Win10系统下安装labelme,json文件批量转化
一、安装环境:windows10,anaconda3,python3.6
由于框架maskrcnn需要json数据集,在没安装labelme环境和跑深度学习之前,我安装的是anaconda3,其中pyhton是3.7版本的,经网上查阅资料,经过一番查找资料,发现,原来在2019年,TensorFlow还不支持python3.7,所以,迫于无奈,我只能乖乖把python的版本退回到3.6版本,具体步骤也很简单。就是打开anaconda prompt ,然后输入conda install python=3.6,然后等待提示(y/n),输入y,等待十几分钟,就会提示done,这样的话,就表示python3.7已经退回到python3.6了。(经过尝试这种方法在我这里没有行得通,可能跟网速有关,又尝试了另一种方法,有兴趣的可以尝试一下。)索性就把labelme安装到3.6中了。
二、安装过程:
1、管理员身份打开 anaconda prompt
2、输入命令:conda create --name=labelme python=3.6
3、输入命令:activate labelme
4、输入命令:pip install pyqt5,pip install pyside2(自己刚开始没有安装pyside2,运行 \anaconda安装目录\envs\labelme\Scripts\label_json_to_dataset.exe 会出现module "pyside"缺失错误)
5、输入命令:pip install labelme(由于网络原因或者库的地址,经常运行一半出现错误,不要气馁,多执行几次)
6、输入命令:labelme 即可打开labelme。如下:
安装完成后,需要使用再次启动labelme。则需要重新打开anaconda prompt,输入activate labelme,进入labelme环境。再输 入命令: labelme 即可
三、用labelme标注完图片后,会生成json文件
以小猫为例:点击保存会在自己的图片目录下生成json文件
 点点
点点
生成的json文件并不能直接用,我们需要对他进行批处理才能成为maskrcnn需要的数据集,批量转化如下:
abelme标注工具再转化.json文件有一个缺陷,一次只能转换一个.json文件,然而深度学习的项目通常需要大量的数据,那么转换.json文件就是一个比较耗时的工作;因此,对labelme做出了改进,可以实现批量转换.json文件。
在安装Anaconda中找到json_to_dataset.py文件如果未找到可以在计算机中搜索,将该文件代码修改为以下代码:
import argparse
import base64
import json
import os
import os.path as osp
import warnings import PIL.Image
import yaml from labelme import utils def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.") parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args() json_file = args.json_file alist = os.listdir(json_file) for i in range(0,len(alist)):
path = os.path.join(json_file,alist[i])
data = json.load(open(path)) out_dir = osp.basename(path).replace('.', '_')
out_dir = osp.join(osp.dirname(path), out_dir) if not osp.exists(out_dir):
os.mkdir(out_dir) if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8') img = utils.img_b64_to_arr(imageData) label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value # label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values))) lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value) captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions) PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png')) with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n') warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False) print('Saved to: %s' % out_dir) if __name__ == '__main__':
main()
操作命令如下图:
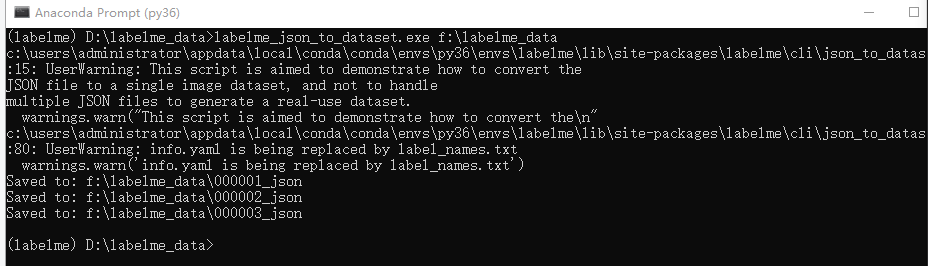
生成效果如下:每张图片生成五个文件 ,这就是我们所需要的

Win10系统下安装labelme,json文件批量转化的更多相关文章
- Win10系统下安装ubuntu16.04双系统-常见问题解答
Win10系统下安装ubuntu16.04双系统-常见问题解答 1. 安装ubuntu16.04.2系统 磁盘分区形式有两种:GPT和MBR,关系到设置引导项.在win10下压缩出500GB空间给ub ...
- Xmind pro Win10系统下安装问题解决与破解
Xmind pro Win10系统下安装问题解决与破解 1.下载安装版本 解压包含文件: xmind-8-update7-windows--安装包 和XMindCrack.jar--激活破解工具 2. ...
- Win10系统下安装Ubuntu16.04.3教程与设置
在Win10上刚刚装好Ubuntu16.04.3,装了不下于10次,期间出现很多问题,趁着还有记忆,写下这篇教程,里面还有Ubuntu系统的优化与Win10的一些设置. Part 1 制作Ubuntu ...
- Win10系统下安装编辑器之神(The God of Editor)Vim并且构建Python生态开发环境(2020年最新攻略)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_160 众神殿内,依次坐着Editplus.Atom.Sublime.Vscode.JetBrains家族.Comodo等等一众编辑 ...
- Win10系统下安装Oracle服务器和Oracle客户端
工作电脑从Win7换为Win10,在给Win10系统安装Oracle时花费了很长世间终于搞定,在此给大家分享下. 1.工作中需要连接测试环境.生产环境Oracle,所以安装了公司封装的Oracle客户 ...
- 个人亲测,在win10系统下安装多实例mysql8.0详细教程
由于公司的新项目需要导入sql脚本,需要更高版本的mysql数据库,原来的数据库我也不想删除和升级,因此安装了第二个mysql8的实例,废话不多说,步骤如下: 1.下载mysqlGPL版本,我下载的版 ...
- C语言——Win10系统下安装VC6.0教程
学习一门语言最重要的一步是搭建环境,许多人搭建在搭建环境上撞墙了,就有些放弃的心理了:俗话说,工欲善其事,必先利其器:所以接下来我们进行学习C的第一步搭建环境; 第一步:先解压我们下载好的VC6.0软 ...
- win10系统下安装64位Oracle11g+LSQL Developer
LSQL Developer作为强大的Oracle编辑工具,却只支持32bit,本文提供在安装用LSQL Developer打开64bitOracle的操作方法 工具/原料 oracle11g安装包 ...
- Win10系统下安装VC6.0教程
学习一门语言最重要的一步是搭建环境,许多人搭建在搭建环境上撞墙了,就有些放弃的心理了:俗话说,工欲善其事,必先利其器:所以接下来我们进行学习C的第一步下载编程所用的工具;当然也有其它的软件,只不过初学 ...
随机推荐
- Python自学day-5
电影推荐: 阿甘正传 辛德勒名单 肖申克的救赎 勇敢的心 角斗士 美国丽人 教父 指环王 钢琴师 血钻 战争之王 ...
- Hive 学习之路(三)—— Hive CLI和Beeline命令行的基本使用
一.Hive CLI 1.1 Help 使用hive -H或者 hive --help命令可以查看所有命令的帮助,显示如下: usage: hive -d,--define <key=value ...
- Hadoop 学习之路(五)—— Hadoop集群环境搭建
一.集群规划 这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务. ...
- excel for mac打开csv文件不分列
参考链接:http://www.1207.me/archives/247.html excel for mac在打开csv文件(逗号分隔的文本文件)的时候,不能像windows那样分列,而且全都挤在一 ...
- JS 数据类型分析及字符串的方法
1.js数据类型分析 (1)基础类型:string.number.boolean.null.undefined (2)引用类型:object-->json.array... 2.点运算 xxx ...
- C语言类型转换
int/float to string/array: C语言提供了几个标准库函数,可以将任意类型(整型.长整型.浮点型等)的数字转换为字符串,下面列举了各函数的方法及其说明. itoa():将整型值转 ...
- 【半小时大话.net依赖注入】(一)理论基础+实战控制台程序实现AutoFac注入
系列目录 第一章|理论基础+实战控制台程序实现AutoFac注入 第二章|AutoFac的常见使用套路 第三章|实战Asp.Net Framework Web程序实现AutoFac注入 第四章|实战A ...
- 在SpringBoot中使用RabbitMQ
目录 RabbitMQ简介 RabbitMQ在CentOS上安装 配置文件 实践 概述 Demo 遇到的BUG 启动异常 无法自动创建队列 RabbitMQ简介 wikipedia RabbitMQ在 ...
- 充气娃娃什么感觉?Python告诉你
上期为大家介绍了requests库的基本信息以及使用requests库爬取某东的商品页,收到了很多同学的反馈说期待猪哥的更新,猪哥感到非常开心,今天就带大家来玩一把刺激的! 一.需求背景 在实际开发过 ...
- Java中实现线程的方式
Java中实现线程的方式 Java中实现多线程的方式的方式中最核心的就是 run()方法,不管何种方式其最终都是通过run()来运行. Java刚发布时也就是JDK 1.0版本提供了两种实现方式,一个 ...