深度学习-TensorFlow2.0笔记(一)
一、Tensor
1.1 什么是Tensor?Tensor的数据类型
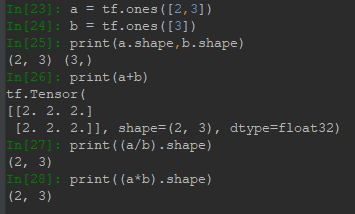
Tensor是张量的意思,在TensorFlow中张量可以是标量(scalar)、向量(vector)、矩阵(matrix)、高维度张量(rank>2),像Numpy里的数组就不属于Tensor。TensorFlow里的常用的数据类型有tf.int32、tf.float32、tf.double、tf.bool、tf.Variable。下面展示了用tf.constant创建的一些Tensor:
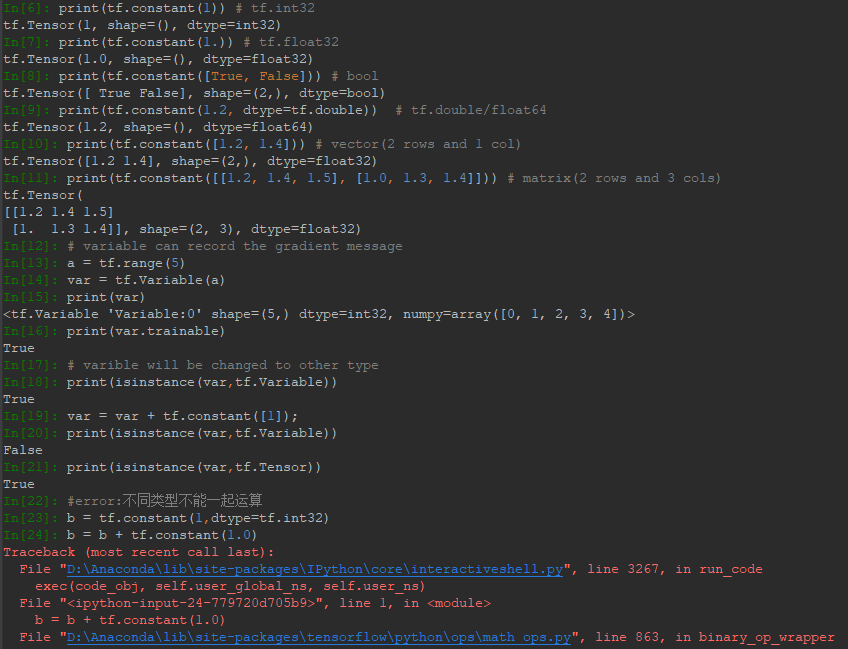
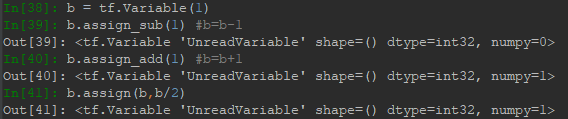
需要特别注意代码IN[18]-IN[21]行,由于TensorFlow有自动求导功能,而被求导参数类型必须为Variable类型,这样才可以被记录下梯度信息。但是Variable类型在于int、float运算过程中,假如被更新了,其类型会自动转为int、float类型,导致求导出错。第二个需要注意的是代码第34-36行,Tensor不同类型数据间不能混合运算(除了Variable),否则会出错,而在深度学习中,运算通常采用浮点形式,这种错误较少出现。为了解决Variable更新自动被转成其他类型,可以采用原地更新,即数据类型不变,如下例所示,使用assign方法可以实现任意赋值而不改变类型:
1.2 Tensor的shape
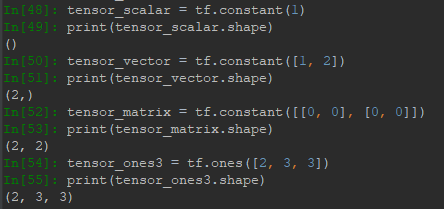
Tensor最常用的属性就是shape,即维度信息,以下代码展示了标量、向量、矩阵、高维度张量的shape信息。对于标量,其维度为0,则Python显示shape为(),对于矩阵,shape第一个元素表示行数,第二个表示列数。:
1.3 Tensor的验证
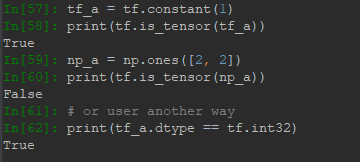
可以用tf.is_tensor()方法判断是否属于Tensor类型,也可以用dtype属性进行判断,这里拿Numpy做对比:
1.4 Tensor转换
在实际编写中,由于需要导入数据集,所以经常会用到数据转换方法,将数据集转为Tensor或Tensor转为其他形式,如Numpy:
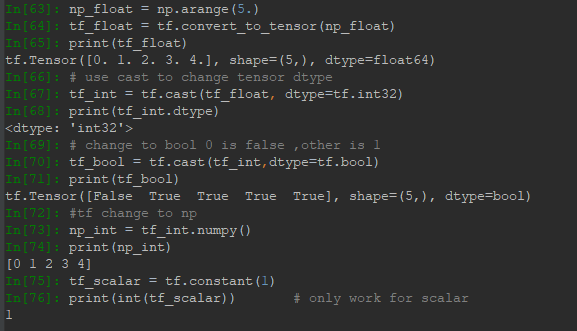
tf.cast可以用来转换Tensor的数据类型。
1.5 Tensor创建
前面使用过constant以及Variable创建过Tensorm下面介绍更实用的创建方法。
首先是间接创建,即通过Numpy,List创建然后转化为Tensor:
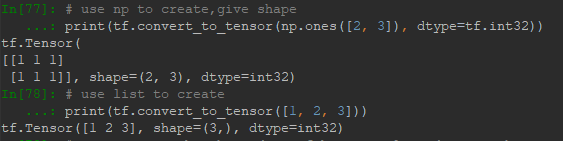
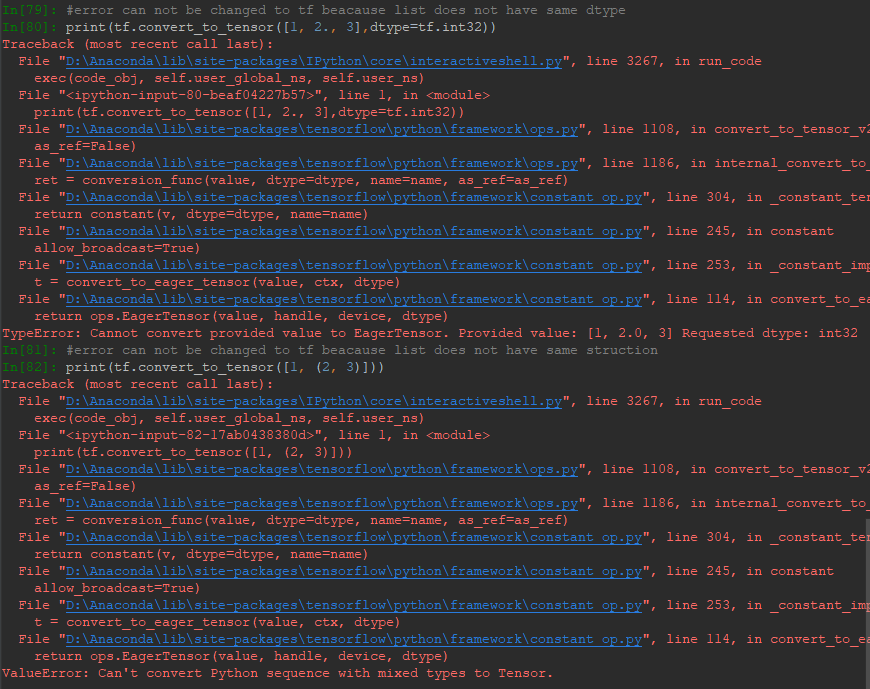
但是需要注意不能转换的情况,一种是数据类型不统一,第二种是结构不统一,如下:
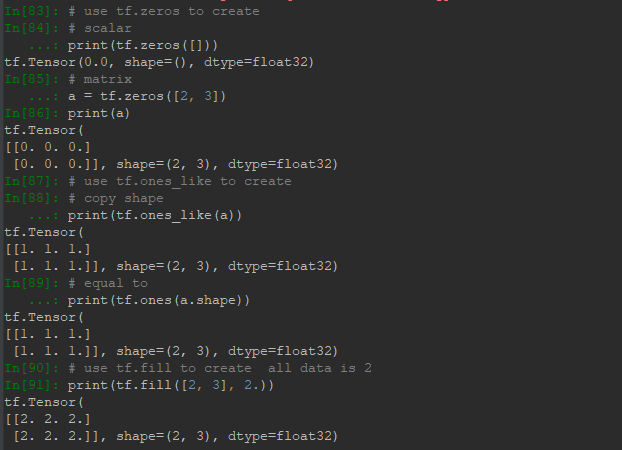
另外就是直接通过tf的方法直接创建一些矩阵、特殊分布等数据形式:
在构建网络权重的时候,常会用到正态分布或者均匀分布来初始化,其中截断型的正态分布应用更多。
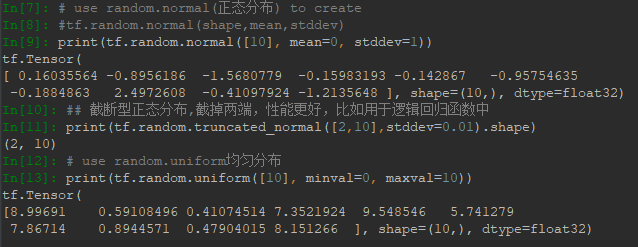
二、索引与切片
2.1 多维度索引
Tensor索引常采用列表形式,而不是像a[0][1][2]的形式。比如:

可以看到多次索引后,结果变为了标量。 这就如同注册账户时选择地址一样。
索引可以是负值,正索引0表示第一个元素,而负索引-1表示最后一个元素。
2.2 使用索引列表进行切片
对于索引列表的每个维度索引,都可以用start:end:step获取切片,其切片范围为[start,end),注意end是取不到的,step指定了步长,类似于隔几行采样一次。索引可以有省略形式,start省略默认为最开始的地方,end省略默认为结束的地方,step省略表示1。如:表示范围为全部,step=1。::2表示范围为全部,但step=2。2::表示范围≥2,step=1。其他情况类似。
· 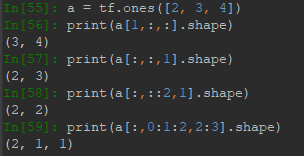
采用负索引进行切片,范围仍旧是start取得到,end取不到,切片方向仍然是从左向右,因此步长需为正。正索引与负索引可以混合使用:
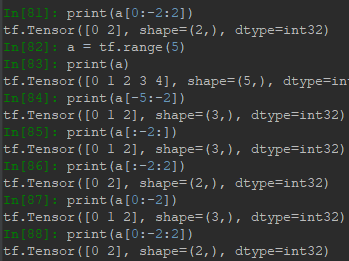
另外,通过切片可以实现逆序功能,即每个维度中的数据都倒过来排列。

当维度较多,不想打冒号,可以用...。前提是切片的范围是整个,并且,省略号不能同时出现在两边,这样是无法判断结构的。
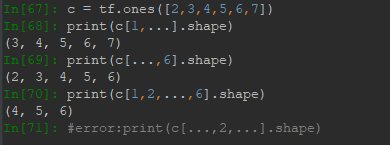
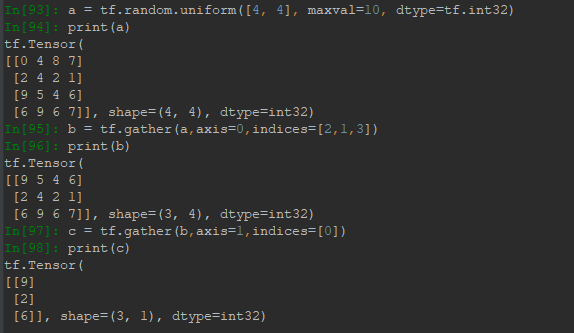
2.3 gather抽样切片
索引列表进行切片还是有很多限制,只能按一定步长等间距取样,取样是有序的。而gather可以一次对某个维度(给定axis)进行任意位置任意数量任意顺序的取样(给定indices),这里的indices不是索引坐标,而是该维度下数据位置索引的有序集合,不能用冒号形式。
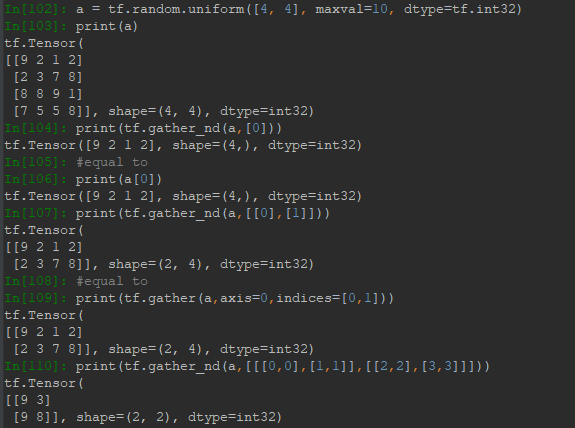
2.4 gather_nd抽样与自定义结构
gather_nd参数中给出一个结构,输出结果会将结构中的索引用数据替代,例如下面In[104],用a[0]替代了结构[0],所以结果是一个向量;又比如In[107],用a[0]替代[0],用a[1]替代[1]因为结构包裹了一层方括号,因此,结果是一个矩阵。注意这里的[0,1]可以理解为索引列表,但是不支持冒号。所以有个问题就是gather与gather_nd在截取比较复杂的数据时,会比较麻烦。
2.5 boolean_mask掩码抽样
掩码抽样需要给定一个mask,其类型为bool,也就是True,False。除此之外,可以指定一个axis,表示对特定维度进行掩码抽样,也可以不指定axis,此时mask结构决定了掩码结果的结构。若不指定axis,则必须注意mask的维度要匹配被掩码的数据维度。比如数据shape为2*4*3*2,mask的shape为2*4,那么结果shape为(n,3,2),n取决于mask中True的个数。又比如数据shape为2*4*3*2,而mask的shape为4*3*2,那么是不匹配的,因为mask的维度必须从大维度到小维度这样的顺序来匹配,这里2对应于4,4对应于3,3对应于2,就不对了。

三、维度变换
3.1 reshape分解与合并维度
reshape改变维度,并不会影响数据存储的顺序与内容,只是会丢失维度的信息,改变视图结构,进行了数据重新的组合。在改变维度的过程中,应该小心,保证更改后总大小不变,例如:

3.2 transpose转置与维度交换
transpose可以对多维Tensor进行转置,注意它并不局限于矩阵,其转置相当于将shape倒过来排列,例如[1,2,3]转置为[3,2,1]。此外,它还可以进行任意的维度交换,实际上转置也可以看做维度的交换,例如[1,2,3]现在可以将第二维和第三维交换,结果是[1,3,2]。详细情况如下,transpose指定perm时,默认功能为倒置。

3.3 expand_dims扩维与squeeze降维
在矩阵计算中经常碰到维度不一致的情况,例如一个3*3的矩阵和一个长度为3的向量做加法,需要将向量在横向上复制成3*3的矩阵。这里就可以用expand_dims+tile实现。expand_dims需要制定插入的位置,即制定axis,如果设定的axis非负,则会在axis前面扩展,否则在axis后扩展。例如对shape为(a,b)的Tensor进行扩展,指定axis=0,那么就在维度a前扩展,扩展后shape为(1,a,b);如果指定axis=-1,那么就是在维度b的后面进行扩展,扩展后shape为(a,b,1)。到此为止,expand_dims做的事类似于reshape,实际上也可以用reshape来做扩展,效果是一样的。例如:
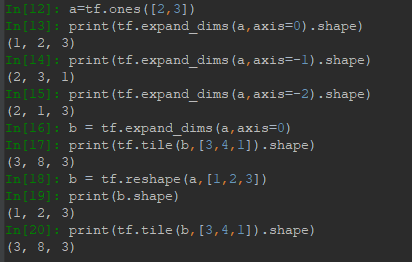
tile的作用在于将对应的维度值以倍数扩展,数据以复制形式进行填充。上例中,1->1*3;2->2*4;3->3*1。
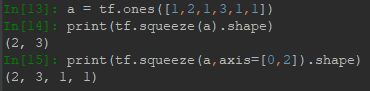
squeeze则用于降维,可以删去值等于1的维度,例如[1,2,3,1]降维后为[2,3]。squeeze用法如下图:
3.4 broadcast广播
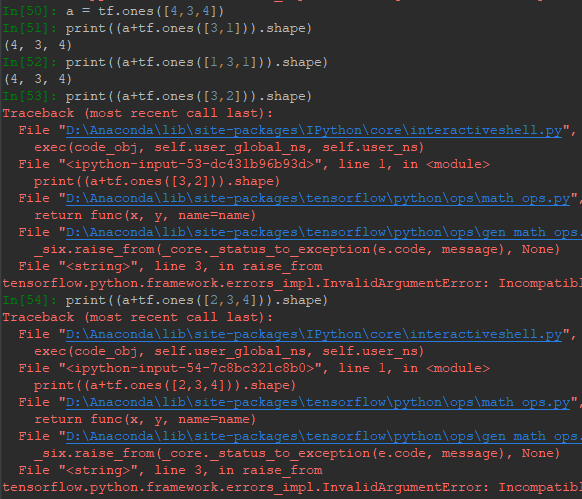
前面展示了通过expand+tile的方法进行扩展使不同维度的Tensor变为相同维度进行运算,实际中,像加减乘除一些运算支持隐式Broadcast自动扩展,Broadcast性能比expand来得好,占用内存小。正是有这种自动扩展,在Tensorflow里一些不同维度的Tensor可以直接进行运算,如下图:
可以看到,一个矩阵与向量作四则运算并未出错。原因在于运算前,向量自动扩展为(2,3)。但不是任何情况都不会出错,扩展的过程为,遵循最后一维对齐原则,缺失的维度自动扩展,且值为1,对值为1的维度进行扩展,值不为1的维度不能扩展。对比下列情况:
[3,1]可以扩展,根据右对齐原则,[3,1]缺少对应2的维度,自动扩展为(1,3,1)。左1对应于2,可以扩成2。3对应于3,不用扩展。右3对应于4,扩为4。[3,2]根据右对齐原则,2对应于4,两者不相等且不为1,所以不能扩展。
有些时候可能出现不支持隐式扩展,这时候可以显式扩展:

四、Tensor运算
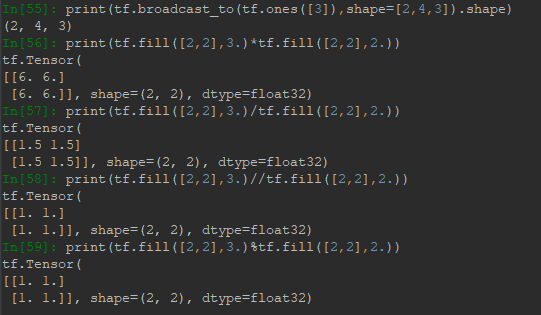
4.1 加减乘除余
加减乘除余都是对应位置元素作运算,符号为:+、-、*、/、//、%,示例如下:
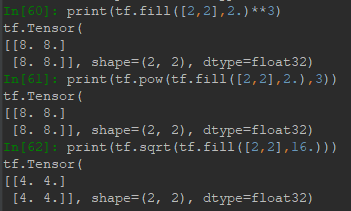
4.2 幂与平方根
Tensor的幂和平方根就是各元素的幂与平方根,符号为:**(pow)、sqrt。示例如下:
4.3 指数与对数
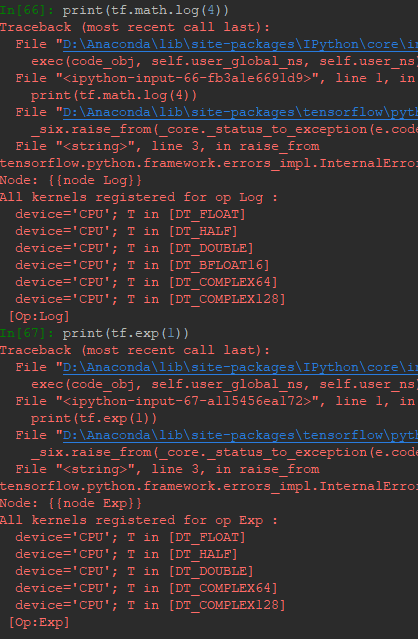
Tensor的指数和对数就是各元素的指数与对数。TensorFlow里只有以e为底的对数,要实现其他对数底,可以利用数学公式转换底到e:

另外,需要注意的是指数和对数的参数必须为浮点数,用整数会报错:
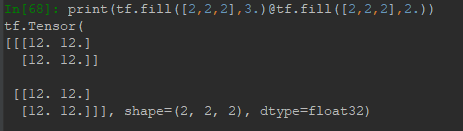
4.4 叉乘
符号为@:
深度学习-TensorFlow2.0笔记(一)的更多相关文章
- 深度学习Keras框架笔记之TimeDistributedDense类
深度学习Keras框架笔记之TimeDistributedDense类使用方法笔记 例: keras.layers.core.TimeDistributedDense(output_dim,init= ...
- 深度学习Keras框架笔记之Dense类(标准的一维全连接层)
深度学习Keras框架笔记之Dense类(标准的一维全连接层) 例: keras.layers.core.Dense(output_dim,init='glorot_uniform', activat ...
- 深度学习Keras框架笔记之AutoEncoder类
深度学习Keras框架笔记之AutoEncoder类使用笔记 keras.layers.core.AutoEncoder(encoder, decoder,output_reconstruction= ...
- 《动手学深度学习》系列笔记—— 1.2 Softmax回归与分类模型
目录 softmax的基本概念 交叉熵损失函数 模型训练和预测 获取Fashion-MNIST训练集和读取数据 get dataset softmax从零开始的实现 获取训练集数据和测试集数据 模型参 ...
- 深度学习tensorflow实战笔记(1)全连接神经网络(FCN)训练自己的数据(从txt文件中读取)
1.准备数据 把数据放进txt文件中(数据量大的话,就写一段程序自己把数据自动的写入txt文件中,任何语言都能实现),数据之间用逗号隔开,最后一列标注数据的标签(用于分类),比如0,1.每一行表示一个 ...
- [深度学习][图像处理][毕设][笔记][安装环境][下载地址]安装VS2013、matconvnet、cuda、cudnn过程中产生的一些记录,2018.5.6号
最近半个多月,被cuda等软件折磨的死去活来,昨天下午,终于安装好了环境,趁着matlab正在,在线下载VOT2016数据集,3点睡眼惺忪被闹醒后,睡不着,爬上来写这份记录. 先记录一下自己电脑的基本 ...
- 深度学习-CNN+RNN笔记
以下叙述只是简单的叙述,CNN+RNN(LSTM,GRU)的应用相关文章还很多,而且研究的方向不仅仅是下文提到的1. CNN 特征提取,用于RNN语句生成图片标注.2. RNN特征提取用于CNN内容分 ...
- deeplearning.ai 神经网络和深度学习 week1 深度学习概论 听课笔记
1. 预测房价.广告点击率:典型的神经网络,standard NN. 图像:卷积神经网络,CNN. 一维序列数据,如音频,翻译:循环神经网络,RNN. 无人驾驶,涉及到图像.雷达等更多的数据类型:混合 ...
- 深度学习tensorflow实战笔记(2)图像转换成tfrecords和读取
1.准备数据 首选将自己的图像数据分类分别放在不同的文件夹下,比如新建data文件夹,data文件夹下分别存放up和low文件夹,up和low文件夹下存放对应的图像数据.也可以把up和low文件夹换成 ...
随机推荐
- 『008』Zabbix
『006』索引-Monitoring Zabbix [001]- 点我快速打开文章[001-Zabbix 服务安装] [002]- 点我快速打开文章[002-Zabbix 前端配置] 更新中
- 在python的虚拟环境venv中使用gunicorn
昨天遇到的问题,一个服务器上有好几个虚拟机环境. 我active进一个虚拟环境,安装了新的三方库之后, 使用gunicorn启动django服务, 但还是死活提示没有安装这个三方库. 一开始没有找到原 ...
- lua 10 迭代器
转自:http://www.runoob.com/lua/lua-iterators.html 迭代器(iterator)是一种对象,它能够用来遍历标准模板库容器中的部分或全部元素,每个迭代器对象代表 ...
- MySQL学习笔记5——编码
MySQL学习笔记5之编码 编码 1.查看MySQL数据库编码 *SHOW VARIABLES LIK 'char%'; 2.编码解释 *character_set_client:MySQL使用该编码 ...
- 工具资源系列之给 windows 虚拟机装个 windows
前面我们已经介绍了如何在 Windows 宿主机安装 VMware 虚拟机,这节我们将利用安装好的 VMware 软件安装 Windows 系统. 前情回顾 虚拟机是相对于真实的物理机而言的概念,是在 ...
- git pull --rebase的理解
在使用git的过程中经常需要使用到git pull命令,在更新远端代码的同时如果与本地代码产生冲突了, 那么冲突的文件中就出现了需要手动合并的部分,而git pull --rebase不同的地方则是当 ...
- github上方便的小工具
目录 python中的fire模块 Install Reference python中的fire模块 它可以对所有Python 对象,包括functions, classes, modules, ob ...
- ShellScript值传递参数
Shell传递参数 ######################################摘自菜鸟教程:http://www.runoob.com/linux/linux-shell-passi ...
- sitecore 如何创建一个渠道分类
您可以通过渠道跟踪联系人与您的品牌的所有互动.您可以将渠道与广告系列活动相关联,以便跟踪联系人与您的品牌互动的方式.通过比较各个渠道的目标转化率,您可以了解哪些渠道可以带来更好的联系参与度.您可以在体 ...
- 如何让 C# 在运行时自动选择合适的重载方法?
如题:假设我们有一段代码: static void Main(string[] args) { ; // 假设这里的 obj 的值来自于外部方法 PrintType(obj); } public st ...