理解nodejs中的stream(流)
阅读目录
一:nodeJS中的stream(流)的概念及作用?
什么是流呢?日常生活中有水流,我们很容易想得到的就是水龙头,那么水龙头流出的水是有序且有方向的(从高处往低处流)。我们在nodejs中的流也是一样的,他们也是有序且有方向的。nodejs中的流是可读的、或可写的、或可读可写的。
并且流继承了EventEmitter。因此所有的流都是EventEmitter的实列。
Node.js中有四种基本的流类型,如下:
1. Readable--可读的流(比如 fs.createReadStream()).
2. Writable--可写的流(比如 fs.createWriteStream()).
3. Duplex--可读写的流
4. Transform---在读写过程中可以修改和变换数据的Duplex流。
nodeJS中的流最大的作用是:读取大文件的过程中,不会一次性的读入到内存中。每次只会读取数据源的一个数据块。
然后后续过程中可以立即处理该数据块(数据处理完成后会进入垃圾回收机制)。而不用等待所有的数据。
我们先来看一个简单的流的实列来理解下:
1. 首先我们来创建一个大文件,如下代码:
const fs = require('fs');
const file = fs.createWriteStream('./big.txt');
// 循环500万次
for (let i = 0; i <= 5000000; i++) {
file.write('我是空智,我来测试一个大文件, 你看看我会有多大?');
}
file.end();
我在我项目文件里面新建一个app.js文件,然后把上面的代码放入到 app.js 里面去,可以看到循环了500万次后,写入500万次数据到 big.txt中去,因此会在文件目录下生成一个 big.txt文件,如下: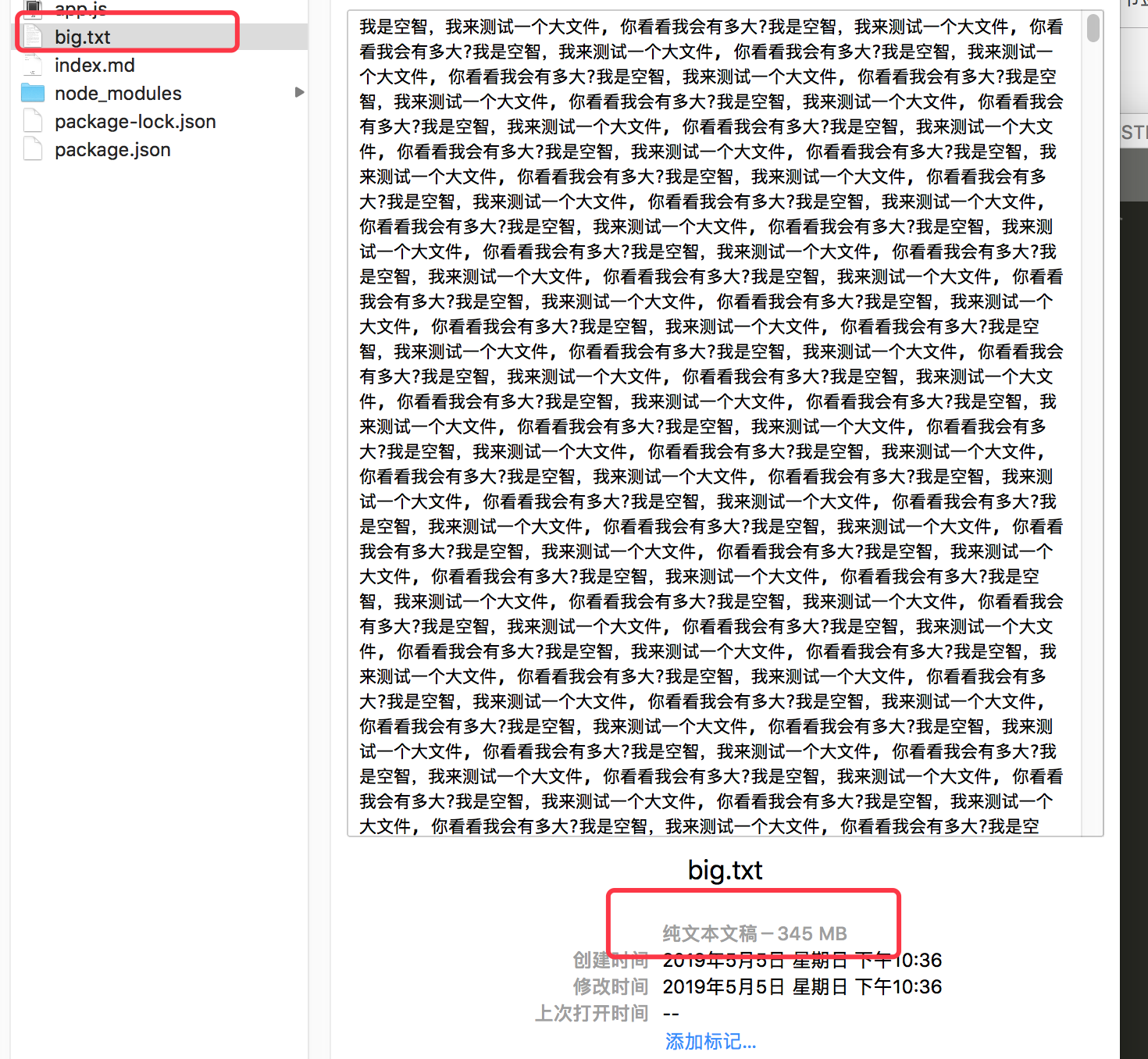
该文件在我磁盘中显示345兆。
readFile读取该文件:
下面我们使用 readFile 来读取该文件看看(readFile会一次性读入到内存中)。
我们把app.js代码改成如下:
const fs = require('fs');
const Koa = require('koa');
const app = new Koa();
app.use(async(ctx, next) => {
const res = ctx.res;
fs.readFile('./big.txt', (err, data) => {
if (err) {
throw err;
} else {
res.end(data);
}
})
});
app.listen(3001, () => {
console.log('listening on 3001');
});
当我们运行node app.js 后,我们查看下该代码占用的内存(12MB)如下:

但是当我们运行 http://localhost:3001/ 后,发现占用的内存(有338MB了)如下:
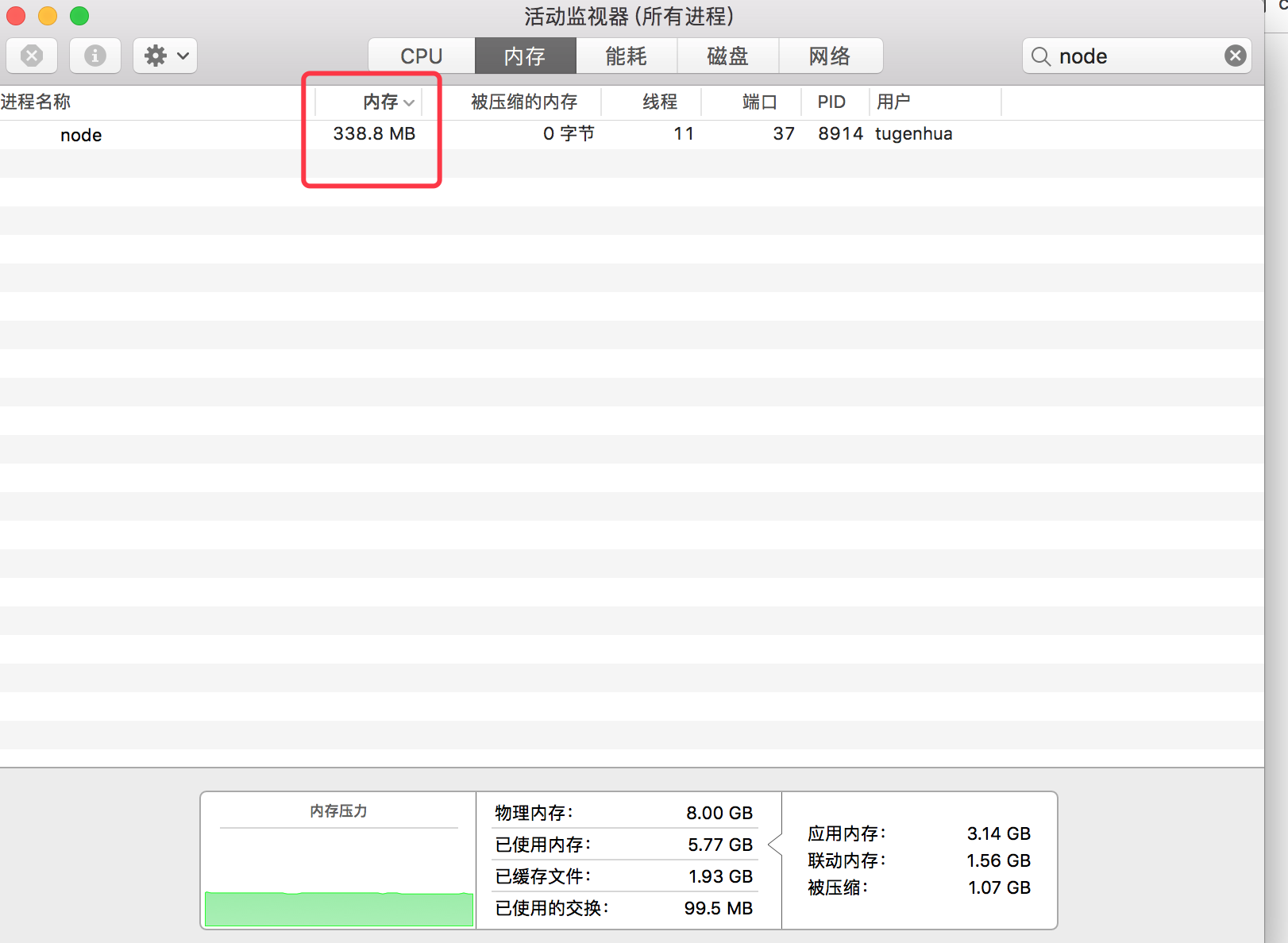
readFile 它会把 big.txt的文件内容整个的读进以Buffer格式存入到内存中,然后再写进返回对象,那么这样的效率非常低的,并且如果该文件如果是1G或2G以上的文件,那么内存会直接被卡死掉的。或者服务器直接会奔溃掉。
下面我们使用 Node中的createReadStream方法就可以避免占用内存多的情况发生。我们把app.js 代码改成如下所示:
const fs = require('fs');
const Koa = require('koa');
const app = new Koa();
app.use(async(ctx, next) => {
const res = ctx.res;
const file = fs.createReadStream('./big.txt');
file.pipe(res);
});
app.listen(3001, () => {
console.log('listening on 3001');
});
然后我们继续查看内存的使用情况,如下所示:
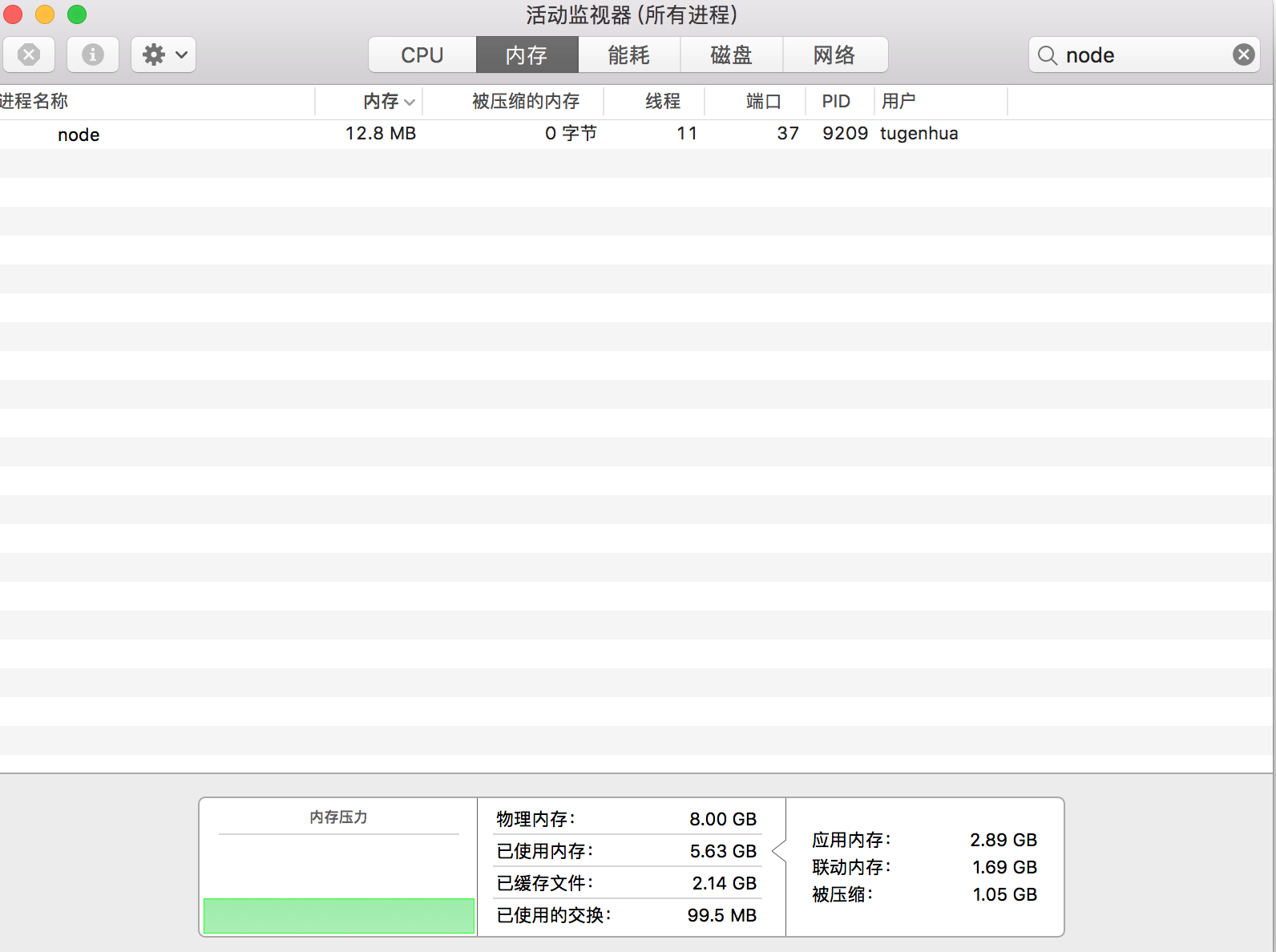
可以看到我们的占用的内存只有12.8兆。也就是说:createReadStream 在读取大文件的过程中,不会一次性的读入到内存中。
每次只会读取数据源的一个数据块。这就是流的优点。下面我们来分别看下流吧。
二:fs.createReadStream() 可读流
其基本使用方法如下:
const fs = require('fs');
const rs = fs.createReadStream('./big.txt', {
flags: 'r', // 文件的操作方式,同readFile中的配置一样,这里默认是可读的是 r
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
end: 5, // 结束读取的位置
highWaterMark: 1 // 每次读取的个数
});
fs.createReadStream有以下监听事件:
具体有哪些事件可以查看官网(http://nodejs.cn/api/stream.html#stream_class_stream_readable) 这边先截图出来简单看看,如下所示:
有了上面这些监听方法,我们可以先看一个完整的实列,如下代码:
const fs = require('fs');
const file = fs.createReadStream('./msg.txt', {
flags: 'r', // 文件的操作方式,同readFile中的配置一样,这里默认是可读的是 r
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
end: 5, // 结束读取的位置
highWaterMark: 1 // 每次读取的个数
});
file.on('open', () => {
console.log('开始读取文件');
});
file.on('data', (data) => {
console.log('读取到的数据:');
console.log(data);
});
file.on('end', () => {
console.log('文件全部读取完毕');
});
file.on('close', () => {
console.log('文件被关闭');
});
file.on('error', (err) => {
console.log('读取文件失败');
});
执行如下图所示:
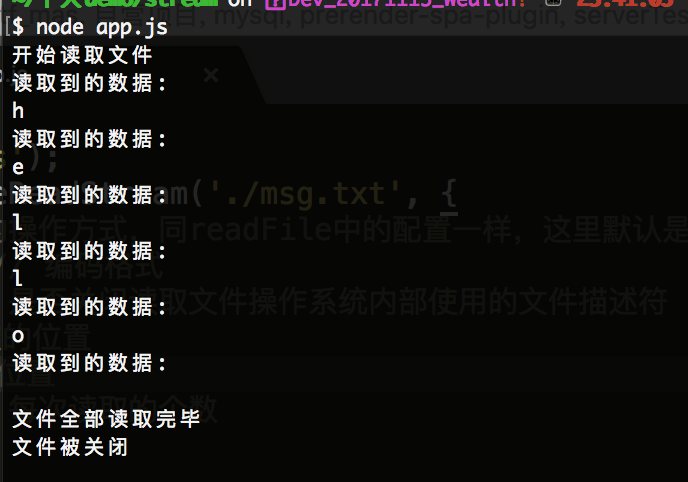
从上图我们可以看到,先打开文件,执行open事件,然后就是不断的触发data事件,等data事情读取结束后会触发end事件,然后会将文件关闭,触发close事件。
注意:msg.txt文件内容如下:hello world; 但是上面为什么只读了 hello了,那是因为我们上面限制了从开始读取位置读取,然后到结束位置结束(5). 并且限定了 highWaterMark: 1,每次读取的个数为1。当然如果我们改成每次读取的个数为2的话,那么每次会读2个字符。
pause() 方法:
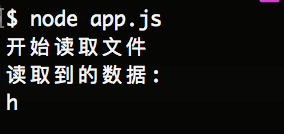
如果我们在读取的过程中,想暂停事件的读取,我们可以使用 ReadStream对象的pause方法暂停data事件的触发。 如下代码:
file.on('data', (data) => {
console.log('读取到的数据:');
console.log(data);
file.pause();
});
然后如下图所示:
上面暂停了使用 pause()方法,如果我们现在想重新读取,需要使用 resume()方法,如下所示:
setTimeout(() => {
file.resume();
}, 100);
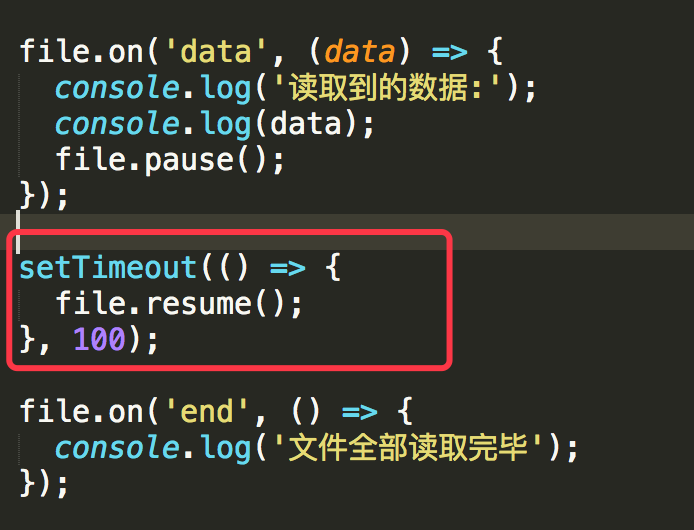
执行结果如下:

其他的一些事件,比如 readable事件等,可以看官方文档 (http://nodejs.cn/api/stream.html#stream_event_readable). 这里就不多分析了。
三:fs.createWriteStream() 可写流
如下代码演示:
const fs = require('fs');
const file = fs.createWriteStream('./1.txt', {
flags: 'w', // 文件的操作方式,同writeFile中的配置一样,这里默认是可读的是 w
encoding: 'utf-8', // 编码格式
autoClose: true, // 是否关闭读取文件操作系统内部使用的文件描述符
start: 0, // 开始读取的位置
highWaterMark: 1 // 每次写入的个数
});
let f1 = file.write('1', 'utf-8', () => {
console.log('写入成功1111');
});
f1 = file.write('2', 'utf-8', () => {
console.log('写入成功2222');
});
f1 = file.write('3', 'utf-8', () => {
console.log('写入成功3333');
});
// 标记文件末尾
file.end();
// 处理事件
file.on('finish', () => {
console.log('写入完成');
});
file.on('error', (err) => {
console.log(err);
});
在我项目的根目录下会生成一个 1.txt文件,里面有123内容。
详细请看官网(http://nodejs.cn/api/fs.html#fs_fs_writefile_file_data_options_callback)
管道流(pipe)
我们需要把我们上面可读流读到的数据需要放到可写流中去写入到文件里面去。我们可以如下操作代码:
const fs = require('fs');
// 读取msg.txt中的字符串 hello world
const msg = fs.createReadStream('./msg.txt', {
highWaterMark: 5
});
// 写入到1.txt中
const f1 = fs.createWriteStream('./1.txt', {
encoding: 'utf-8',
highWaterMark: 1
});
// 监听读取的数据过程,把读取的数据写入到我们的1.txt文件里面去
msg.on('data', (chunk) => {
f1.write(chunk, 'utf-8', () => {
console.log('写入成功');
});
});
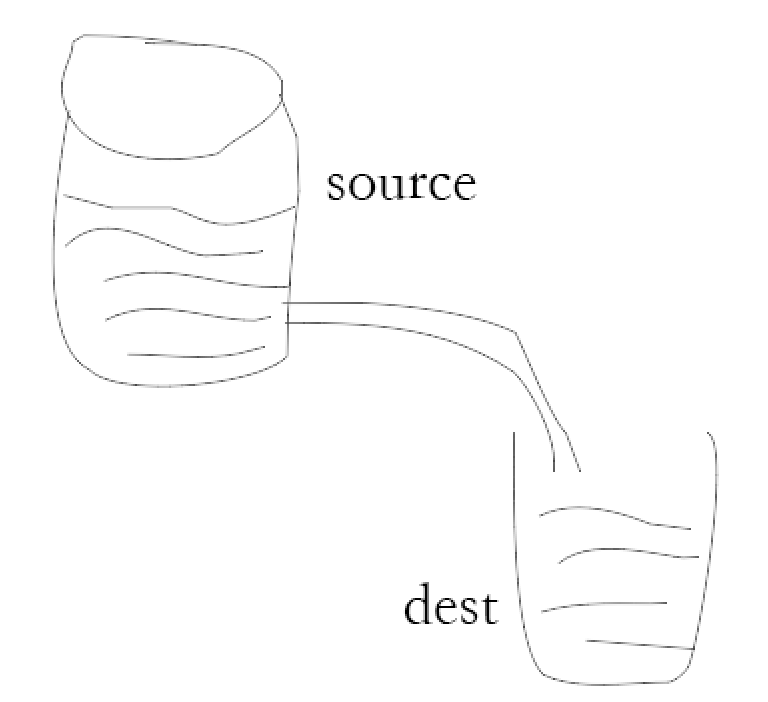
但是实现如上的机制,我们可以使用管道机制,管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。如下图所示:
如上代码,我们可以改成如下代码:
const fs = require('fs');
// 读取msg.txt中的字符串 hello world
const msg = fs.createReadStream('./msg.txt', {
highWaterMark: 5
});
// 写入到1.txt中
const f1 = fs.createWriteStream('./1.txt', {
encoding: 'utf-8',
highWaterMark: 1
});
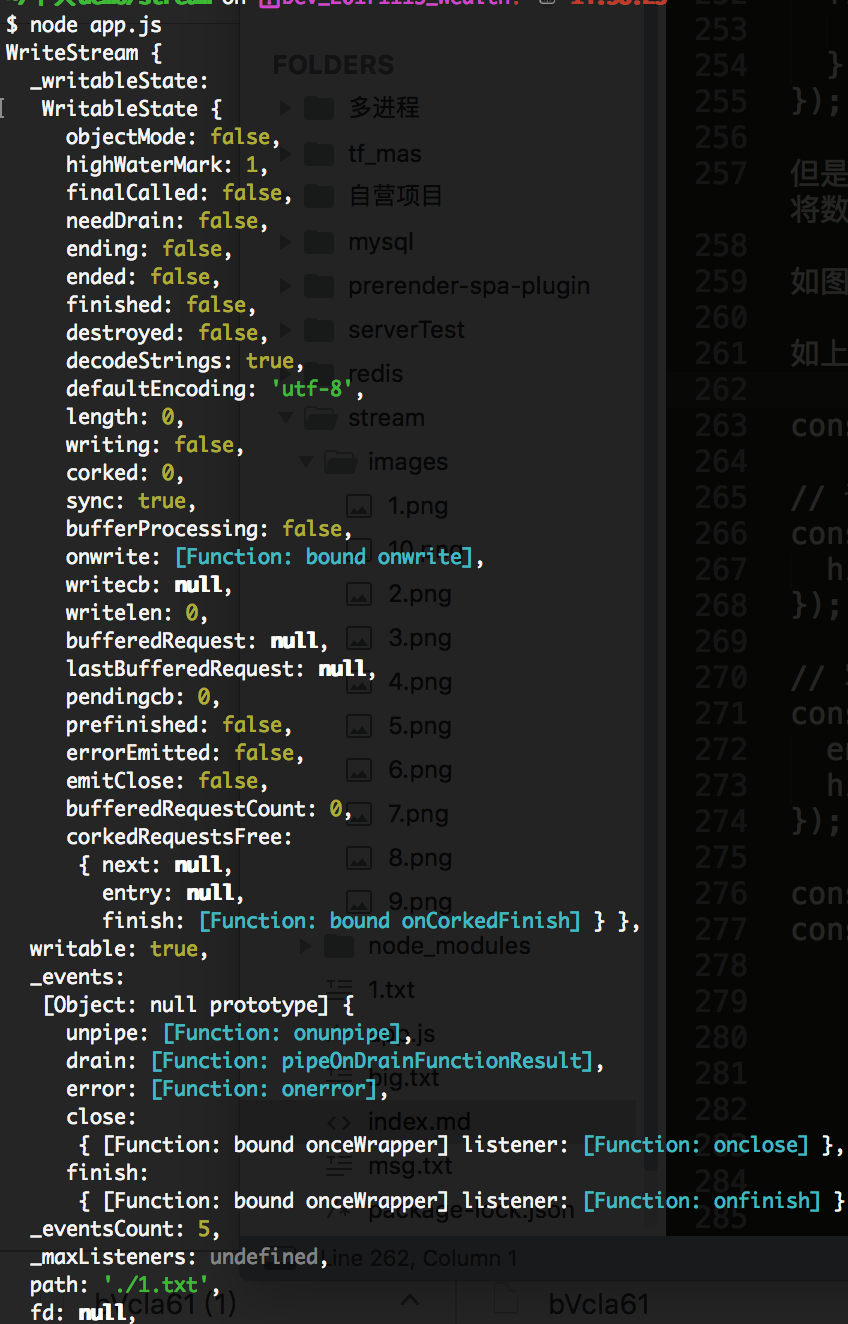
const res = msg.pipe(f1);
console.log(res);
如上打印 res后,我们在命令行中查看下基本信息如下:
理解nodejs中的stream(流)的更多相关文章
- 【Java8新特性】面试官问我:Java8中创建Stream流有哪几种方式?
写在前面 先说点题外话:不少读者工作几年后,仍然在使用Java7之前版本的方法,对于Java8版本的新特性,甚至是Java7的新特性几乎没有接触过.真心想对这些读者说:你真的需要了解下Java8甚至以 ...
- [NodeJs系列][译]理解NodeJs中的Event Loop、Timers以及process.nextTick()
译者注: 为什么要翻译?其实在翻译这篇文章前,笔者有Google了一下中文翻译,看的不是很明白,所以才有自己翻译的打算,当然能力有限,文中或有错漏,欢迎指正. 文末会有几个小问题,大家不妨一起思考一下 ...
- java中的Stream流
java中的Stream流 说到Stream便容易想到I/O Stream,而实际上,谁规定"流"就一定是"IO流"呢?在Java 8中,得益于Lambda所带 ...
- Java8中的Stream流式操作 - 入门篇
作者:汤圆 个人博客:javalover.cc 前言 之前总是朋友朋友的叫,感觉有套近乎的嫌疑,所以后面还是给大家改个称呼吧 因为大家是来看东西的,所以暂且叫做官人吧(灵感来自于民间流传的四大名著之一 ...
- Node 中的 stream (流)
流的概念 流(stream)在 Node.js 中是处理流数据的抽象接口(abstract interface). stream 模块提供了基础的 API .使用这些 API 可以很容易地来构建实现流 ...
- 深入理解nodejs中的异步编程
目录 简介 同步异步和阻塞非阻塞 javascript中的回调 回调函数的错误处理 回调地狱 ES6中的Promise 什么是Promise Promise的特点 Promise的优点 Promise ...
- 双层for循环用java中的stream流来实现
//双重for循环for (int i = 0; i < fusRecomConfigDOList.size(); i++) { for (int j = 0; j < fusRecomC ...
- 理解 nodeJS 中的 buffer,stream
在Node.js开发中,当遇到 buffer,stream,和二进制数据处理时,你是否像我一样,总是感到困惑?这种感觉是否会让你认为不了解它们,以为它们不适合你,认为而这些是Node.js作者们的事情 ...
- 77.深入理解nodejs中Express的中间件
转自:https://blog.csdn.net/huang100qi/article/details/80220012 Express是一个基于Node.js平台的web应用开发框架,在Node.j ...
随机推荐
- 最牛MongoDB灾难恢复(WiredTiger.wt文件损坏,Mongo无法启动)
WiredTiger.wt文件是mongoDB的元数据文件,存储了其他数据库表的元数据信息.笔者最近遇到了WiredTiger.wt文件损坏的情况,MongoDB无法启动,数据库中的重要数据危在旦夕. ...
- python 查询 elasticsearch 常用方法(Query DSL)
1. 建立连接 from elasticsearch import Elasticsearch es = Elasticsearch(["localhost:9200"]) 2. ...
- 2015-2016 ACM-ICPC, NEERC, Northern Subregional Contest D:Distribution in Metagonia(构造)
http://codeforces.com/gym/100801/attachments 题意:给出一个数n(1 <= n <= 1e18),将 n 拆成 m 个整数,其中 m 必须是 2 ...
- Java 中的字符串(String)与C# 中字符串(string)的异同
1. C# 中比较两个字符串字面量是否相等,可以使用 “==”比较运算符,是因为string 类型重写(override)了“==” 和 “!=” 运算符,在使用“==” 和 “!=” 进行字符串比较 ...
- 玩转SpringBoot之整合Mybatis拦截器对数据库水平分表
利用Mybatis拦截器对数据库水平分表 需求描述 当数据量比较多时,放在一个表中的时候会影响查询效率:或者数据的时效性只是当月有效的时候:这时我们就会涉及到数据库的分表操作了.当然,你也可以使用比较 ...
- Maven打包成Jar文件时依赖包的问题
我们项目中使用到第三方的库文件,这些jar库文件并没有放到Maven中央库上,导致我们需要在项目中自己配置使用.我们的两三个开发人员对Java都是很熟,因此在使用中遇到了一些问题,表现在:在本地中引入 ...
- 腾讯云tomcat问题
Ubuntu启动特别慢 1.在$JAVA_HOME/jre/lib/security/java.security中,把securerandom.source=file:/dev/urandom替换成s ...
- Mllib数据类型(密集向量和稀疏向量)
1.局部向量 Mllib支持2种局部向量类型:密集向量(dense)和稀疏向量(sparse). 密集向量由double类型的数组支持,而稀疏向量则由两个平行数组支持. example: 向量(5.2 ...
- SQLite的一些体会
SQLite遵循sql语法,所以如果接触过数据库,使用它进行增删改查几乎没障碍.在.net中,它与Mysql.sql server的类也相似,比如连接类名字是SQLiteConnection,不过它S ...
- Vue匿名组件使用keep-alive后动态清除缓存
在使用Vue开发管理系统项目的时候,为了保存页面的浏览状态,我们可以使用内置组件keep-alive来缓存组件内部状态,避免重新渲染. <keep-alive> <router-vi ...