Spark 学习笔记之 distinct/groupByKey/reduceByKey
distinct/groupByKey/reduceByKey:
distinct:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testDistinct(sc)
} private def testDistinct(sc: SparkContext) = {
val rdd = sc.makeRDD(Seq("aa", "bb", "cc", "aa", "cc"), 1)
//对RDD中的元素进行去重操作
rdd.distinct(1).collect().foreach(println)
}
}
运行结果:

groupByKey:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testGroupByKey(sc) } private def testGroupByKey(sc: SparkContext) = {
val rdd: RDD[(String, Int)] = sc.makeRDD(Seq(("aa", 1), ("bb", 1), ("cc", 1), ("aa", 1), ("cc", 1)), 1)
//pair RDD,即RDD的每一行是(key, value),key相同进行聚合
rdd.groupByKey().map(v => (v._1, v._2.sum)).collect().foreach(println)
}
}
运行结果:
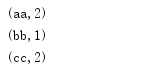
reduceByKey:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession object TransformationsDemo {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("TransformationsDemo").master("local[1]").getOrCreate()
val sc = sparkSession.sparkContext
testReduceByKey(sc) } private def testReduceByKey(sc: SparkContext) = {
val rdd: RDD[(String, Int)] = sc.makeRDD(Seq(("aa", 1), ("bb", 1), ("cc", 1), ("aa", 1), ("cc", 1)), 1)
//pair RDD,即RDD的每一行是(key, value),key相同进行聚合
rdd.reduceByKey(_+_).collect().foreach(println)
}
}
运行结果:
groupByKey与 reduceByKey区别:
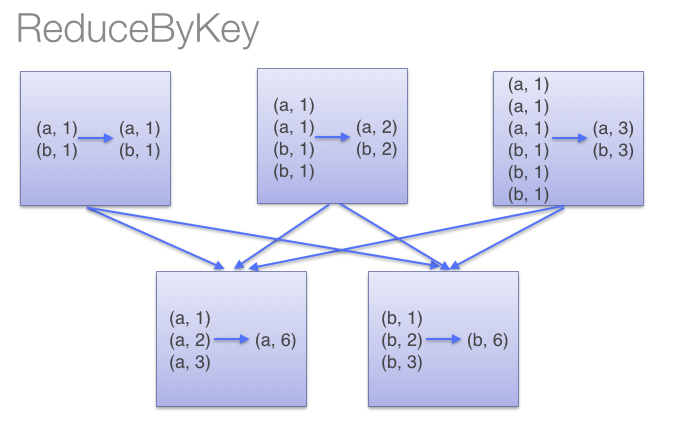
reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。groupByKey也是对每个key进行操作,但只生成一个sequence。因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动。在网络上传输这些数据非常没有必要。避免使用 GroupByKey。

Spark 学习笔记之 distinct/groupByKey/reduceByKey的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark 学习笔记:(二)编程指引(Scala版)
参考: http://spark.apache.org/docs/latest/programming-guide.html 后面懒得翻译了,英文记的,以后复习时再翻. 摘要:每个Spark appl ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
随机推荐
- P2059 [JLOI2013]卡牌游戏 概率DP
link:https://www.luogu.org/problemnew/show/P2059 题意: 有n个人,类似约瑟夫环的形式踢人,但是报的数是不同的,是在给定的许多数中随机抽取,问最后第i个 ...
- Ubuntu18.04双系统下安装CUDA10+cuDNN7.5
前言 本篇写于2019-4-25 这两天装Ubuntu18.04双系统简直装到崩溃.一是非常著名的开机卡死在Logo界面的问题,另一个是在装Nvidia驱动和CUDA的时候,更是费心.而网上的资料又良 ...
- 单细胞转录组测序技术(scRNA-seq)及细胞分离技术分类汇总
单细胞测序流程(http://learn.gencore.bio.nyu.edu) 在过去的十多年里,高通量测序技术被广泛应用于生物和医学的各种领域,极大促进了相关的研究和应用.其中转录组测序(RNA ...
- Ansible实现批量管理服务器
Ansible介绍: a. ansible是一个基于Python开发的自动化运维工具b. ansible是一个基于ssh协议实现远程管理的工具c. ansible软件可以实现多种批量管理操作(批量系统 ...
- Go语言标准库之context
在 Go http包的Server中,每一个请求在都有一个对应的 goroutine 去处理.请求处理函数通常会启动额外的 goroutine 用来访问后端服务,比如数据库和RPC服务.用来处理一个请 ...
- springboot打包jar包后运行
我们知道,spring boot内嵌tomcat,打包成jar包以后,直接就可以运行. 我们也可以使用启动项里面的mian入口来运行程序. 运行jar包时,我们一般是java -jar xxx.jar ...
- 漏洞复现:MS17-010缓冲区溢出漏洞(永恒之蓝)
MS17-010缓冲区溢出漏洞复现 攻击机:Kali Linux 靶机:Windows7和2008 1.打开攻击机Kali Linux,msf更新到最新版本(现有版本5.x),更新命令:apt-get ...
- Apache RocketMQ 消息队列部署与可视化界面安装
一.介绍 Apache RocketMQ是一个分布式.队列模型的消息中间件,具有低延迟.高性能和高可靠.万亿级容量和灵活的可扩展性.核心组件由四部分组成:Name Servers,Brokers,Pr ...
- 【第十三篇】mvc下载文件,包括配置xml保护服务端文件不被外链直接访问
这里先说下载文件 <a style="color:black; margin-right:3px;" onclick="dowAtt(' + index + ')& ...
- Winform中自定义xml配置文件,并配置获取文件路径
场景 在Winform程序中,需要将一些配置项存到配置文件中,这时就需要自定义xml的配置文件格式.并在一些工具类中去获取配置文件的路径并加载其内容. 关注公众号霸道的程序猿获取编程相关电子书.教程推 ...