给jdk写注释系列之jdk1.6容器(1)-ArrayList源码解析
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
}
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll( int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
E get( int index);
E set( int index, E element);
void add( int index, E element);
E remove( int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator( int index);
List<E> subList( int fromIndex, int toIndex);
}
private transient Object[] elementData;
private int size;
可以看到用一个Object数组来存储数据,用一个int值来计数,记录当前容器的数据大小。
/**
* Save the state of the <tt>ArrayList</tt> instance to a stream (that
* is, serialize it).
*
* @serialData The length of the array backing the <tt>ArrayList </tt>
* instance is emitted (int), followed by all of its elements
* (each an <tt>Object</tt> ) in the proper order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount ;
s.defaultWriteObject(); // Write out array length
s.writeInt( elementData.length ); // Write out all elements in the proper order.
for (int i=0; i<size; i++)
s.writeObject( elementData[i]); if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
} } /**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject(); // Read in array length and allocate array
int arrayLength = s.readInt();
Object[] a = elementData = new Object[arrayLength]; // Read in all elements in the proper order.
for (int i=0; i<size; i++)
a[i] = s.readObject();
}
英语注释很详细,也很容易读懂,就不进行翻译了。那么想一下为什么要这样设计呢,岂不是很麻烦。下面简单进行解释下:
/**
* 构造一个具有指定容量的list
*/
public ArrayList( int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException( "Illegal Capacity: " +
initialCapacity);
this.elementData = new Object[initialCapacity];
} /**
* 构造一个初始容量为10的list
*/
public ArrayList() {
this(10);
} /**
* 构造一个包含指定元素的list,这些元素的是按照Collection的迭代器返回的顺序排列的
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData .length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData .getClass() != Object[].class)
elementData = Arrays.copyOf( elementData, size , Object[].class);
}
/**
* 添加一个元素
*/
public boolean add(E e) {
// 进行扩容检查
ensureCapacity( size + 1); // Increments modCount
// 将e增加至list的数据尾部,容量+1
elementData[size ++] = e;
return true;
} /**
* 在指定位置添加一个元素
*/
public void add(int index, E element) {
// 判断索引是否越界,这里会抛出多么熟悉的异常。。。
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: " +size); // 进行扩容检查
ensureCapacity( size+1); // Increments modCount
// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置
System. arraycopy(elementData, index, elementData, index + 1,
size - index);
// 将指定的index位置赋值为element
elementData[index] = element;
// list容量+1
size++;
}
/**
* 增加一个集合元素
*/
public boolean addAll(Collection<? extends E> c) {
//将c转换为数组
Object[] a = c.toArray();
int numNew = a.length ;
//扩容检查
ensureCapacity( size + numNew); // Increments modCount
//将c添加至list的数据尾部
System. arraycopy(a, 0, elementData, size, numNew);
//更新当前容器大小
size += numNew;
return numNew != 0;
}
/**
* 在指定位置,增加一个集合元素
*/
public boolean addAll(int index, Collection<? extends E> c) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: " + index + ", Size: " + size); Object[] a = c.toArray();
int numNew = a.length ;
ensureCapacity( size + numNew); // Increments modCount // 计算需要移动的长度(index之后的元素个数)
int numMoved = size - index;
// 数组复制,空出第index到index+numNum的位置,即将数组index后的元素向右移动numNum个位置
if (numMoved > 0)
System. arraycopy(elementData, index, elementData, index + numNew,
numMoved); // 将要插入的集合元素复制到数组空出的位置中
System. arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
} /**
* 数组容量检查,不够时则进行扩容
*/
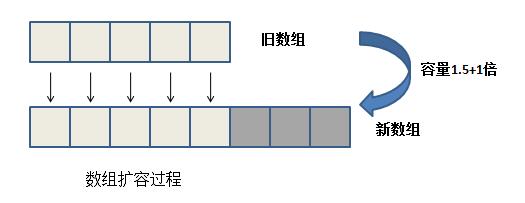
public void ensureCapacity( int minCapacity) {
modCount++;
// 当前数组的长度
int oldCapacity = elementData .length;
// 最小需要的容量大于当前数组的长度则进行扩容
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
// 新扩容的数组长度为旧容量的1.5倍+1
int newCapacity = (oldCapacity * 3)/2 + 1;
// 如果新扩容的数组长度还是比最小需要的容量小,则以最小需要的容量为长度进行扩容
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
// 进行数据拷贝,Arrays.copyOf底层实现是System.arrayCopy()
elementData = Arrays.copyOf( elementData, newCapacity);
}
}
/**
* 根据索引位置删除元素
*/
public E remove( int index) {
// 数组越界检查
RangeCheck(index); modCount++;
// 取出要删除位置的元素,供返回使用
E oldValue = (E) elementData[index];
// 计算数组要复制的数量
int numMoved = size - index - 1;
// 数组复制,就是将index之后的元素往前移动一个位置
if (numMoved > 0)
System. arraycopy(elementData, index+1, elementData, index,
numMoved);
// 将数组最后一个元素置空(因为删除了一个元素,然后index后面的元素都向前移动了,所以最后一个就没用了),好让gc尽快回收
// 不要忘了size减一
elementData[--size ] = null; // Let gc do its work return oldValue;
} /**
* 根据元素内容删除,只删除匹配的第一个
*/
public boolean remove(Object o) {
// 对要删除的元素进行null判断
// 对数据元素进行遍历查找,知道找到第一个要删除的元素,删除后进行返回,如果要删除的元素正好是最后一个那就惨了,时间复杂度可达O(n) 。。。
if (o == null) {
for (int index = 0; index < size; index++)
// null值要用==比较
if (elementData [index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
// 非null当然是用equals比较了
if (o.equals(elementData [index])) {
fastRemove(index);
return true;
}
}
return false;
} /*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
// 原理和之前的add一样,还是进行数组复制,将index后的元素向前移动一个位置,不细解释了,
int numMoved = size - index - 1;
if (numMoved > 0)
System. arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size ] = null; // Let gc do its work
} /**
* 数组越界检查
*/
private void RangeCheck(int index) {
if (index >= size )
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: " +size);
}
PS:看到了这个方法,便可jdk源码有些地方写的也不是那么精巧,比如这里remove时将数组越界检查封装成了一个单独方法,可是往前翻一下add方法中的数组越界就没有进行封装,需要检查的时候都是写一遍一样的代码,why啊。。。

/**
* 将底层数组的容量调整为当前实际元素的大小,来释放空间。
*/
public void trimToSize() {
modCount++;
// 当前数组的容量
int oldCapacity = elementData .length;
// 如果当前实际元素大小 小于 当前数组的容量,则进行缩容
if (size < oldCapacity) {
elementData = Arrays.copyOf( elementData, size );
}
/**
* 将指定位置的元素更新为新元素
*/
public E set( int index, E element) {
// 数组越界检查
RangeCheck(index); // 取出要更新位置的元素,供返回使用
E oldValue = (E) elementData[index];
// 将该位置赋值为行的元素
elementData[index] = element;
// 返回旧元素
return oldValue;
}
/**
* 查找指定位置上的元素
*/
public E get( int index) {
RangeCheck(index); return (E) elementData [index];
}
由于ArrayList使用数组实现,更新和查找直接基于下标操作,变得十分简单。
/**
* Returns <tt>true</tt> if this list contains the specified element.
* More formally, returns <tt>true</tt> if and only if this list contains
* at least one element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>.
*
* @param o element whose presence in this list is to be tested
* @return <tt> true</tt> if this list contains the specified element
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
} /**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData [i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData [i]))
return i;
}
return -1;
} /**
* Returns the index of the last occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the highest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData [i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData [i]))
return i;
}
return -1;
}
/**
* Returns the number of elements in this list.
*
* @return the number of elements in this list
*/
public int size() {
return size ;
} /**
* Returns <tt>true</tt> if this list contains no elements.
*
* @return <tt> true</tt> if this list contains no elements
*/
public boolean isEmpty() {
return size == 0;
}
给jdk写注释系列之jdk1.6容器(1)-ArrayList源码解析的更多相关文章
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
- 给jdk写注释系列之jdk1.6容器(7)-TreeMap源码解析
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解. 要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链 ...
- 给jdk写注释系列之jdk1.6容器(6)-HashSet源码解析&Map迭代器
今天的主角是HashSet,Set是什么东东,当然也是一种java容器了. 现在再看到Hash心底里有没有会心一笑呢,这里不再赘述hash的概念原理等一大堆东西了(不懂得需要先回去看下Has ...
- 给jdk写注释系列之jdk1.6容器(5)-LinkedHashMap源码解析
前面分析了HashMap的实现,我们知道其底层数据存储是一个hash表(数组+单向链表).接下来我们看一下另一个LinkedHashMap,它是HashMap的一个子类,他在HashMap的基础上维持 ...
- 给jdk写注释系列之jdk1.6容器(12)-PriorityQueue源码解析
PriorityQueue是一种什么样的容器呢?看过前面的几个jdk容器分析的话,看到Queue这个单词你一定会,哦~这是一种队列.是的,PriorityQueue是一种队列,但是它又是一种什么样的队 ...
- 给jdk写注释系列之jdk1.6容器(2)-LinkedList源码解析
LinkedList是基于链表结构的一种List,在分析LinkedList源码前有必要对链表结构进行说明. 1.链表的概念 链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链 ...
- 给jdk写注释系列之jdk1.6容器(13)-总结篇之Java集合与数据结构
是的,这篇blogs是一个总结篇,最开始的时候我提到过,对于java容器或集合的学习也可以看做是对数据结构的学习与应用.在前面我们分析了很多的java容器,也接触了好多种常用的数据结构,今天 ...
- 给jdk写注释系列之jdk1.6容器(11)-Queue之ArrayDeque源码解析
前面讲了Stack是一种先进后出的数据结构:栈,那么对应的Queue是一种先进先出(First In First Out)的数据结构:队列. 对比一下Stack,Queue是一种先进先出的容 ...
- 给jdk写注释系列之jdk1.6容器(10)-Stack&Vector源码解析
前面我们已经接触过几种数据结构了,有数组.链表.Hash表.红黑树(二叉查询树),今天再来看另外一种数据结构:栈. 什么是栈呢,我就不找它具体的定义了,直接举个例子,栈就相当于一个很窄的木桶 ...
随机推荐
- labview 变体数据类型
变体数据类型是LabVIEW中多种数据类型的容器.将其它数据转换为变体时,变体将存储数据和数据的原始类型,保证日后可将变体数据反向转换. 例如,如将字符串数据转换为变体,变体将存储字符串的文本,以及说 ...
- [iOS UI进阶 - 3.2] 手势识别器UIGestureRecognizer
A.系统提供的手势识别器 1.敲击手势 UITapGestureRecognizer numberOfTapsRequired: 敲击次数 numberOfTouchesRequired: 同时敲 ...
- Contest 7.21(贪心专练)
这一次都主要是贪心练习 练习地址http://acm.hust.edu.cn/vjudge/contest/view.action?cid=26733#overview Problem APOJ 13 ...
- C#一些知识点:委托和事件的区别
在C#中,委托和事件是比较容易混淆的两个知识点,本篇博客就记录一下委托和事件之间的区别. 定义上的区别 委托:委托实际上是一个类,用来表示一个函数,可以理解为C++中的函数指针. 事件:事件是一个修饰 ...
- Winform开发框架之通用自动更新模块(转)
在网络化的环境中,特别是基于互联网发布的Winform程序,程序的自动更新功能是比较重要的操作,这样可以避免挨个给使用者打电话.发信息通知或者发送软件等,要求其对应用程序进行升级.实现程序的自动更新, ...
- cocos2d-x 让精灵按照自己设定的运动轨迹行动
转自:http://blog.csdn.net/ufolr/article/details/7447773 在cocos2d中,系统提供了CCMove.CCJump.CCBezier(贝塞尔曲线)等让 ...
- Spring-AOP和AspectJ的区别和联系
AOP是Spring框架的重要组成部分.目前我所接触的AOP实现框架有Spring AOP还有就是AspectJ(还有另外几种我没有接触过).我们先来说说他们的区别: AspectJ是一个比较牛逼的A ...
- RT-Thread学习笔记(2)
这段时间稍微折腾了一下stm32,稍微知道了一点stm32程序的编写方法,所以再次拿起了rtt,因为这个东西确实很强大. 随手记录一下rtt的一些知识: 1.关于finsh 这是一个命令行系统,很好玩 ...
- Codeforces Testing Round #12 C. Subsequences 树状数组维护DP
C. Subsequences Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/597/probl ...
- makefile中的patsubst
函数名称:加前缀函数—addprefix. 函数功能:为“NAMES…”中的每个文件名称加入前缀“PREFIX”.參数“NAMES…”是空格切割的文件名称序列,将“SUFFIX”加入到此序列的每个文件 ...