http请求工作流程
一、HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示
二、HTTP请求消息Request
客户端发送一个HTTP请求到服务器,其请求消息,由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,格式如图所示:
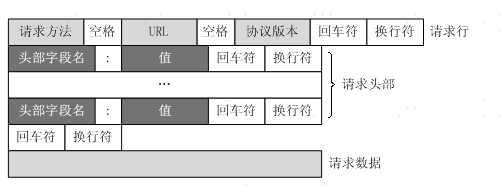
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本
Get请求例子,使用Charles抓取的request: GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
第一部分:请求行,用来说明请求类型,要访问的资源以及所使用的HTTP版本.
GET说明请求类型为GET,[/562f25980001b1b106000338.jpg]为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。
第二部分:请求头部,紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息
从第二行起为请求头部,HOST将指出请求的目的地.User-Agent,服务器端和客户端脚本都能访问它,它是浏览器类型检测逻辑的重要基础.该信息由你的浏览器来定义,并且在每个请求中自动发送等等
第三部分:空行,请求头部后面的空行是必须的,即使第四部分的请求数据为空,也必须有空行。
第四部分:请求数据也叫主体,可以添加任意的其他数据。这个例子的请求数据为空。
POST请求例子,使用Charles抓取的request: POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive name=Professional%20Ajax&publisher=Wiley
第一部分:请求行,第一行指明使用的是post请求,以及http1.1版本。
第二部分:请求头部,第二行至第六行。
第三部分:空行,第七行的空行。
第四部分:请求数据,第八行
HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
PUT 从客户端向服务器传送的数据取代指定的文档的内容。
DELETE 请求服务器删除指定的页面。
CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 允许客户端查看服务器的性能。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
三、HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文,其格式如下图所示:
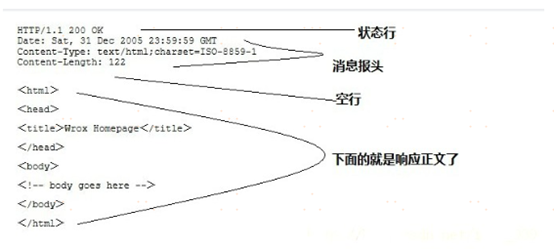
样例:
HTTP/1.1 200 OK Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8 <html>
<head></head>
<body>
<!--body goes here-->
</body>
</html>
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
常见状态码
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
http请求工作流程的更多相关文章
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- 1.说一下的 dubbo 的工作原理?注册中心挂了可以继续通信吗?说说一次 rpc 请求的流程?
作者:中华石杉 面试题 说一下的 dubbo 的工作原理?注册中心挂了可以继续通信吗?说说一次 rpc 请求的流程? 面试官心理分析 MQ.ES.Redis.Dubbo,上来先问你一些思考性的问题.原 ...
- struts2工作流程
struts2的框架结构图 工作流程 1.客户端请求一个HttpServletRequest的请求,如在浏览器中输入http://localhost: 8080/bookcode/Reg.action ...
- gitlab工作流程简介
gitlab工作流程简介 新建项目流程 创建/导入项目 可以选择导入github.bitbucket项目,也可以新建空白项目,还可以从SVN导入项目 建议选择private等级 初始化项目 1.本地克 ...
- Git 工作流程
Git 作为一个源码管理系统,不可避免涉及到多人协作. 协作必须有一个规范的工作流程,让大家有效地合作,使得项目井井有条地发展下去.”工作流程”在英语里,叫做”workflow”或者”flow”,原意 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- NSURLSession使用说明及后台工作流程分析
原文摘自http://www.cocoachina.com/industry/20131106/7304.html NSURLSession是iOS7中新的网络接口,它与咱们熟悉的NSURLConne ...
- 了解SpringMVC框架及基本工作流程
传统原生的JSP+Servlet在开发上过程上虽然简单明了,JSP页面传递数据到Servlet,Servlet整理数据(逻辑开发)或者从数据库提取数据接着再转发到JSP页面上,但是其似乎只能止步于此, ...
随机推荐
- laravel5.5 安装
环境要求 PHP >= 7.0.0 PHP OpenSSL 扩展 PHP PDO 扩展 PHP Mbstring 扩展 PHP Tokenizer 扩展 PHP XML 扩展 通过 Larave ...
- pass 出错问题
''' a = 10 b = 8 print("a>b") if a>b else pass pass 为何报错问题: 第一部分:print 第二部分:("a ...
- PHP 是什么?简介下
PHP 是服务器端脚本语言. 您应当具备的基础知识 在继续学习之前,您需要对以下知识有基本的了解: HTML CSS PHP 是什么? PHP(全称:PHP:Hypertext Preprocesso ...
- PHP asort() 函数
------------恢复内容开始------------ 实例 对关联数组按照键值进行升序排序: <?php$age=array("Peter"=>"35 ...
- PHP ord() 函数
实例 返回 "h" 的 ASCII值: <?php高佣联盟 www.cgewang.comecho ord("h")."<br>&q ...
- 笨办法学python3练习代码ex21.py
def add(a, b): print(f"ADDING {a} + {b}") return (a + b) def subtract(a, b): #subtract :减去 ...
- 基于asp.net core 从零搭建自己的业务框架(一)
前言 asp.net core版本选择2.2,只是因为个人习惯了vs2017,代码以及设计皆可移植到vs2019,用asp.net core 3.0以及以上运行起来 项目类似选择web api,基础设 ...
- requests入门实践01_下载2560*1080的电脑壁纸
新版本移步:https://www.cnblogs.com/zy7y/p/13376228.html 附上代码 # !usr/bin/env python # -*- coding:utf-8 -*- ...
- Chrome简洁高效管理下载项
每次要查看下载记录时,Chrome新建下载标签页的速度能让我抓狂 之前用的 Chrono 界面太过传统,而且还不能点击打开.所以一直在寻找好用的下载管理插件,经过多次在拓展商城搜索比对,找到了这款拓展 ...
- 利用Jsoup爬取新冠疫情数据并存至数据库
需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar) 链接:https://pan.baidu.com/s/1VlylWmlhjd8K ...