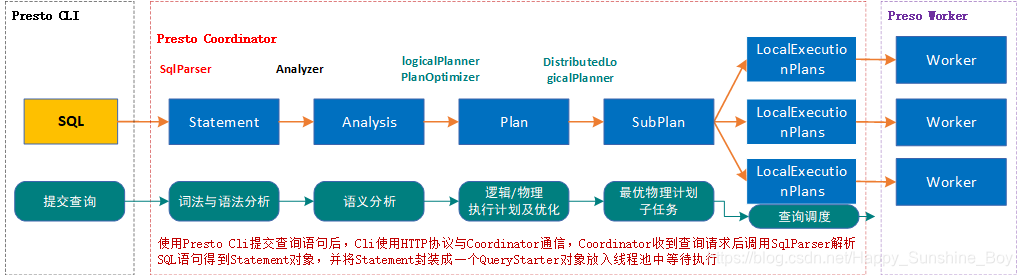
2.Trino与Spark SQL解析过程对比
- Trino
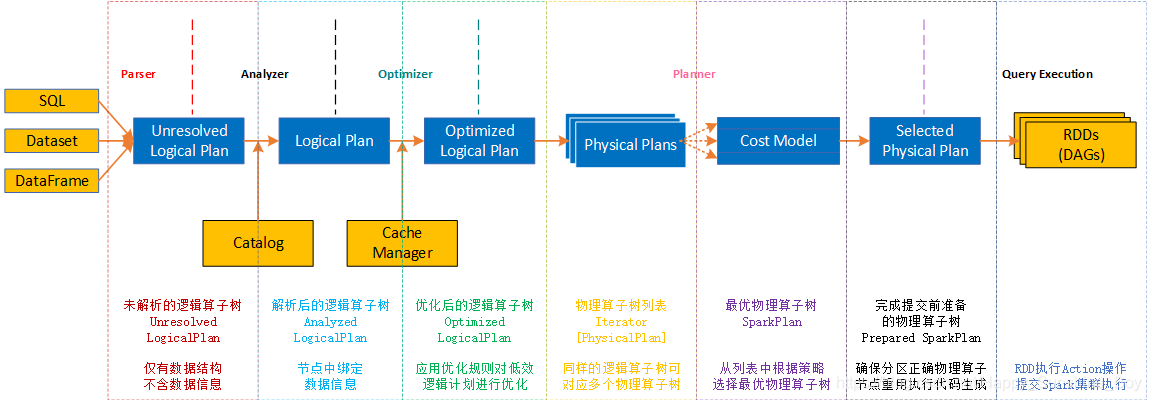
- Spark SQL
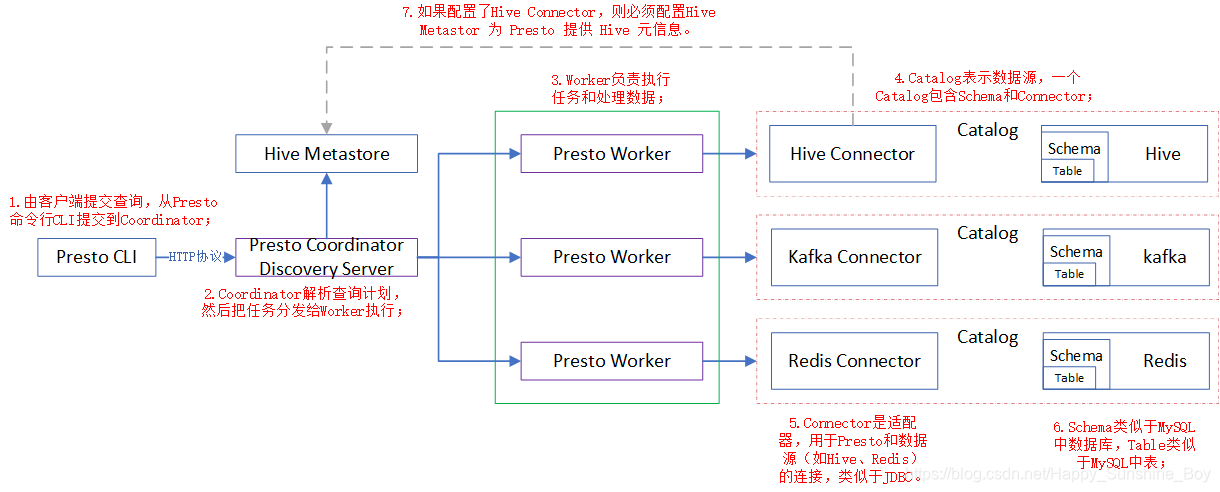
3.Trino基本概念

4.Trino架构

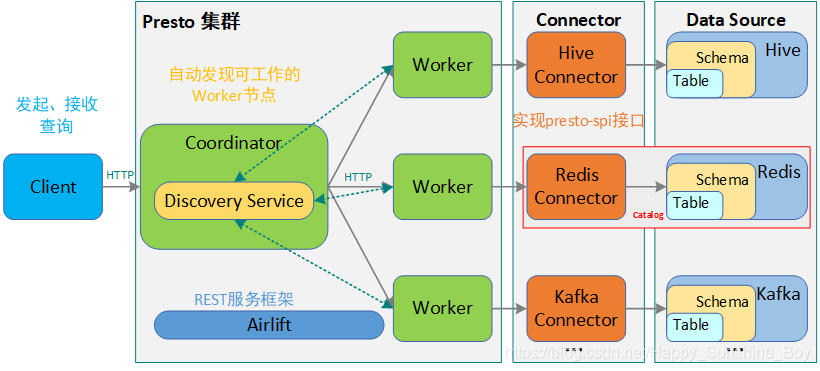
5.Trino SQL执行流程
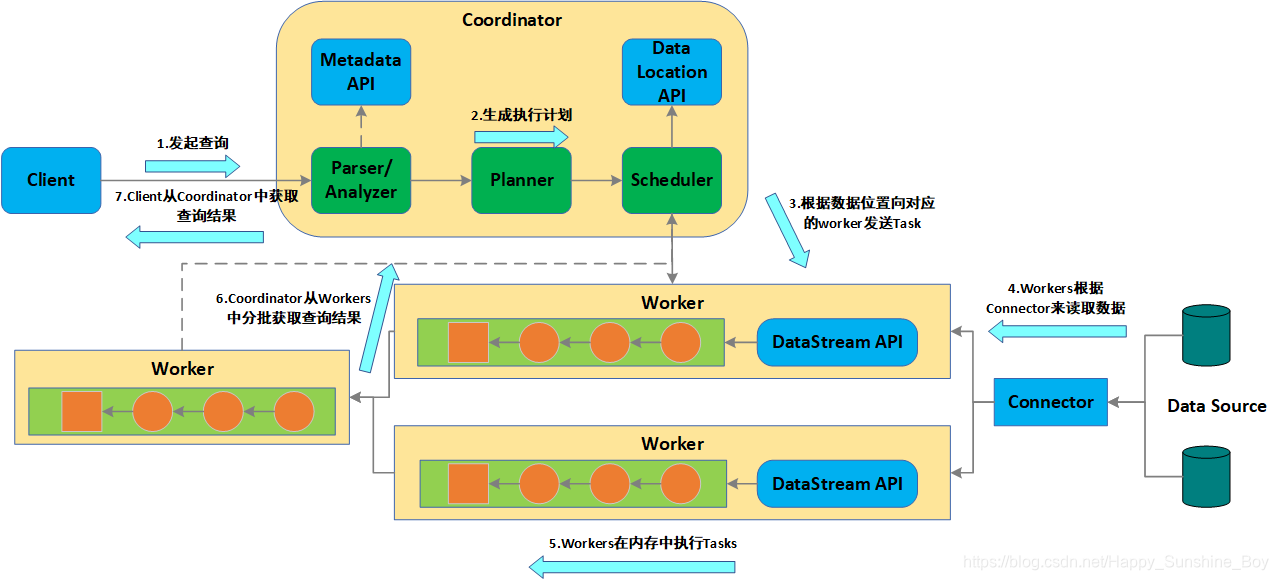
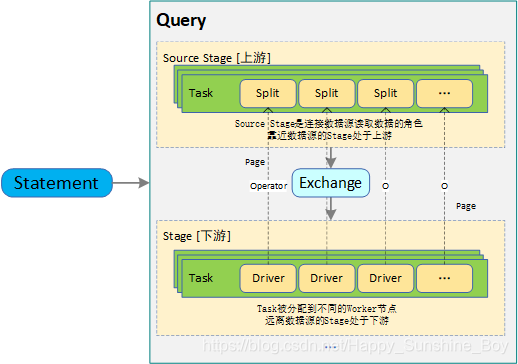
6.Trino Task执行流程
任务调度:
1.分配多少个任务?
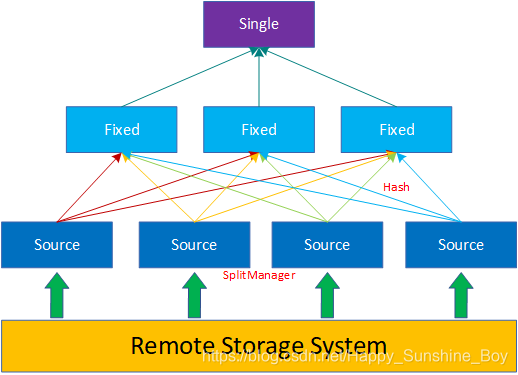
2.每个任务分配到哪些机器节点上?拓扑调度算法 (Topology Aware Scheduling strategy)
答:Presto把集群资源划分成两级结构(Machine,集群);【两层结构】分配算法如下:
2.1 当分配一个Split时候,会给定Split的一个地址,这个地址代表期望的分配地址;(尽量距离数据源最近的地址)
2.2 从Machine层开始查找,首先查看Machine上已经分配的Split个数是否已满,若未满则分配该机器;
2.3 若Machine资源池已满,则到集群级别找一台机器,这台机器的资源池使用量小于50%,则分配这台机器。否则分配失败;
相关参考:
- CentOS7环境下部署PrestoSQL-345版本三节点集群详细过程
- PrestoSQL-345集群连接MySQL5.7
- PrestoSQL-345集群连接Hive3.1.0
- Trino(Presto345) on Hive知识总结及TPC-DS测试
- PrestoSQL-345集群连接Kafka2.2.1
- PrestoSQL-345集群连接Redis5.0.5
- PrestoSQL-345集群连接Phoenix5.0.0-HBase2.0.0-未成功
- PrestoSQL-345集群连接Elasticsearch7.3.2
- PrestoSQL-345可视化Client yanagishima22.0部署
- PrestoSQL-345集群连接TPC-DS
Trino总结的更多相关文章
- windows(wsl)下的trino编译和升级注意事项
最近在进行旧版本的prestosql和prestodb升级相关的操作,尝试自己编译了一下,这里记录一下过程和遇到问题的处理. 因为Trino不支持windows下的编译,如果使用windows最方便的 ...
- Trino Worker 规避 OOM 思路
背景 Trino 集群如果不做任何配置优化,按照默认配置上线,Master 和 Worker 节点都很容易发生 OOM.本文从 Trino 内存设计出发, 分析 Trino 内存管理机制,到限制与优化 ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- Pulsar云原生分布式消息和流平台v2.8.0
Pulsar云原生分布式消息和流平台 **本人博客网站 **IT小神 www.itxiaoshen.com Pulsar官方网站 Apache Pulsar是一个云原生的分布式消息和流媒体平台,最初创 ...
- Java 框架、库和软件的精选列表(awesome java)
原创翻译,原始链接 本文为awesome系列中的awesome java Awesome Java Java 框架.库和软件的精选列表 项目 Bean映射 简化 bean 映射的框架 dOOv - 为 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- Thoughtworks Technology Radar #26 技术雷达26期
Thoughtworks Technology Radar #26 Techniques Adopt Four key metrics Google Cloud's DevOps Research a ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
随机推荐
- 牛客挑战赛46 C
题目链接: 排列 考虑\(dp\),我们思考如何设计状态 将第i个数插入i-1个数中,我们考虑会新增多少个超级逆序对 假设将\(i\)插入后\(i\)的位置为\(l\),\(i-1\)的原来的位置为\ ...
- Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
注意spark的Scala版本和java版本 修改后为官方指定的版本正常运行 Error:scalac: Error: object FloatRef does not have a member c ...
- 精尽Spring MVC源码分析 - HandlerAdapter 组件(三)之 HandlerMethodArgumentResolver
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- Liunx运维(五)-信息显示与搜索文件命令
文档目录: 一.uname:显示系统信息 二.hostname:显示或设置系统的主机名 三.dmesg:系统启动异常诊断 四.stat:显示文件或文件系统状态 五.du:统计磁盘空间使用情况 六.da ...
- Kubernetes K8S之Helm部署、使用与示例
Kubernetes K8S之Helm部署.使用.常见操作与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2 ...
- centos8中的MySQL卸载和安装
centos8中的MySQL卸载和安装 前言 前几天在自己的服务器上安装了一个NDB集群[而且还没有成功] 放弃治疗后用一台没有mysql的服务器实现了单机版本的集群. 本来以为这事到这就结束了,结果 ...
- kafka rebalance解决方案 -incremental cooperative协议和static membership功能
apache kafka的重平衡(rebalance),一直以来都为人诟病.因为重平衡过程会触发stop-the-world(STW),此时对应topic的资源都会处于不可用的状态.小规模的集群还好, ...
- Python将word文档转换成PDF文件
如题. 代码: ''' #將word文档转换为pdf文件 #用到的库是pywin32 #思路上是调用了windows和office功能 ''' #导入所需库 from win32com.client ...
- CentOS8 部署SqlServer
官方文档https://docs.microsoft.com/zh-cn/sql/linux/quickstart-install-connect-red-hat?view=sql-server-li ...
- Core3.0读取appsetting.json中的配置参数
前言 方法很多,下面的例子也是从百度上搜索到的,原文链接已经找不到了. 方法1 1.添加NovelSetting节点,写入相关的配置信息 2.创建类,字段与上面的配置一致 3.StartUp.cs中获 ...