【Spark学习】Apache Spark项目简介
引言:本文直接翻译自Spark官方网站首页
![]() Lightning-fast cluster computing
Lightning-fast cluster computing
从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算
Apache Spark™ 是一个应用于大规模数据处理的快速且通用的引擎。
速度
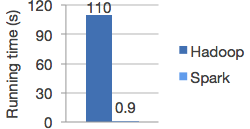
Spark在内存中运行程序的速度比Hadoop MapReduce要快100多倍,在磁盘上则要快10多倍。它使用先进的DAG执行引擎来支持循环数据流和内存计算。
易用
用户可以使用Java、Scala或Python语言来快速编写应用程序。Spark提供了80多种高级运算符来帮助用户轻松创建并行应用。而且,用户还可以借助Spark-shell(Scala和Python语言有各自的Spark-shell)来交互地使用Spark。
# Word count in Spark's Python API
file = spark.textFile("hdfs://...")
file.flatMap(lambda line: line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
通用性
Spark兼备SQL、流处理以及复杂分析等功能。它为多个高级工具提供驱动,包括数据库框架Spark SQL、机器学习框架MLlib、图运算框架GraphX,以及流处理框架Spark Streaming。用户可以在相同的应用程序中无缝兼备这几种框架。

兼容
Spark可以运行在Hadoop、Mesos、Standalone 或者 Cloud平台之上。它可以访问各种数据源,包括HDFS、HBase、S3,以及Cassandra。用户可以分别使用Standalone集群模式,EC2,Hadoop YARN或者Apache Mesos平台轻松运行Spark。Spark可以从HDFS、HBase、Cassandra,以及其他任何Hadoop数据源中读取数据。

【Spark学习】Apache Spark项目简介的更多相关文章
- Spark学习之Spark Streaming(9)
Spark学习之Spark Streaming(9) 1. Spark Streaming允许用户使用一套和批处理非常接近的API来编写流式计算应用,这就可以大量重用批处理应用的技术甚至代码. 2. ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- Spark学习之Spark SQL
一.简介 Spark SQL 提供了以下三大功能. (1) Spark SQL 可以从各种结构化数据源(例如 JSON.Hive.Parquet 等)中读取数据. (2) Spark SQL 不仅支持 ...
- Spark学习一:Spark概述
1.1 什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. 一站式管理大数据的所有场景(批处理,流处理,sql) spark不涉及到数据的存储,只 ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- Spark学习之Spark Streaming
一.简介 许多应用需要即时处理收到的数据,例如用来实时追踪页面访问统计的应用.训练机器学习模型的应用,还有自动检测异常的应用.Spark Streaming 是 Spark 为这些应用而设计的模型.它 ...
- Spark学习(4) Spark Streaming
什么是Spark Streaming Spark Streaming类似于Apache Storm,用于流式数据的处理 Spark Streaming有高吞吐量和容错能力强等特点.Spark Stre ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习之Spark调优与调试(二)
下面来看看更复杂的情况,比如,当调度器进行流水线执行(pipelining),或把多个 RDD 合并到一个步骤中时.当RDD 不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行.上一 ...
随机推荐
- 破解之API断点法
上回给大家做的破解教程,地址是http://www.52pojie.net/thread-52719-1-1.html,用的是“调用堆栈”方法.今天给新手提供另一种方法“API函数断点”,这种方法要求 ...
- how to make form:checkboxes in JSP
retransmitTable.jsp file: <%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix=&qu ...
- Qt之自定义控件(开关按钮)Qt之模拟时钟
http://blog.csdn.net/u011012932/article/details/52164289 http://blog.csdn.net/u011012932/article/det ...
- 安装 ArcGIS Runtime SDK for Android
ArcGIS for Android 开发:Android 平台搭建 - liyong20080101的专栏 - 博客频道 - CSDN.NET http://blog.csdn.net/liyong ...
- PHP设计模式浅析
工厂模式 提到的最多, 用途也最广. 简单说就是: 定义一个用户创建对象的接口. 把创建对象的过程封装起来. 工厂类是指包含一个专门用来创建其他对象的方法的类,工厂类在多态性编程实践中是至关重要的,它 ...
- 187. Repeated DNA Sequences
题目: All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: " ...
- Python之异常篇 [待更新]
简介 当你的程序中出现某些 异常的 状况的时候,异常就发生了.例如,当你想要读某个文件的时候,而那个文件不存在.或者在程序运行的时候,你不小心把它删除了.上述这些情况可以使用异常来处理. 假如你的程序 ...
- 【转】Java多线程学习
来源:http://www.cnblogs.com/samzeng/p/3546084.html Java多线程学习总结--线程概述及创建线程的方式(1) 在Java开发中,多线程是很常用的,用得好的 ...
- Oracle命令(一):Oracle登录命令
1.运行SQLPLUS工具 C:\Users\wd-pc>sqlplus 2.直接进入SQLPLUS命令提示符 C:\Users\wd-pc>sqlplus /nolog 3.以OS身份连 ...
- 【HDOJ】4333 Revolving Digits
扩展KMP基础题目. /* 4333 */ #include <iostream> #include <sstream> #include <string> #in ...