MySQL不停地自动重启怎么办
近期,测试环境出现了一次MySQL数据库不断自动重启的问题,导致的原因是强行kill -9 杀掉数据库进程导致,报错信息如下:
--24T01::.769512Z [Note] Executing 'SELECT * FROM INFORMATION_SCHEMA.TABLES;' to get a list of tables using the deprecated partition engine. You may use the startup option '--disable-partition-engine-check' to skip this check.
--24T01::.769516Z [Note] Beginning of list of non-natively partitioned tables
:: UTC - mysqld got signal ;
This could be because you hit a bug. It is also possible that this binary
or one of the libraries it was linked against is corrupt, improperly built,
or misconfigured. This error can also be caused by malfunctioning hardware.
Attempting to collect some information that could help diagnose the problem.
As this is a crash and something is definitely wrong, the information
collection process might fail.
Please help us make Percona Server better by reporting any
bugs at http://bugs.percona.com/ key_buffer_size=
read_buffer_size=
max_used_connections=
max_threads=
thread_count=
connection_count=
It is possible that mysqld could use up to
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 4478400 K bytes of memory
Hope that's ok; if not, decrease some variables in the equation. Thread pointer: 0x7f486900e000
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 7f4846172820 thread_stack 0x80000
/usr/local/mysql5./bin/mysqld(my_print_stacktrace+0x2c)[0xed481c]
/usr/local/mysql5./bin/mysqld(handle_fatal_signal+0x461)[0x7a15a1]
/lib64/libpthread.so.(+0xf7e0)[0x7f498697c7e0]
/usr/local/mysql5./bin/mysqld(_ZN12ha_federated7rnd_posEPhS0_+0x2f)[0x12bcc3f]
/usr/local/mysql5./bin/mysqld(_ZN7handler10ha_rnd_posEPhS0_+0x172)[0x804a12]
/usr/local/mysql5./bin/mysqld(_ZN14Rows_log_event24do_index_scan_and_updateEPK14Relay_log_info+0x1e3)[0xe50e23]
/usr/local/mysql5./bin/mysqld(_ZN14Rows_log_event14do_apply_eventEPK14Relay_log_info+0x716)[0xe50196]
/usr/local/mysql5./bin/mysqld(_ZN9Log_event11apply_eventEP14Relay_log_info+0x6e)[0xe48fde]
/usr/local/mysql5./bin/mysqld(_Z26apply_event_and_update_posPP9Log_eventP3THDP14Relay_log_info+0x1f0)[0xe8d6f0]
/usr/local/mysql5./bin/mysqld(handle_slave_sql+0x163d)[0xe9a0fd]
/usr/local/mysql5./bin/mysqld(pfs_spawn_thread+0x1b4)[0x1209414]
/lib64/libpthread.so.(+0x7aa1)[0x7f4986974aa1]
/lib64/libc.so.(clone+0x6d)[0x7f4984c6bc4d] Trying to get some variables.
Some pointers may be invalid and cause the dump to abort.
Query (): is an invalid pointer
Connection ID (thread ID):
Status: NOT_KILLED You may download the Percona Server operations manual by visiting
http://www.percona.com/software/percona-server/. You may find information
in the manual which will help you identify the cause of the crash.
1. 初探过程
之前出现过类似的情况时,是因为内存不足,因日志中也有对应的提示:
key_buffer_size=
read_buffer_size=
max_used_connections=
max_threads=
thread_count=
connection_count=
It is possible that mysqld could use up to
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = K bytes of memory
Hope that's ok; if not, decrease some variables in the equation.
此测试环境物理内存确实不大,且剩余内存也不足,而且是作为另一个测试环境的从库,内存分配的也少。
之前一些环境也出现过类似的情况,通过调整参数及释放内存的等处理后可以正常启动,于是尝试着关闭一些临时程序并调整MySQL上述几个参数的值,如:
[mysqld]
max_connections =
然后重新启动MySQL,结果依旧不断重启。
初步处理未果。

2. 添加innodb_force_recovery 解决不断重启
在配置文件my.cnf添加innodb_force_recovery 先处理不断重启的问题
[mysqld]
innodb_force_recovery =
添加后,再次启动MySQL,此时不再出现反复重启。
查看数据库日志,有提示 [Note] InnoDB: !!! innodb_force_recovery is set to 4 !!!如下:
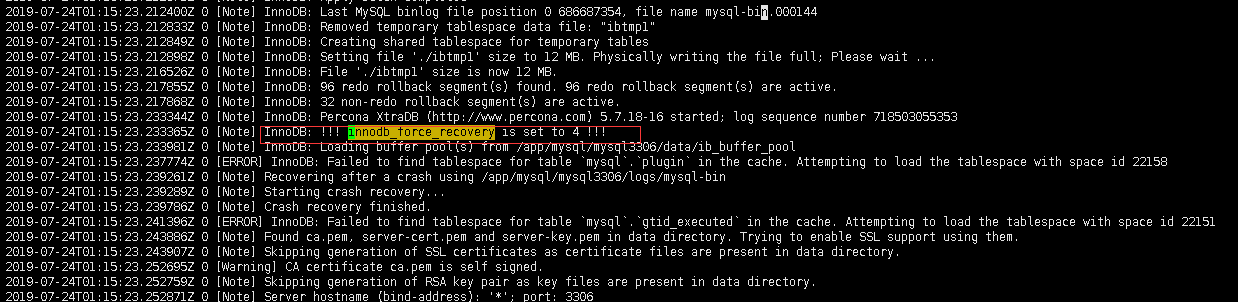
因为此时可以打开数据库,于是尝试启动从库,但是此时报错,提示Table 'mysql.slave_relay_log_info' is read only.
此时再看错误日志,如下

因此,本次启动时,innodb_force_recovery 设置为 4,在MySQL 5.6.15 以后,当 innodb_force_recovery 的值大于等于 4 的时候,InnoDB 表处于只读模式,因启动复制时需要将信息写入表中,所以此时报错。
注: 因设置为1-3 时,依旧未生效,因此我在处理时设置的为4(4 以上的值可能永久导致数据文件损坏。如果生产环境出现类似问题务必先拷贝一份测试,在测试通过后再在生产环境处理)。此时可以将所有数据dump出,之后再恢复即可。
3. innodb_force_recovery 参数
innodb_force_recovery 可以设置为 1-6,大的值包含前面所有小于它的值的影响。
(SRV_FORCE_IGNORE_CORRUPT): 忽略检查到的 corrupt 页。尽管检测到了损坏的 page 仍强制服务运行。一般设置为该值即可,然后 dump 出库表进行重建。 (SRV_FORCE_NO_BACKGROUND): 阻止主线程的运行,如主线程需要执行 full purge 操作,会导致 crash。 阻止 master thread 和任何 purge thread 运行。若 crash 发生在 purge 环节则使用该值。 (SRV_FORCE_NO_TRX_UNDO): 不执行事务回滚操作。 (SRV_FORCE_NO_IBUF_MERGE): 不执行插入缓冲的合并操作。如果可能导致崩溃则不要做这些操作。不要进行统计操作。该值可能永久损坏数据文件。若使用了该值,则将来要删除和重建辅助索引。 (SRV_FORCE_NO_UNDO_LOG_SCAN): 不查看重做日志,InnoDB 存储引擎会将未提交的事务视为已提交。此时 InnoDB 甚至把未完成的事务按照提交处理。该值可能永久性的损坏数据文件。 (SRV_FORCE_NO_LOG_REDO): 不执行前滚的操作。恢复时不做 redo log roll-forward。使数据库页处于废止状态,继而可能引起 B 树或者其他数据库结构更多的损坏。
注意:
- 为了安全,当设置参数值大于 0 后,可以对表进行 select, create, drop 操作,但 insert, update 或者 delete 这类操作是不允许的。
- MySQL 5.6.15 以后,当 innodb_force_recovery 的值大于等于 4 的时候,InnoDB 表处于只读模式。
- 在值小于等于 3 时可以通过 select 来 dump 表,可以 drop 或者 create 表。
- MySQL 5.6.27 后大于 3 的值也支持 DROP TABLE; 如果事先知道哪个表导致了崩溃则可 drop 掉这个表。
- 如果碰到了由失败的大规模导入或大量 ALTER TABLE 操作引起的 runaway rollback,则可 kill 掉 mysqld 线程然后设置 innodb_force_recovery = 3 使数据库重启后不进行 rollback。然后删除导致 runaway rollback 的表; 如果表内的数据损坏导致不能 dump 整个表内容。那么附带 order by primary_key desc 从句的查询或许能够 dump 出损坏部分之后的部分数据;
耿小厨已开通个人微信公众号,想进一步沟通或想了解其他文章的同学可以关注我

我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=33ja5r1x478ks
MySQL不停地自动重启怎么办的更多相关文章
- windows下apache及mysql定时自动重启设置
有时候觉得,服务器运行时间过长,造成服务器内存等压力过大.因此,不用重新启动服务器的情况下,完成apache和mysql的内存释放,是非常有益处的(把重启时间设置在访问量最低的).首先,apache的 ...
- supervisor开机自动启动脚本+redis+MySQL+tomcat+nginx进程自动重启配置
[root@mongodb-host supervisord]# cat mongo.conf [program:mongo]command=/usr/local/mongodb/bin/mongod ...
- Unbuntu 自动重启MySQL
上个月,通过Unbuntu搭建了WordPress,一切运行良好. UBUNTU搭建WORDPRESS-MYSQL-APACHE 但是,最近几天,不知道啥情况,MySQL偶尔会出现Stop:影响了bl ...
- node.js零基础详细教程(7.5):mongo可视化工具webstorm插件、nodejs自动重启模块Node Supervisor(修改nodejs后不用再手动命令行启动服务了)
第七章 建议学习时间4小时 课程共10章 学习方式:详细阅读,并手动实现相关代码 学习目标:此教程将教会大家 安装Node.搭建服务器.express.mysql.mongodb.编写后台业务逻辑. ...
- 【转载】mysql binlog日志自动清理及手动删除
说明:当开启mysql数据库主从时,会产生大量如mysql-bin.00000* log的文件,这会大量耗费您的硬盘空间.mysql-bin.000001mysql-bin.000002mysql-b ...
- mysql binlog日志自动清理及手动删除
说明:当开启mysql数据库主从时,会产生大量如mysql-bin.00000* log的文件,这会大量耗费您的硬盘空间.mysql-bin.000001mysql-bin.000002mysql-b ...
- CentOS 7.1系统自动重启的Bug定位过程
[问题] 有同事反应最近有多台MongoDB的服务器CentOS 7.1系统会自动重启,分析了下问题原因. [排查过程] 1. 检查系统日志/var/log/message,并没有记录异常信息,jou ...
- PHPWAMP自启异常,服务器重启后Apache等服务不会自动重启的原因分析
在使用“PHPWAMP自动任务”时,不少学生遇到如下问题: “phpwamp绿色集成环境重启动电脑(服务器)后,不会自动启动网站服务” (如果是其他环境或是自己搭建时遇到此问题,也是可以用此法解决) ...
- Docker容器可以使用容器平台管理自动重启实现自修复吗?
容器的自修复功能是经常被吹嘘的.因为容器是衣服,人躺下了,衣服也躺下了,容器平台能够马上发现人躺下了,于是可以迅速将人重新唤醒工作. 而虚拟机是房子,人躺下了,房子还站着.因而虚拟机管理平台不知道里面 ...
随机推荐
- ABP开发框架前后端开发系列---(11)菜单的动态管理
在前面随笔<ABP开发框架前后端开发系列---(9)ABP框架的权限控制管理>中介绍了基于ABP框架服务构建的Winform客户端,客户端通过Web API调用的方式进行获取数据,从而实现 ...
- What?Tomcat-竟然也算中间件?
关于 MyCat 的铺垫文章已经写了两篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! 今天是最后一次铺垫,后面就可以迎接大 Bo ...
- Spring 注解编程之模式注解
Spring 框架中有很多可用的注解,其中有一类注解称模式注解(Stereotype Annotations),包括 @Component, @Service,@Controller,@Reposit ...
- 【入门】WebRTC知识点概览 | 内有技术干货免费下载
什么是WebRTC WebRTC 即Web Real-Time Communication(网页实时通信)的缩写,是一个支持网页浏览器之间进行实时数据传输(包括音频.视频.数据流)的技术.经过多年的发 ...
- Java学习笔记——设计模式之八.外观模式
外观模式(Facade),为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用. 子系统: package cn.happy.design_patter ...
- JWT的入门案例
1.什么是JWT? JWT全称JSON Web Token.是为了在网络应用环境键传递声明而执行的一种基于JSON的开放标准. 2.JWT的使用场景? 授权:一旦用户登录,每个后续请求将包括JWT,允 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''zhaoqiuyu' (`NAME`,`PRICE`,`COUNT`) values('电脑',1999,1)' at lin
"You have an error in your SQL syntax; check the manual that corresponds to your MySQL server v ...
- 关于 https的SNI问题
遇到的问题,服务器多站点配置HTTPS 后遇到的问题,服务器报警告错误. 随后网上搜索了下 SNI的意义. 这句话很经典: SNI(Server Name Indication)是为了解决一个服务器使 ...
- NetCore 获取appsetting.json 文件中的配置
1. using Microsoft.Extensions.Configuration public class HomeController : Controller { public IConfi ...