异步网页采集利器CasperJs
在采集网页中,我们会经常遇到采集一些异步加载页面的网页,我们通常用的httpwebrequest类就采集不到了,这个时候我们通常会采用webbrowser来辅助采集,但是.net下自带的webbrowser用起来非常不爽,在获取页面是否加载完毕的时候比较麻烦一些,DocumentCompleted事件遇到Iframe重复触发,而且获取到的源码通常也不是异步加载完之后的源码,往往我们需要加上定时器去不断的检查,才能获取到我们想要的源码。当然我们可以用一些第三方的webkit内核浏览器,但是这些判断页面是不是真正的加载完成也是比较费劲,而且体积都不小。
今天就介绍一下CasperJS,CasperJS是一个开源的导航脚本处理和测试工具,基于PhantomJS 和 slimerjs(前端自动化测试工具)编写。CasperJS简化了完整的导航场景的过程定义,提供了用于完成常见任务的实用的高级函数、方法和语法。CasperJS本身的功能很强大,内置了两种引擎PhantomJS 和 slimerjs 默认使用PhantomJS,具体详细的功能,大家可以参数这些官方网站去了解,或者加入QQ群389709524一块讨论,今天的重点讨论如何快速的采集到异步加载的网页。
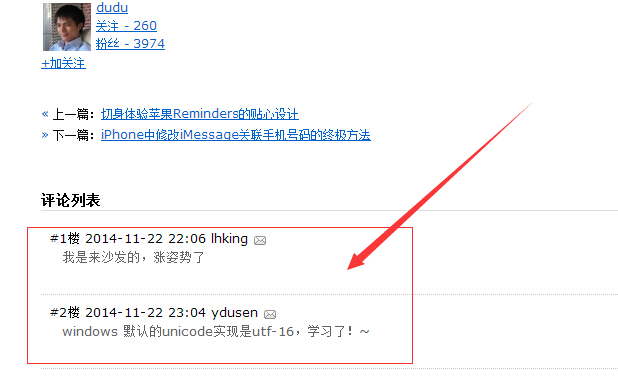
假如我们要采集dudu的这篇文章的评论 http://www.cnblogs.com/dudu/p/csharp-unicode-utf8.html,这篇文章查看源码是找不到这两条评论的,我们通过httpwebrequest也是获取不到的,这个时候我们通过casperjs就非常容易了。
caperjs代码定义如下:
var fs = require('fs');
var casper = require('casper').create({
pageSettings: {
loadImages: false,
loadPlugins: false
},
logLevel: "debug",//日志等级
verbose: true, // 记录日志到控制台
});
var url = casper.cli.raw.get('url');
//请求页面
casper.start(url, function () {
fs.write("temp.html", this.getHTML(), 'w');
});
casper.run();
结果如下:


这样几行轻松的代码就获取到了异步加载的html代码了,是不是很简单,速度也是很快!
当然在实际生产环境中这个还远远不够,我们要考虑各种网站的情景和各种网络状况,比如要考虑网络超时,一个网页一分钟加载不了我们就认为超时了,不然会一直等待,还有我们要过滤一下对于我们采集无关的请求,比较谷歌统计,百度统计,广告等,这个往往会拖慢网页的加载速度,另外页面的css样式,图片我们通常也不需要,都可以忽略,综上所述,我们的代码扩展成这样子。
var fs = require('fs');
var casper = require('casper').create({
pageSettings: {
loadImages: true,
loadPlugins: false,
userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
},
logLevel: "debug",//日志等级
verbose: true, // 记录日志到控制台
timeout: ,//60秒超时,退出
});
var url = casper.cli.raw.get('url');
//排除不相关的请求,加快页面加载进度
casper.on('resource.requested', function(requestData, request) {
if (requestData.url.indexOf('google-analytics.com') > ) {
request.abort();
}
if (requestData.url.indexOf('googlesyndication.com') > ) {
request.abort();
}
if (requestData.url.indexOf('hm.baidu.com') > ) {
request.abort();
}
if (requestData.url.indexOf('baidustatic.com') > ) {
request.abort();
}
if (requestData.url.indexOf('share.baidu.com') > ) {
request.abort();
}
if (requestData.url.indexOf('cbjs.baidu.com') > ) {
request.abort();
}
if (requestData.url.indexOf('jiathis.com') > ) {
request.abort();
}
if (requestData.url.indexOf('.cnzz.com') > ) {
request.abort();
}
if (requestData.url.indexOf('.51.la') > ) {
request.abort();
}
if (requestData.url.indexOf('.tanx.com') > ) {
request.abort();
}
//this.echo("==============>page.resource.requested"+requestData.url);
});
//超时执行的函数,记录到日志文件
casper.on('timeout', function () {
//this.echo("===>timeout"+url);
var fileName = this.evaluate(getFileName);
var nowTime = this.evaluate(CurentTime);
fs.write("log/timeout_" + fileName + ".txt", nowTime + "====>" + url + "\r\n", 'a');
});
//请求页面
casper.start(url, function () {
var status = this.status().currentHTTPStatus;
//this.capture('tt.png');
fs.write("temp.html", this.getHTML(), 'w');
});
function getFileName() {
var now = new Date();
var year = now.getFullYear(); //年
var month = now.getMonth() + ; //月
var day = now.getDate(); //日
return (year + "" + month + "" + day);
}
function CurentTime() {
var now = new Date();
var year = now.getFullYear(); //年
var month = now.getMonth() + ; //月
var day = now.getDate(); //日
var hh = now.getHours(); //时
var mm = now.getMinutes(); //分
var clock = year + "-";
if (month < )
clock += "";
clock += month + "-";
if (day < )
clock += "";
clock += day + " ";
if (hh < )
clock += "";
clock += hh + ":";
if (mm < ) clock += '';
clock += mm;
return (clock);
}
casper.run();
CasperJs的安装,可以参考官方网站的文档,或者关注下面的微信公众号 提供本文的所有工具和源码下载,本人也是最近刚接触,希望和大家一块讨论。今天写此文章还有个目的是,使用CasperJs的时候遇到一个页面个别文字出现乱码,一时找不到解决方案,欢迎知道的大侠帮忙指点下!情景如下:
比如采集这个网页 http://meiri.jguo.cn/mryr/2014/1209/59249.html 这个网站编码是gb2312 采集的时候遇到 曹叡 的 “叡 ”会出现乱码,其他的文字没事,我自己测试了下,发现如果网站是utf-8编码的,采集的时候这个字没问题,但是咱们是采集程序,不可能要求别人改编码,所以目前还没有想到解决方案,还希望知道的同学,指点一二,在此谢了!
文章出处:http://www.cnblogs.com/weiguang3100/
在线工具:http://51tools.info
.NET 开发交流 关注微信公众号
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
异步网页采集利器CasperJs的更多相关文章
- 网页采集利器 phpQuery
网页采集利器 phpQuery 2012-02-28 11:43:24| 分类: php|举报|字号 订阅 在网页采集的时候,通常都会用到正则表达式.但是有时候对于正则不太好的同学,比如我, ...
- Fiddler 网页采集抓包利器
最近这段时间,网页采集方面的工作做得比较多.用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示:基于weiphp做了一个掌上 ...
- Fiddler 网页采集抓包利器__手机app抓包
用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示: 基于weiphp做了一个掌上头条插件,也是用的网页采集技术:和一个创业 ...
- Hawk 3. 网页采集器
1.基本入门 1. 原理(建议阅读) 网页采集器的功能是获取网页中的数据(废话).通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍,在页面中只有一个).因此 ...
- 网页采集器-UA伪装
网页采集器-UA伪装 UA伪装 请求载体身份标识的伪装: User-Agent: 请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器,则该请求的User-Agent为浏览器的身份标识,如果使用爬 ...
- 一文搞懂指标采集利器 Telegraf
作者| 姜闻名 来源|尔达 Erda 公众号 导读:为了让大家更好的了解 MSP 中 APM 系统的设计实现,我们决定编写一个<详聊微服务观测>系列文章,深入 APM 系统的产品.架构 ...
- 史林枫:开源HtmlAgilityPack公共小类库封装 - 网页采集(爬虫)辅助解析利器【附源码+可视化工具推荐】
做开发的,可能都做过信息采集相关的程序,史林枫也经常做一些数据采集或某些网站的业务办理自动化操作软件. 获取目标网页的信息很简单,使用网络编程,利用HttpWebResponse.HttpWebReq ...
- 简单的网页采集程序(ASP.NET MVC4)
因为懒人太多,造成现在网页数据采集非常的流行,我也来写个简单的记录一下. 之前写了MVC的基本框架的搭建随笔,后面因为公司太忙,个人感情问题:(,导致不想写了,就写了两篇给删除了,现在就搁浅了, 本人 ...
- PHP采集利器:Snoopy 试用心得
Snoopy.class.php下载 Snoopy是一个php类,用来模拟浏览器的功能,可以获取网页内容,发送表单.Snoopy正确运行需要你的服务器的PHP版本在4以上,并且支持PCRE(Perl ...
随机推荐
- hdu 3853 LOOPS 概率DP
简单的概率DP入门题 代码如下: #include<iostream> #include<stdio.h> #include<algorithm> #include ...
- a标签的link、visited、hover、active的顺序
a标签的link.visited.hover.active是有一定顺序的,以下是我一直在用的一个顺序,能正确显示四个颜色,我也不知道有没有其他的顺序能正确显示,如果你没办法判断哪个是对的,那就先用这个 ...
- iOS中关于KVC与KVO知识点
iOS中关于KVC与KVO知识点 iOS中关于KVC与KVO知识点 一.简介 KVC/KVO是观察者模式的一种实现,在Cocoa中是以被万物之源NSObject类实现的NSKeyValueCodin ...
- [Unity菜鸟] 术语
HUD Mozilla Mozilla基金会,简称Mozilla(缩写MF或MoFo),是为支持和领导开源的Mozilla项目而设立的一个非营利组织. 称作Mozilla公司的子公司,雇佣了一些Mo ...
- C#连接SQLite的字符串
一.C#在不同情况下连接SQLite字符串格式 1.Basic(基本的) Data Source=filename;Version=3; 2.Using UTF16(使用UTF16编码) Data S ...
- classpath、path、JAVA_HOME的作用及JAVA环境变量配置
CLASSPATH是什么?它的作用是什么? 它是javac编译器的一个环境变量.它的作用与import.package关键字有关.当你写下improt java.util.*时,编译器面对import ...
- JavaScript DOM高级程序设计 4.2 事件类型--我要坚持到底!
对象事件 load和unload(载入页面的时候调用load,关闭页面的时候调用unload) abort和error 对于载入图像时出现错误的情况,可以使用error事件侦听器来进行说明: ADS. ...
- ogg实现oracle到sql server 2005的同步
一.源端(oracle)配置1.创建同步测试表create table gg_user.t01(name varchar(20) primary key);create table gg_user.t ...
- Android开发之全屏显示的两种方法
1.通过修改清单文件中Theme,实现全屏 <application android:name=".MyApplication" android:allowBackup=&q ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...