Hadoop完全分布式模式安装部署
在Linux上搭建Hadoop系列:1.Hadoop环境搭建流程图2.搭建Hadoop单机模式3.搭建Hadoop伪分布式模式4.搭建Hadoop完全分布式模式
注:此教程皆是以范例讲述的,当然你可以按照教程搭建一个与教程一样的Hadoop环境,如果你想搭建一个与本教程有一些差异的Hadoop环境,这时请注意配置文件的参数可能不一样以及文件路径不一样。
目录
1.在完全分布式模式下使用wordcount示例程序完成单词统计
2.在完全分布式模式下使用wordmean示例程序计算文件中单词的平均长度
1.Hadoop集群规划与部署
一个完全分布式模式Hadoop集群至少由三台机器构成,此处搭建一个三台机器构成的小集群。
| 节点角色 | 虚拟机名 | 机器IP | 主机名 | 运行进程 |
|---|---|---|---|---|
| 主节点 | master | 192.168.232.200 | node |
NameNode ResourceManager SecondaryNameNode |
| 从节点 | slave1 | 192.168.232.201 | node1 |
DataNode NodeManager |
| 从节点 | slave2 | 192.168.232.202 | node2 |
DataNode NodeManager |
(1)准备3台虚拟机
3台虚拟机可以是已部署单机模式Hadoop,已部署伪分布模式Hadoop,当然也可以是从零开始的基础环境。
克隆出三台虚拟机
注:为方便管理可以建一个文件夹(full-Distributed),将三台虚拟机放入其中。
(2)分别映射好三台虚拟机的IP与主机名
//1.修改IP避免冲突
vi /etc/sysconfig/network-scripts/ifcfg-ens33 //编辑网络配置
systemctl restart network //重启网络服务此处为方便记忆,建议master节点IP尾数用200,slave1用201,slave2用202.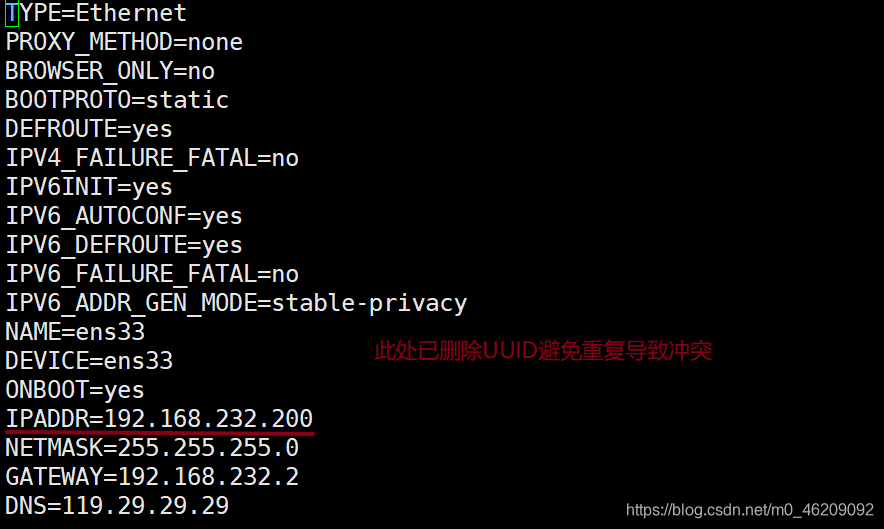
//2.修改主机名
hostname //查看主机名
hostnamectl set-hostname node //将主机名改为node
hostnamectl set-hostname node1 //将主机名改为node1
hostnamectl set-hostname node2 //将主机名改为node2master用node,slave1用node1,slave2用node2.
//3.映射IP与主机名
vi /etc/hosts
(3)设置三台机器时钟同步
完全分布式模式由多台主机组成,如果主机间时间差异较大,运行Hadoop的时候会出现问题,因此需要对每个节点配置时钟同步。
采用NTP服务通过获取网络时间使集群内不同主机的时间保持一致
此处选取阿里云的时间服务器aliyun.com
//1.安装NTP服务
yum install ntp
//2.手动同步时间
ntpdate -u ntp1.aliyun.com
//3.查看时间
date(4)设置三台机器两两之间SSH密码登录
在完全分布式模式下,集群内任意一台主机可免密登录集群内所有主机,实现两两免密登录。
若是以伪分布模式为基础的机器则需要先删除node,node1,node2主机上原有的.ssh目录
然后分别在node,node1,node2主机上生成公钥/私钥密钥对,再将公钥发送给集群内的所有主机。
//1.在各节点上删除原有.ssh目录,然后重新生成密钥对
rm -rf /root/.ssh //删除原有.ssh目录
ssh-keygen -t rsa //生成密钥对
cd ~/.ssh //进入.ssh目录
ll //查看密钥对//2.在各节点的.ssh目录下将公钥复制到node节点
cd ~ //进入根目录
ssh-copy-id node //复制公钥到node节点
ssh-copy-id node1 //复制公钥到node1节点
ssh-copy-id node2 //复制公钥到node2节点
//3.查看node节点上的authorized_key文件
cd .ssh //进入.ssh目录
more authorized_keys//4.将node节点上的authorized_keys文件远程拷贝到node1,node2
scp authorized_keys node1:~/.ssh/authorized_keys //执行过程中输入yes与密码
scp authorized_keys node2:~/.ssh/authorized_keys //执行过程中输入yes与密码//5.验证免密登录,注意查看提示符中主机名称的变化
ssh node2 //免密登录node2节点
exit //退出远程登录
ssh node1 //免密登录node1节点
exit //退出远程登录(5)修改主节点配置文件并远程拷贝到从节点
概要:
1.在主节点上修改配置文件(以下皆以伪分布式Hadoop为基础的虚拟机作为示范)
核心配置文件
core-site.xml 修改
HDFS配置文件
hadoop-env.sh 不变
hdfs-site.xml 修改
MapReduce配置文件
mapred-env.sh 修改
mapred-site.xml 不变
Yarn配置文件
yarn-env.sh 修改
yarn-site.xml 修改
slaves 修改1.在主节点上修改配置文件
核心配置文件
core-site.xml 修改
cd /export/server/hadoop-2.7.2/etc/hadoop
vi core-site.xml
//在<configuration></configuration>中插入<property></property>中的代码。注意主机名与文件路径是否是自己的
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node:9000</value>
<description>HDFS的URI,设定namenode的主机名及端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/tmp</value>
<description>节点上本地的hadoop临时文件夹,之前一定要先建立好</description>
</property>
</configuration>HDFS配置文件
hadoop-env.sh 不变 //在伪分布式已修改过
hdfs-site.xml 修改
vi hdfs-site.xml
//在<configuration></configuration>中插入<property></property>中的代码。注意主机名与文件路径是否是自己的
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/server/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/server/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本个数,默认是3,应小于datanode机器数量</description>
</property>
</configuration>MapReduce配置文件
mapred-env.sh 修改
mapred-site.xml 不变
which java //查看java安装路径
vi mapred-env.sh
插入export JAVA_HOME=/bin以前的java安装路径

Yarn配置文件
yarn-env.sh 修改
yarn-site.xml 修改
which java //获取java安装路径
vi yarn-env.sh
插入export JAVA_HOME=/bin以前的java安装路径
vi yarn-site.xml
//在<configuration></configuration>中插入<property></property>中的代码。注意主机名是否是自己的
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node</value>
<description>指定resourcemanager所在的hostname,
即指定yarn的老大即ResourceManger的地址
</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。
指定NodeManager获取数据的方式是shuffle
需配置成mapreduce_shuffle,才可运行MapReduce程序
</description>
</property>
</configuration>slaves 修改
slaves文件给出了Hadoop集群的slave节点列表。启动Hadoop时,系统总是根据当前slaves文件中slave节点名称列表启动集群,不在列表中的Slave节点便不会被视为计算节点。
vi slaves
插入各节点名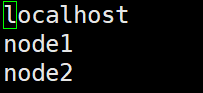
2.将主节点的配置文件分发到两个从节点
分发到node1从节点
scp -r /export/server/hadoop-2.7.2/etc/hadoop node1:/export/server/hadoop-2.7.2/etc/
分发到node2从节点
scp -r /export/server/hadoop-2.7.2/etc/hadoop node2:/export/server/hadoop-2.7.2/etc/2.格式化HDFS并启动Hadoop
(1)在主节点上格式化HDFS
hdfs namenode -format(2)在主节点上启动Hadoop
start-all.sh //启动所有进程
//或
start-dfs.sh
start-yarn.sh(3)在各节点上用JPS查看进程
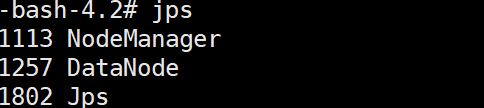
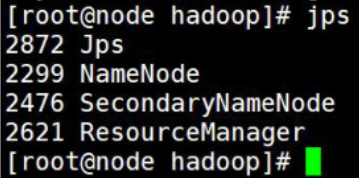

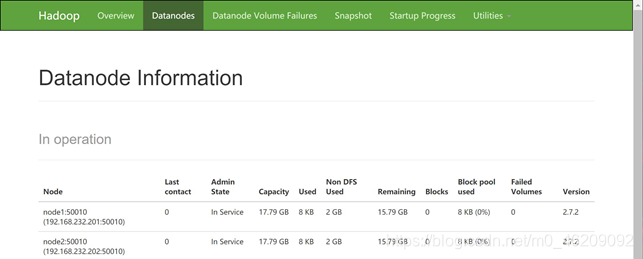
(4)web界面上查看
在浏览器输入主机的IP地址:50070
3.在完全分布式模式下运行Hadoop自带示例程序
1.在完全分布式模式下使用wordcount示例程序完成单词统计
(1)准备数据

(2)运行wordcount程序
cd /export/server/hadoop-2.7.2/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount/input/wcoutput(3)查看运行结果
hadoop fs -ls /wcoutput
hadoop fs -cat wcoutput/part*2.在完全分布式模式下使用wordmean示例程序计算文件中单词的平均长度
(1)准备数据:HDFS上的/input
(2)运行wordmean程序
hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordmean/input/wmoutput
(3)查看结果
hadoop fs -ls /wmoutput
hadoop fs -cat /wmouput/part*| 准备3台虚拟机 | 克隆 |
| 在3台机器上分别设置IP和主机名并映射关系 |
vi /etc/sysconfig/network-scripts/ifcfg-ens33 //更改IP hostnamectl set-hostname node //更改主机名 vi /etc/hosts //映射关系 |
| 设置3台机器时钟同步 |
yum install ntp //安装ntp服务 ntpdate -u ntp1.aliyun.com //手动同步时间 |
| 配置3台机器两两之间SSH免密登录 |
ssh-keygen -t rsa //获取密钥 ssh-copy-id node //复制公钥到node节点 |
| 修改主节点配置文件并远程拷贝到从节点 |
vi 各配置文件 scp -r /export/server/hadoop-2.7.2/etc/hadoop node1:/export/server/hadoop-2.7.2/etc/ |
| 格式化HDFS并启动Hadoop |
hdfs namenode -format //格式化HDFS start-all.sh //启动Hadoop所有进程 jps //查看进程 |
| 完全分布式模式运行Hadoop自带示例程序 | hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount/input/wcoutput |
Hadoop完全分布式模式安装部署的更多相关文章
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- Hadoop全分布式模式安装
一.准备 1.准备至少三台linux服务器,并安装JDK 关闭防火墙如下 systemctl stop firewalld.service systemctl disable firewalld.se ...
- Hadoop伪分布式模式安装
一.Hadoop介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上:而且 ...
- VMware workstation 下Hadoop伪分布式模式安装
详细过程: 1.VMware安装: 2.centos 6 安装 3.jdk下载安装配置 4.Hadoop 安装配置 1.VMware Workstation 安装: https://www.vmwar ...
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- hadoop记录-[Flink]Flink三种运行模式安装部署以及实现WordCount(转载)
[Flink]Flink三种运行模式安装部署以及实现WordCount 前言 Flink三种运行方式:Local.Standalone.On Yarn.成功部署后分别用Scala和Java实现word ...
- HBase入门基础教程之单机模式与伪分布式模式安装(转)
原文链接:HBase入门基础教程 在本篇文章中,我们将介绍Hbase的单机模式安装与伪分布式的安装方式,以及通过浏览器查看Hbase的用户界面.搭建HBase伪分布式环境的前提是我们已经搭建好了Had ...
- Hadoop1.X集群完全分布式模式环境部署
Hadoop1.X集群完全分布式模式环境部署 1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS,Hadoop Distri ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
随机推荐
- 处理textarea里Enter(回车换行符)
Enter换行符 如果包含有回车换行符,在字符串中表现为"\n": 会返回一条字符串: 原文章:https://blog.csdn.net/shenlf_bk/article/de ...
- python100实例
实例001:数字组合 题目 有四个数字:1.2.3.4,能组成多少个互不相同且无重复数字的三位数?各是多少? 程序分析 遍历全部可能,把有重复的剃掉. total=0 for i in range(1 ...
- 如何制作一本《现代Javascript教程》EPUB电子书
制作一本<现代Javascript教程>电子书学习使用 计划学习JavaScript的同学可以看过来,今天就推荐个学习JavaScript的免费教程. 教程文档来源于 https://zh ...
- 重拾python所要知道的一些主干知识点
前言:因为有一段时间没有用python了,最近需要用到,只能回头过去看B站视频补一补,因为语言都是相通的,而且一些细节都可以去查表解决,所以呢,我们只需要知道一些python与其他语言的不同和常见的优 ...
- Mybatis的缓存——一级缓存和源码分析
目录 什么是缓存? 一级缓存 测试一. 测试二. 总结: 一级缓存源码分析: 1. 一级缓存到底是什么? 得出结论: 2. 一级缓存什么时候被创建? 3. 一级缓存的执行流程 结论: 一级缓存源码分析 ...
- 3.4 spring5源码系列--循环依赖的设计思想
前面已经写了关于三篇循环依赖的文章, 这是一个总结篇 第一篇: 3.1 spring5源码系列--循环依赖 之 手写代码模拟spring循环依赖 第二篇: 3.2spring源码系列----循环依赖源 ...
- prometheus函数介绍
一 函数介绍 gauge类型的数据 属于随机变化数值,并不像counter那样 是 持续增长 1 increase() increase 函数 在promethes中,是⽤来 针对Counter 这 ...
- switch,case语句易误区
switch case 语句语法格式如下: switch(expression){ case value : //语句 break; //可选 case value : //语句 break; //可 ...
- 服务器虚拟化 - PVE
服务器虚拟化 - Hypervisor 服务器虚拟化软件,也叫 Hypervisor--虚拟机管理程序,有时也称做 Virtual Machine Monitor(VMM),它可以在宿主机上创建并管理 ...
- 01Java环境安装监测
下载安装JDK JDK:Java开发套件 JDK下载 监测JDK安装是否成功 运行Java命令 运行Javac命令