ArrayList、LinkedList和Vector的源码解析,带你走近List的世界
java.util.List接口是Java Collections Framework的一个重要组成部分,List接口的架构图如下:
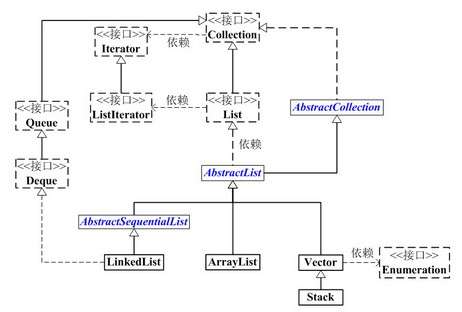
本文将通过剖析List接口的三个实现类——ArrayList、LinkedList和Vector的源码,带你走近List的世界。
ArrayList
ArrayList是List接口可调整数组大小的实现。实现所有可选列表操作,并允许放入包括空值在内的所有元素。每个ArrayList都有一个容量(capacity,区别于size),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。
底层实现
java.util.ArrayList类的继承关系如下:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
其中需要注意的是RandomAccess接口,这是一个标记接口,没有定义任何具体的内容,该接口的意义是随机存取数据。在该接口的注释中有这样一段话:
/** for (int i=0, n=list.size(); i < n; i++) { list.get(i); } runs faster than this loop: for (Iterator i=list.iterator(); i.hasNext(); ) { i.next(); } **/
这说明在数据量很大的情况下,采用迭代器遍历实现了该接口的集合,速度比较慢。
实现了RandomAccess接口的集合有:ArrayList, AttributeList, CopyOnWriteArrayList, RoleList, RoleUnresolvedList, Stack, Vector等。
ArrayList一些重要的字段如下:
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // non-private to simplify nested class access
private int size;//底层数组中实际元素个数,区别于capacity
可以看到,默认第一次插入元素时创建数组的大小为10。当向容器中添加元素时,如果容量不足,容器会自动增加50%的容量。增加容量的函数grow()源码如下:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//右移一位代表增加50%
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
值得注意的是,由于集合框架用到了编译器提供的语法糖——泛型,而Java泛型的内在实现是通过类型擦除和类型强制转换来进行的,其实存储的数据类型都是Raw Type,因此集合框架的底层数组都是Object数组,可以容纳任何对象。
数组复制
ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。在此介绍一下这两个方法。
System.arraycopy()方法是一个native方法,调用了系统的C/C++代码,在openJDK中可以看到其源码。该方法最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时使用该方法,以取得更高的效率。
Arrays.copyOf()方法有很多重载版本,但实现思路都是一样的,其泛型版本源码如下:
public static <T> T[] copyOf(T[] original, int newLength) { return (T[]) copyOf(original, newLength, original.getClass()); }其调用了copyof()方法:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
该方法实际上是在其内部创建了一个类型为newType、长度为newLength的新数组,调用System.arraycopy()方法,将原来数组中的元素复制到新的数组中。
非线程安全
ArrayList的实现是不同步的,如果多个线程同时访问ArrayList实例,并且至少有一个线程修改list的结构,那么它就必须在外部进行同步。如果没有这些对象, 这个list应该用Collections.synchronizedList()方法进行包装。 最好在list的创建时就完成包装,防止意外地非同步地访问list:
List list = Collections.synchronizedList(new ArrayList(...));除了未实现同步之外,ArrayList大致相当于Vector。
size(), isEmpty(), get(),set()方法均能在常数时间内完成,add()方法的时间开销跟插入位置有关(adding n elements requires O(n) time),addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
常用API
ArrayList常用的size(), isEmpty(), get(),set()方法实现都比较简单,读者可自行翻阅源码,它们均能在常数时间内完成,性能很高,这也是数组实现的优势所在。add()方法的时间开销跟插入位置有关(adding n elements requires O(n) time),addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
add()方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
前者是在ArrayList尾部插入一个元素,后者是在指定位置插入元素。值得注意的是,将元素的索引赋给elementData[size]时可能会出现数组越界,这里的关键就在于ensureCapacity(size+1)的调用,这个方法的作用是确保数组的容量,它的源码如下:
ensureCapacity()和ensureExplicitCapacity()方法:
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
其中有一个重要的实例变量modCount,它是在AbstractList类中定义的,在使用迭代器遍历的时候,用modCount来检查列表中的元素是否发生结构性变化(列表元素数量发生改变)了,如果modCount值改变,则代表列表中元素发生了结构性变化。
前面说过,ArrayList是非线程安全的,modCount主要在多线程环境下进行安全检查,防止一个线程正在迭代遍历,另一个线程修改了这个列表的结构。如果在使用迭代器进行遍历ArrayList的时候modCount值改变,则会报ConcurrentModificationException异常。
可以看出,直接在数组后面插入一个元素add(e)效率也很高,但是如果要按下标来插入元素,则需要调用System.arraycopy()方法来移动部分受影响的元素,这会导致性能低下,这也是使用数组实现的ArrayList的劣势。
同理,remove()方法也会改变modCount的值,效率与按下标插入元素相似,在此不加赘述。
addAll()方法
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
addAll方法也分在末尾插入和在指定位置插入,先将入参中的集合c转换成数组,根据转换后数组的程度和ArrayList的size拓展容量,之后调用System.arraycopy()方法复制元素到相应位置,调整size。根据返回的内容分析,只要集合c的大小不为空,即转换后的数组长度不为0则返回true。
容易看出,addAll()方法的时间开销是跟添加元素的个数成正比的。
trimToSize()方法
下面来看一个简单但是很有用的方法trimToSize()。
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
由于elementData的长度会被拓展,size标记的是其中包含的元素的个数。所以会出现size很小但elementData.length很大的情况,将出现空间的浪费。trimToSize()将返回一个新的数组给elementData,元素内容保持不变,length和size相同,节省空间。
在实际应用中,考虑这样一种情形,当某个应用需要,一个ArrayList扩容到比如size=10000,之后经过一系列remove操作size=15,在后面的很长一段时间内这个ArrayList的size一直保持在<100以内,那么就造成了很大的空间浪费,这时候建议显式调用一下trimToSize()方法,以优化一下内存空间。 或者在一个ArrayList中的容量已经固定,但是由于之前每次扩容都扩充50%,所以有一定的空间浪费,可以调用trimToSize()消除这些空间上的浪费。
LinkedList
LinkedList与ArrayList一样也实现了List接口,LinkedList使用双向链表实现,允许存储元素重复,链表与ArrayList的数组实现相比,在进行插入和删除操作时效率更高,但查找操作效率更低,因此在实际使用中应根据自己的程序计算需求来从二者中取舍。
与ArrayList一样,LinkedList也是非线程安全的。
底层实现
java.util.LinkedList的继承关系如下:
publicclassLinkedList<E>extendsAbstractSequentialList<E>implementsList<E>,Deque<E>,Cloneable,java.io.Serializable
LinkedList继承自抽象类AbstractSequenceList,其实AbstractSequenceList已经实现了List接口,这里标注出List只是更加清晰而已。AbstractSequenceList提供了List接口骨干性的实现以减少从而减少了实现受“连续访问”数据存储(如链表)支持的此接口所需的工作。对于随机访问数据(如数组),则应该优先使用抽象类AbstractList。
可以看到,LinkedList除了实现了List接口外,还实现了Deque接口,Deque即“Double Ended Queue”,是可以在两端插入和移动数据的线性数据结构,我们熟知的栈和队列皆可以通过实现Deque接口来实现。因此在LinkedList的实现中,除了提供了列表相关的方法如add()、remove()等,还提供了栈和队列的pop()、peek()、poll()、offer()等相关方法。这些方法中有些彼此之间只是名称的区别,内部实现完全相同,以使得这些名字在特定的上下文中显得更加的合适。
LinkedList定义的字段如下:
Size代表的是链表中存储的元素个数,而first和last分别代表链表的头节点和尾节点。 其中Node是LinkedList定义的静态内部类:
private static class Node<E> {
E item;
Node<E> next
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node是链表的节点类,其中的三个属性item、next、prev分别代表了节点的存储属性值、前继节点和后继节点。
常用API
add(e)方法
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
由上述代码可见,LinkedList在表尾添加元素,只要直接修改相关节点的前后继节点信息,而无需移动其他元素的位置,因此执行添加操作时效率很高。此外,LinkedList也是非线程安全的
remove(o)方法
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
与add方法一样,remove方法的底层实现也无需移动列表里其他元素的位置,而只需要修改被删除节点及其前后节点的prev与next属性即可。
get(index)方法
该方法可以返回指定位置的元素,下面来看一看代码
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
可以看到,LinkedList要想找到index对应位置的元素,必须要遍历整个列表,在源码实现中已经使用了二分查找(size >> 1即是除以2)的方法来进行优化,但查找元素的开销依然很大,并且与查找的位置有关。相比较ArrayList的常数级时间的消耗而言,差距很大。
clear()方法
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
该方法并不复杂,作用只是遍历列表,清空表中的元素和节点连接而已。之所以单独拿出来讲,是基于GC方面的考虑,源码注释中讲道,该方法中将所有节点之间的“连接”都断开并不是必要的,但是由于链表中的不同节点可能位于分代GC的不同年代中,如果它们互相引用会给GC带来一些额外的麻烦,因此执行此方法断开节点间的相互引用,可以帮助分代GC在这种情况下提高性能。
Vector
作为伴随JDK早期诞生的容器,Vector现在基本已经被弃用,不过依然有一些老版本的代码使用到它,因此也有必要做一些了解。Vector与ArrayList的实现基本相同,它们底层都是基于Object数组实现的,两者最大的区别在于ArrayList是非线程安全的,而Vector是线程安全的。由于Vector与ArrayList的实现非常相近,前面对于ArrayList已经进行过详细介绍了,这里很多东西就不在赘述,重点介绍Vector与ArrayList的不同之处。
容量扩展
Vector与ArrayList还有一处细节上的不同,那就是Vector进行添加操作时,如果列表容量不够需要扩容,每次增加的大小是原来的100%,而前面已经讲过,ArrayList一次只增加原有容量的50%。具体代码如下:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
线程安全
Vector类内部的大部分方法与ArrayList均相同,区别仅在于加上了synchronized关键字,比如:
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (elementCount < oldCapacity) {
elementData = Arrays.copyOf(elementData, elementCount);
}
}
这也保证了同一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问Vector比访问ArrayList要慢。
前面说过,由于性能和一些设计问题,Vector现在基本已被弃用,当涉及到线程安全时,可以如前文介绍ArrayList时所说的,对ArrayList进行简单包装,即可实现同步。
Stack类
Vector还有一个子类叫Stack,其实现了栈的基本操作。这也是在JDK早期出现的容器,很多设计不够规范,现在已经过时,使用Queue接口的相关实现可以完全取代它。
总结
- ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
- LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
- Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢,现在基本已弃用。
------------------------推荐阅读------------------------
2019年JVM最新面试题,必须收藏它
最全面的阿里多线程面试题,你能回答几个?
Java面试题:Java中的集合及其继承关系
花了近十年的时间,整理出史上最全面Java面试题
ArrayList、LinkedList和Vector的源码解析,带你走近List的世界的更多相关文章
- EventBus (三) 源码解析 带你深入理解EventBus
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/40920453,本文出自:[张鸿洋的博客] 上一篇带大家初步了解了EventBus ...
- Android EventBus源码解析 带你深入理解EventBus
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/40920453,本文出自:[张鸿洋的博客] 上一篇带大家初步了解了EventBus ...
- LinkedList 基本示例及源码解析
目录 一.JavaDoc 简介 二.LinkedList 继承接口和实现类介绍 三.LinkedList 基本方法介绍 四.LinkedList 基本方法使用 五.LinkedList 内部结构以及基 ...
- Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap
声明:以下源代码使用的都是基于JDK1.8_112版本 1. ArrayList源码解析 <1. 集合中存放的依然是对象的引用而不是对象本身,且无法放置原生数据类型,我们需要使用原生数据类型的包 ...
- Java 集合系列06之 Vector详细介绍(源码解析)和使用示例
概要 学完ArrayList和LinkedList之后,我们接着学习Vector.学习方式还是和之前一样,先对Vector有个整体认识,然后再学习它的源码:最后再通过实例来学会使用它.第1部分 Vec ...
- Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 04 LinkedList详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- 给jdk写注释系列之jdk1.6容器(10)-Stack&Vector源码解析
前面我们已经接触过几种数据结构了,有数组.链表.Hash表.红黑树(二叉查询树),今天再来看另外一种数据结构:栈. 什么是栈呢,我就不找它具体的定义了,直接举个例子,栈就相当于一个很窄的木桶 ...
随机推荐
- javascript数组在指定位置添加和删除元素
在JavaScript中,Array对象提供了一个强大的splice()方法,利用这个方法可以达到在数组的指定位置添加和删除元素的目的. 指定位置删除元素 要在指定位置删除元素,可以使用splice( ...
- Redis 数据类型及应用场景
一. redis 特点 所有数据存储在内存中,高速读写 提供丰富多样的数据类型:string. hash. set. sorted set.bitmap.hyperloglog 提供了 AOF 和 R ...
- word-break、word-wrap、white-space区别
<div id="box"> Hi , This is a incomprehensibilities long word. </br> 你好 , 这 ...
- Last 2 dimensions of the array must be square
这个报错是因为我们在求解行列式的值的时候使用了: np.linalg.det(D) 但是D必须是方阵才可以进行运算,不是方阵则会报错,我们把之前的行列式更改为方阵就不会再报错了,当然这也是numpy自 ...
- XMind 是一个全功能的思维导图和头脑风暴软件,为激发灵感和创意而生
XMind 是一个全功能的思维导图和头脑风暴软件,为激发灵感和创意而生 https://www.xmind.cn/
- 循环语句for基本概述
循环语句for基本概述 01. for循环基础语法 for 变量名 in [ 取值列表 ]do 循环体done 02. for循环基本使用示例 #取值列表有多种取值方式,可以直接读取in后面的值,默认 ...
- 并发编程~~~多线程~~~计算密集型 / IO密集型的效率, 多线程实现socket通信
一 验证计算密集型 / IO密集型的效率 IO密集型: IO密集型: 单个进程的多线程的并发效率高. 计算密集型: 计算密集型: 多进程的并发并行效率高. 二 多线程实现socket通信 服务器端: ...
- [Go] go等待读取最后一行的数据内容
这段代码是参照慕课网的视频教程,主要是f.Seek(0, os.SEEK_END)移动到末尾,但是里面有个小问题,当打开的文件被重新清空内容的清空下,就再也不能到读取数据了,比如在开启读取后 echo ...
- A Neural Influence Diffusion Model for Social Recommendation 笔记
目录 一.摘言 二.杂记 三.问题定义和一些准备工作 四.模型真思想 五.实验部分 六.参考文献 一.摘言 之前协同过滤利用user-item交互历史很好的表示了user和item.但是由于用户行为的 ...
- win10系统使用小技巧【转】
win10的很多小技巧又简单又实用,这里给大家整理了10个小技巧,一分钟学会,秒变win10高手,看不完的先收藏再看哦. 1.改美区 在设置中时间和语言中将区域和语言改为美国就可以瞬间切换Foreca ...