Python机器学习笔记 Grid SearchCV(网格搜索)
在机器学习模型中,需要人工选择的参数称为超参数。比如随机森林中决策树的个数,人工神经网络模型中隐藏层层数和每层的节点个数,正则项中常数大小等等,他们都需要事先指定。超参数选择不恰当,就会出现欠拟合或者过拟合的问题。而在选择超参数的时候,有两个途径,一个是凭经验微调,另一个就是选择不同大小的参数,带入模型中,挑选表现最好的参数。
微调的一种方法是手工调制超参数,直到找到一个好的超参数组合,这么做的话会非常冗长,你也可能没有时间探索多种组合,所以可以使用Scikit-Learn的GridSearchCV来做这项搜索工作。下面让我们一一探索。
1,为什么叫网格搜索(GridSearchCV)?
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
2,什么是Grid Search网格搜索?
Grid Search:一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找到最大值。这种方法的主要缺点是比较耗时!
所以网格搜索适用于三四个(或者更少)的超参数(当超参数的数量增长时,网格搜索的计算复杂度会呈现指数增长,这时候则使用随机搜索),用户列出一个较小的超参数值域,这些超参数至于的笛卡尔积(排列组合)为一组组超参数。网格搜索算法使用每组超参数训练模型并挑选验证集误差最小的超参数组合。
2.1,以随机森林为例说明GridSearch网格搜索
下面代码,我们要搜索两种网格,一种是n_estimators,一种是max_features。GridSearch会挑选出最适合的超参数值。
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
] forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error') grid_search.fit(housing_prepared, housing_labels)
sklearn 根据param_grid的值,首先会评估3×4=12种n_estimators和max_features的组合方式,接下来在会在bootstrap=False的情况下(默认该值为True),评估2×3=6种12种n_estimators和max_features的组合方式,所以最终会有12+6=18种不同的超参数组合方式,而每一种组合方式要在训练集上训练5次, 所以一共要训练18×5=90 次,当训练结束后,你可以通过best_params_获得最好的组合方式。
grid_search.best_params_
输出结果如下:
{‘max_features’: 8, ‘n_estimators’: 30}
得到最好的模型:
grid_search.best_estimator_
输出如下:
RandomForestRegressor(bootstrap=True, criterion=‘mse’, max_depth=None,
max_features=8, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=30, n_jobs=1, oob_score=False, random_state=None,
verbose=0, warm_start=False)
如果GridSearchCV初始化时,refit=True(默认的初始化值),在交叉验证时,一旦发现最好的模型(estimator),将会在整个训练集上重新训练,这通常是一个好主意,因为使用更多的数据集会提升模型的性能。
以上面有两个参数的模型为例,参数a有3中可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历,搜索,所以叫grid search。
2.2,以Xgboost为例说明GridSearch网格搜索
下面以阿里IJCAI广告推荐数据集与XgboostClassifier分类器为例,用代码形式说明sklearn中GridSearchCV的使用方法。(此小例的代码是参考这里:请点击我)
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.grid_search import GridSearchCV #导入训练数据
traindata = pd.read_csv("/traindata_4_3.txt",sep = ',')
traindata = traindata.set_index('instance_id')
trainlabel = traindata['is_trade']
del traindata['is_trade']
print(traindata.shape,trainlabel.shape) #分类器使用 xgboost
clf1 = xgb.XGBClassifier() #设定网格搜索的xgboost参数搜索范围,值搜索XGBoost的主要6个参数
param_dist = {
'n_estimators':range(80,200,4),
'max_depth':range(2,15,1),
'learning_rate':np.linspace(0.01,2,20),
'subsample':np.linspace(0.7,0.9,20),
'colsample_bytree':np.linspace(0.5,0.98,10),
'min_child_weight':range(1,9,1)
} #GridSearchCV参数说明,clf1设置训练的学习器
#param_dist字典类型,放入参数搜索范围
#scoring = 'neg_log_loss',精度评价方式设定为“neg_log_loss“
#n_iter=300,训练300次,数值越大,获得的参数精度越大,但是搜索时间越长
#n_jobs = -1,使用所有的CPU进行训练,默认为1,使用1个CPU
grid = GridSearchCV(clf1,param_dist,cv = 3,scoring = 'neg_log_loss',n_iter=300,n_jobs = -1) #在训练集上训练
grid.fit(traindata.values,np.ravel(trainlabel.values))
#返回最优的训练器
best_estimator = grid.best_estimator_
print(best_estimator)
#输出最优训练器的精度
这里关于网格搜索的几个参数在说明一下,评分参数“scoring”,需要根据实际的评价标准设定,阿里的IJCAI的标准时“neg_log_loss”,所以这里设定为“neg_log_loss”,sklearn中备选的评价标准如下:在一些情况下,sklearn中没有现成的评价函数,sklearn是允许我们自定义的,但是需要注意格式。
接下来看一下我们定义的评价函数:
import numpy as np
from sklearn.metrics import make_scorer def logloss(act, pred):
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1, act)*sp.log(sp.subtract(1, pred)))
ll = ll * -1.0/len(act)
return ll #这里的greater_is_better参数决定了自定义的评价指标是越大越好还是越小越好
loss = make_scorer(logloss, greater_is_better=False)
score = make_scorer(logloss, greater_is_better=True)
定义好以后,再将其带入GridSearchCV函数就好。
这里再贴一下常用的集成学习算法比较重要的需要调参的参数:
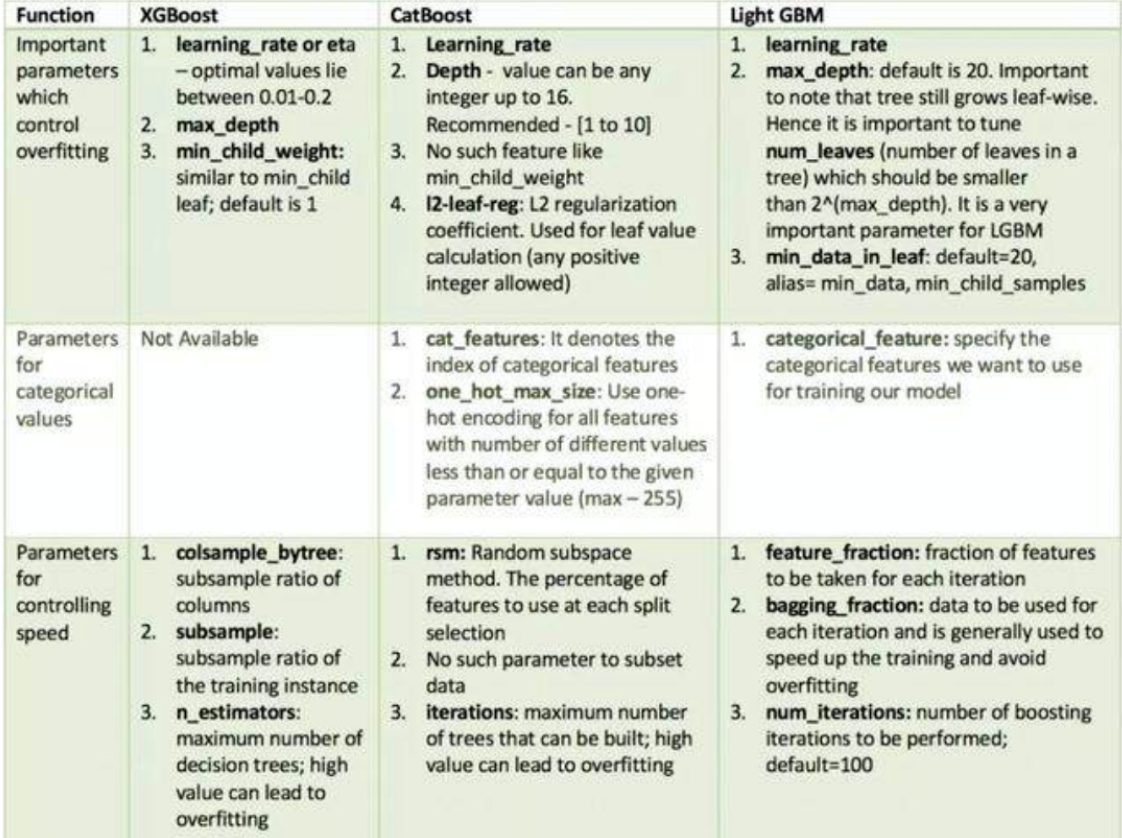
2.3,以SVR为例说明GridSearch网格搜索
以两个参数的调优过程为例:
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split iris_data = load_iris()
X_train,X_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,random_state=0) # grid search start
best_score = 0
for gamma in [0.001,0.01,1,10,100]:
for c in [0.001,0.01,1,10,100]:
# 对于每种参数可能的组合,进行一次训练
svm = SVC(gamma=gamma,C=c)
svm.fit(X_train,y_train)
score = svm.score(X_test,y_test)
# 找到表现最好的参数
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma,"C":c} print('Best socre:{:.2f}'.format(best_score))
print('Best parameters:{}'.format(best_parameters))
输出结果:
Best socre:0.97
Best parameters:{'gamma': 0.001, 'C': 100}
2.4 上面调参存在的问题是什么呢?
原始数据集划分成训练集和测试集以后,其中测试集除了用作调整参数,也用来测量模型的好坏;这样做导致最终的评分结果比实际效果好。(因为测试集在调参过程中,送到了模型里,而我们的目的是将训练模型应用到unseen data上)。
2.5 解决方法是什么呢?
对训练集再进行一次划分,分为训练集和验证集,这样划分的结果就是:原始数据划分为3份,分别为:训练集,验证集和测试集;其中训练集用来模型训练,验证集用来调整参数,而测试集用来衡量模型表现好坏。

代码:
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split iris_data = load_iris()
# X_train,X_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,random_state=0)
X_trainval,X_test,y_trainval,y_test = train_test_split(iris_data.data,iris_data.target,random_state=0)
X_train ,X_val,y_train,y_val = train_test_split(X_trainval,y_trainval,random_state=1)
# grid search start
best_score = 0
for gamma in [0.001,0.01,1,10,100]:
for c in [0.001,0.01,1,10,100]:
# 对于每种参数可能的组合,进行一次训练
svm = SVC(gamma=gamma,C=c)
svm.fit(X_train,y_train)
score = svm.score(X_val,y_val)
# 找到表现最好的参数
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma,"C":c} # 使用最佳参数,构建新的模型
svm = SVC(**best_parameters) # 使用训练集和验证集进行训练 more data always resultd in good performance
svm.fit(X_trainval,y_trainval) # evalyation 模型评估
test_score = svm.score(X_test,y_test) print('Best socre:{:.2f}'.format(best_score))
print('Best parameters:{}'.format(best_parameters))
print('Best score on test set:{:.2f}'.format(test_score))
结果:
Best socre:0.96
Best parameters:{'gamma': 0.001, 'C': 10}
Best score on test set:0.92
然而,这种简洁的grid search方法,其最终的表现好坏与初始数据的划分结果有很大的关系,为了处理这种情况,我们采用交叉验证的方式来减少偶然性。
2.6,交叉验证改进SVM代码(Grid Search with Cross Validation)
代码:
from sklearn.datasets import load_iris
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split,cross_val_score iris_data = load_iris()
# X_train,X_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,random_state=0)
X_trainval,X_test,y_trainval,y_test = train_test_split(iris_data.data,iris_data.target,random_state=0)
X_train ,X_val,y_train,y_val = train_test_split(X_trainval,y_trainval,random_state=1)
# grid search start
best_score = 0
for gamma in [0.001,0.01,1,10,100]:
for c in [0.001,0.01,1,10,100]:
# 对于每种参数可能的组合,进行一次训练
svm = SVC(gamma=gamma,C=c)
# 5 折交叉验证
scores = cross_val_score(svm,X_trainval,y_trainval,cv=5)
score = scores.mean()
# 找到表现最好的参数
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma,"C":c} # 使用最佳参数,构建新的模型
svm = SVC(**best_parameters) # 使用训练集和验证集进行训练 more data always resultd in good performance
svm.fit(X_trainval,y_trainval) # evalyation 模型评估
test_score = svm.score(X_test,y_test) print('Best socre:{:.2f}'.format(best_score))
print('Best parameters:{}'.format(best_parameters))
print('Best score on test set:{:.2f}'.format(test_score))
结果:
Best socre:0.97
Best parameters:{'gamma': 0.01, 'C': 100}
Best score on test set:0.97
交叉验证经常与网络搜索进行结合,作为参数评价的一种方法,这种方法叫做grid search with cross validation。
sklearn因此设计了一个这样的类GridSearchCV,这个类实现fit,predict,score等方法。被当做一个estimator,使用fit方法,该过程中:
- (1) 搜索到最佳参数
- (2)实例化了一个最佳参数的estimator
3,RandomizedSearchCV——(随机搜索)
文献地址可以参考:请点击我
所谓的模型配置,一般统称为模型的超参数(Hyperparameters),比如KNN算法中的K值,SVM中不同的核函数(Kernal)等。多数情况下,超参数等选择是无限的。在有限的时间内,除了可以验证人工预设几种超参数组合以外,也可以通过启发式的搜索方法对超参数组合进行调优。称这种启发式的超参数搜索方法为网格搜索。
我们在搜索超参数的时候,如果超参数个数较少(三四个或者更少),那么我们可以采用网格搜索,一种穷尽式的搜索方法。但是当超参数个数比较多的时候,我们仍然采用网格搜索,那么搜索所需时间将会指数级上升。
所以有人就提出了随机搜索的方法,随机在超参数空间中搜索几十几百个点,其中就有可能有比较小的值。这种做法比上面稀疏化网格的做法快,而且实验证明,随机搜索法结果比稀疏网格法稍好。
RandomizedSearchCV使用方法和类GridSearchCV 很相似,但他不是尝试所有可能的组合,而是通过选择每一个超参数的一个随机值的特定数量的随机组合,这个方法有两个优点:
- 如果你让随机搜索运行, 比如1000次,它会探索每个超参数的1000个不同的值(而不是像网格搜索那样,只搜索每个超参数的几个值)
- 你可以方便的通过设定搜索次数,控制超参数搜索的计算量。
RandomizedSearchCV的使用方法其实是和GridSearchCV一致的,但它以随机在参数空间中采样的方式代替了GridSearchCV对于参数的网格搜索,在对于有连续变量的参数时,RandomizedSearchCV会将其当做一个分布进行采样进行这是网格搜索做不到的,它的搜索能力取决于设定的n_iter参数,同样的给出代码。
代码如下:
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.grid_search import RandomizedSearchCV #导入训练数据
traindata = pd.read_csv("/traindata.txt",sep = ',')
traindata = traindata.set_index('instance_id')
trainlabel = traindata['is_trade']
del traindata['is_trade']
print(traindata.shape,trainlabel.shape) #分类器使用 xgboost
clf1 = xgb.XGBClassifier() #设定搜索的xgboost参数搜索范围,值搜索XGBoost的主要6个参数
param_dist = {
'n_estimators':range(80,200,4),
'max_depth':range(2,15,1),
'learning_rate':np.linspace(0.01,2,20),
'subsample':np.linspace(0.7,0.9,20),
'colsample_bytree':np.linspace(0.5,0.98,10),
'min_child_weight':range(1,9,1)
} #RandomizedSearchCV参数说明,clf1设置训练的学习器
#param_dist字典类型,放入参数搜索范围
#scoring = 'neg_log_loss',精度评价方式设定为“neg_log_loss“
#n_iter=300,训练300次,数值越大,获得的参数精度越大,但是搜索时间越长
#n_jobs = -1,使用所有的CPU进行训练,默认为1,使用1个CPU
grid = RandomizedSearchCV(clf1,param_dist,cv = 3,scoring = 'neg_log_loss',n_iter=300,n_jobs = -1) #在训练集上训练
grid.fit(traindata.values,np.ravel(trainlabel.values))
#返回最优的训练器
best_estimator = grid.best_estimator_
print(best_estimator)
#输出最优训练器的精度
print(grid.best_score_)
建议使用随机搜索。
超参数搜索——网格搜索&并行搜索代码
#-*- coding:utf-8 -*- #1.使用单线程对文本分类的朴素贝叶斯模型的超参数组合执行网格搜索 from sklearn.datasets import fetch_20newsgroups
import numpy as np
news = fetch_20newsgroups(subset='all')
from sklearn.cross_validation import train_test_split
#取前3000条新闻文本进行数据分割
X_train,X_test,y_train,y_test=train_test_split(news.data[:3000],
news.target[:3000],test_size=0.25,random_state=33) from sklearn.svm import SVC
from sklearn.feature_extraction.text import TfidfVectorizer
#*************导入pipeline*************
from sklearn.pipeline import Pipeline
#使用Pipeline简化系统搭建流程,sklean提供的pipeline来将多个学习器组成流水线,通常流水线的形式为:
#将数据标准化的学习器---特征提取的学习器---执行预测的学习器
#将文本特征与分类器模型串联起来,[(),()]里有两个参数
#参数1:执行 vect = TfidfVectorizer(stop_words='english',analyzer='word')操作
#参数2:执行 svc = SVC()操作
clf = Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())]) #这里需要试验的2个超参数svc_gamma和svc_C的元素个数分别为4、3,这样我们一共有12种超参数对集合
#numpy.linspace用于创建等差数列,numpy.logspace用于创建等比数列
#logspace中,开始点和结束点是10的幂
#例如logspace(-2,1,4)表示起始数字为10^-2,结尾数字为10^1即10,元素个数为4的等比数列
#parameters变量里面的key都有一个前缀,这个前缀其实就是在Pipeline中定义的操作名。二者相结合,使我们的代码变得十分简洁。
#还有注意的是,这里对参数名是<两条>下划线 __
parameters = {'svc__gamma':np.logspace(-2,1,4),'svc__C':np.logspace(-1,1,3)} #从sklearn.grid_search中导入网格搜索模块GridSearchCV
from sklearn.grid_search import GridSearchCV
#GridSearchCV参数解释:
#1.estimator : estimator(评估) object.
#2.param_grid : dict or list of dictionaries
#3.verbose:Controls the verbosity(冗余度): the higher, the more messages.
#4.refit:default=True, Refit(再次拟合)the best estimator with the entire dataset
#5.cv : int, cross-validation generator 此处表示3折交叉验证
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3) #执行单线程网格搜索
gs.fit(X_train,y_train) print gs.best_params_,gs.best_score_ #最后输出最佳模型在测试集上的准确性
print 'the accuracy of best model in test set is',gs.score(X_test,y_test) #小结:
#1.由输出结果可知,使用单线程的网格搜索技术 对朴素贝叶斯模型在文本分类任务中的超参数组合进行调优,
# 共有12组超参数组合*3折交叉验证 =36项独立运行的计算任务
#2.在本机上,该过程一共运行了2.9min,寻找到最佳的超参数组合在测试集上达到的分类准确性为82.27%
#2.使用多线程对文本分类的朴素贝叶斯模型的超参数组合执行网格搜索 #n_jobs=-1,表示使用该计算机的全部cpu
gs = GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
gs.fit(X_train,y_train)
print gs.best_params_,gs.best_score_
#输出最佳模型在测试集上的准确性
print 'the accuracy of best model in test set is',gs.score(X_test,y_test) #小结:
#总任务相同的情况下,使用并行搜索技术进行计算的话,执行时间只花费了1.1min;
#而且最终所得的的best_params_和score没有发生变化,说明并行搜索可以在不影响准确性的前提下,
#有效的利用计算机的CPU资源,大大节省了最佳超参数的搜索时间。
4, 超参数估计的随机搜索和网格搜索的比较
使用的数据集是小数据集 手写数字数据集 load_digits() 分类 数据规模 5620*64
(sklearn中的小数据可以直接使用,大数据集在第一次使用的时候会自动下载)
比较随机森林超参数优化的随机搜索和网格搜索。所有影响学习的参数都是同时搜索的(除了估计值的数量,它会造成时间/质量的权衡)。
随机搜索和网格搜索探索的是完全相同的参数空间。参数设置的结果非常相似,而随机搜索的运行时间要低的多。
随机搜索的性能稍差,不过这很可能是噪声效应,不会延续到外置测试集
注意:在实践中,人们不会使用网格搜索同时搜索这么多不同的参数,而是只选择那些被认为最重要的参数。
代码如下:
#_*_coding:utf-8_*_
# 输出文件开头注释的内容 __doc__的作用
'''
Python有个特性叫做文档字符串,即DocString ,这个特性可以让你的程序文档更加清晰易懂
'''
print(__doc__)
import numpy as np
from time import time
from scipy.stats import randint as sp_randint from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier # get some data
digits = load_digits()
X, y = digits.data , digits.target # build a classifier
clf = RandomForestClassifier(n_estimators=20) # utility function to report best scores
def report(results, n_top= 3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
print("Model with rank:{0}".format(i))
print("Mean validation score : {0:.3f} (std: {1:.3f})".
format(results['mean_test_score'][candidate],
results['std_test_score'][candidate]))
print("Parameters: {0}".format(results['params'][candidate]))
print("") # 指定取样的参数和分布 specify parameters and distributions to sample from
param_dist = {"max_depth":[3,None],
"max_features":sp_randint(1,11),
"min_samples_split":sp_randint(2,11),
"bootstrap":[True, False],
"criterion":["gini","entropy"]
} # run randomized search
n_iter_search = 20
random_search = RandomizedSearchCV(clf,param_distributions=param_dist,
n_iter=n_iter_search,cv =5)
start = time()
random_search.fit(X, y)
print("RandomizedSearchCV took %.2f seconds for %d candidates"
" parameter settings." % ((time() - start), n_iter_search))
report(random_search.cv_results_) # use a full grid over all parameters
param_grid = {"max_depth":[3,None],
"max_features":[1, 3, 10],
"min_samples_split":[2, 3, 10],
"bootstrap":[True, False],
"criterion":["gini","entropy"]
}
# run grid search
grid_search = GridSearchCV(clf, param_grid=param_grid, cv =5)
start = time()
grid_search.fit(X , y)
print("GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(grid_search.cv_results_['params'])))
report(grid_search.cv_results_)
结果如下:
RandomizedSearchCV took 6.20 seconds for 20 candidates parameter settings.
Model with rank:1
Mean validation score : 0.930 (std: 0.031)
Parameters: {'bootstrap': False, 'criterion': 'entropy', 'max_depth': None, 'max_features': 6, 'min_samples_split': 5} Model with rank:2
Mean validation score : 0.929 (std: 0.024)
Parameters: {'bootstrap': False, 'criterion': 'entropy', 'max_depth': None, 'max_features': 6, 'min_samples_split': 9} Model with rank:3
Mean validation score : 0.924 (std: 0.020)
Parameters: {'bootstrap': False, 'criterion': 'gini', 'max_depth': None, 'max_features': 3, 'min_samples_split': 6} Model with rank:1
Mean validation score : 0.932 (std: 0.023)
Parameters: {'bootstrap': False, 'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 3} Model with rank:2
Mean validation score : 0.931 (std: 0.014)
Parameters: {'bootstrap': False, 'criterion': 'gini', 'max_depth': None, 'max_features': 3, 'min_samples_split': 3} Model with rank:3
Mean validation score : 0.929 (std: 0.021)
Parameters: {'bootstrap': False, 'criterion': 'entropy', 'max_depth': None, 'max_features': 3, 'min_samples_split': 2}
scikit-learn GridSearch库概述
sklearn的Grid Search官网地址:请点击我
1,GridSearchCV简介
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得到结果。这个时候就需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调参,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会跳到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试,后续可以再拿bagging再优化。
通常算法不够好,需要调试参数时必不可少。比如SVM的惩罚因子C,核函数kernel,gamma参数等,对于不同的数据使用不同的参数,结果效果可能差1~5个点,sklearn为我们专门调试参数的函数grid_search。
2,GridSearchCV参数说明
参数如下:
class sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None,
fit_params=None, n_jobs=None, iid=’warn’, refit=True, cv=’warn’, verbose=0,
pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’, return_train_score=’warn’)
说明如下:
1)estimator:选择使用的分类器,并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法:如estimator = RandomForestClassifier(min_sample_split=100,min_samples_leaf = 20,max_depth = 8,max_features = 'sqrt' , random_state =10),
2)param_grid:需要最优化的参数的取值,值为字典或者列表,例如:param_grid = param_test1,param_test1 = {'n_estimators' : range(10,71,10)}
3)scoring = None :模型评价标准,默认为None,这时需要使用score函数;或者如scoring = 'roc_auc',根据所选模型不同,评价准则不同,字符串(函数名),或是可调用对象,需要其函数签名,形如:scorer(estimator,X,y);如果是None,则使用estimator的误差估计函数。
4)fit_para,s = None
5)n_jobs = 1 : n_jobs:并行数,int:个数,-1:跟CPU核数一致,1:默认值
6)iid = True:iid:默认为True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
7)refit = True :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可能的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
8)cv = None:交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
9)verbose = 0 ,scoring = None verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出。
10)pre_dispatch = '2*n_jobs' :指定总共发的并行任务数,当n_jobs大于1时候,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次。
3,进行预测的常用方法和属性
- grid.fit() :运行网格搜索
- grid_scores_ :给出不同参数情况下的评价结果
- best_params_ :描述了已取得最佳结果的参数的组合
- best_score_ :提供优化过程期间观察到的最好的评分
- cv_results_ :具体用法模型不同参数下交叉验证的结果
4,GridSearchCV属性说明
(1) cv_results_ : dict of numpy (masked) ndarrays
具有键作为列标题和值作为列的dict,可以导入到DataFrame中。注意,“params”键用于存储所有参数候选项的参数设置列表。
(2) best_estimator_ : estimator
通过搜索选择的估计器,即在左侧数据上给出最高分数(或指定的最小损失)的估计器。如果refit = False,则不可用。
(3)best_score_ :float best_estimator的分数
(4)best_parmas_ : dict 在保存数据上给出最佳结果的参数设置
(5) best_index_ : int 对应于最佳候选参数设置的索引(cv_results_数组)
search.cv_results _ ['params'] [search.best_index_]中的dict给出了最佳模型的参数设置,给出了最高的平均分数(search.best_score_)。
(6)scorer_ : function
Scorer function used on the held out data to choose the best parameters for the model.
(7)n_splits_ : int
The number of cross-validation splits (folds/iterations).
3,利用决策树预测乳腺癌的例子(网格搜索算法优化)
3.1 网格搜索算法与K折交叉验证理论知识
网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
以决策树为例,当我们确定了要使用决策树算法的时候,为了能够更好地拟合和预测,我们需要调整它的参数。在决策树算法中,我们通常选择的参数是决策树的最大深度。
于是下面我们会给出一系列的最大深度的值,比如{‘max_depth’:[1,2,3,4,5] },我们就会尽可能包含最优最大深度。
不过我们如何知道哪个最大深度的模型是最好的呢?我们需要一种可靠的评分方法,对每个最大深度的决策树模型都进行评价,这其中非常经典的一种方法就是交叉验证,下面我们就以K折交叉验证为例,详细介绍一下其算法过程。
首先我们先看一下数据集时如何分割的,我们拿到的原始数据集首先会按照一定的比例划分出训练集和测试集。比如下图,以8:2分割的数据集:
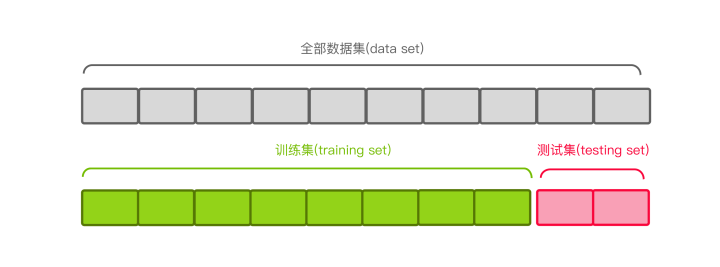
训练集是用来训练我们的模型,它的作用就像我们平时做的练习题;测试集用来评估我们训练好的模型表现如何,它不能被提前被模型看到。
因此,在K折交叉验证中,我们用到的数据是训练集中的所有数据,我们将训练集的所有数据平均划分出K份(通常选择K=10),取第K份作为验证集,它的作用就像我们用来估计高考分数的模拟题,余下的K-1份作为交叉验证的训练集。
对于我们最开始选择的决策树的5个最大深度,以max_depth=1为例,我们先用第2-10份数据作为训练集训练模型,用第一份数据作为验证集对这次训练的模型进行评分,得到第一个分数;然后重新构建一个max_depth = 1的决策树,用第1和3-10份数据作为训练集训练模型,用第2份数据作为验证集对这次训练的模型进行评分,得到第二个分数.....以此类推,最后构建一个max_depth = 1的决策树用第1-9份数据作为训练集训练模型,用第10份数据作为验证集对这次训练的模型进行评分,得到10个验证分数,然后计算着10个验证分数的平均分数,就是max_depth = 1的决策树模型的最终验证分数。

对于max_depth = 2,3,4,5时,分别进行和max_depth =1 相同的交叉验证过程,得到他们的最终验证分数,然后我们就可以对这5个最大深度的决策树的最终验证分数进行比较,分数最高的那个就是最优最大深度,我们利用最优参数在全部训练集上训练一个新的模型,整个模型就是最优模型。
3.2 简单的利用决策树预测乳腺癌的例子
代码:
from sklearn.model_selection import GridSearchCV,KFold,train_test_split
from sklearn.metrics import make_scorer , accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
import warnings
from sklearn.neighbors import KNeighborsClassifier as KNN warnings.filterwarnings('ignore') # load data
data = load_breast_cancer()
print(data.data.shape)
print(data.target.shape)
# (569, 30)
# (569,)
X,y = data['data'] , data['target'] X_train,X_test,y_train,y_test = train_test_split(
X,y,train_size=0.8 , random_state=0
) regressor = DecisionTreeClassifier(random_state=0)
parameters = {'max_depth':range(1,6)}
scorin_fnc = make_scorer(accuracy_score)
kflod = KFold(n_splits=10) grid = GridSearchCV(regressor,parameters,scorin_fnc,cv=kflod)
grid = grid.fit(X_train,y_train)
reg = grid.best_estimator_ print('best score:%f'%grid.best_score_)
print('best parameters:')
for key in parameters.keys():
print('%s:%d'%(key,reg.get_params()[key])) print('test score : %f'%reg.score(X_test,y_test)) # import pandas as pd
# pd.DataFrame(grid.cv_results_).T # 引入KNN训练方法
knn = KNN()
# 进行填充测试数据进行训练
knn.fit(X_train,y_train)
params = knn.get_params()
score = knn.score(X_test,y_test)
print("KNN 预测得分为:%s"%score)
结果:
(569, 30)
(569,)
best score:0.938462
best parameters:
max_depth:4
test score : 0.956140
KNN 预测得分为:0.9385964912280702
问题一:AttributeError: 'GridSearchCV' object has no attribute 'grid_scores_'
问题描述:
Python运行代码的时候,到gsearch1.grid_scores_ 时报错:
AttributeError: 'GridSearchCV' object has no attribute 'grid_scores_'
原因:
之所以出现以上问题,原因在于grid_scores_在sklearn0.20版本中已被删除,取而代之的是cv_results_。
解决方法:
将下面代码:
a,b,c = gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
换成:
a,b,c = gsearch1.cv_results_, gsearch1.best_params_, gsearch1.best_score_
问题二:ModuleNotFoundError: No module named 'sklearn.grid_search'
问题描述:
Python运行代码时候,到from sklearn.grid_search import GridSearchCV时报错:
ModuleNotFoundError: No module named 'sklearn.grid_search'
原因:
sklearn.grid_search模块在0.18版本中被弃用,它所支持的类转移到model_selection 模板中。还要注意,新的CV迭代器的接口与这个模块的接口不同,sklearn.grid_search在0.20中被删除。
解决方法:
将下面代码
from sklearn.grid_search import GridSearchCV
修改成:
from sklearn.model_selection import GridSearchCV
参考文献:https://blog.51cto.com/emily18/2088128
https://blog.csdn.net/jh1137921986/article/details/79827945
https://blog.csdn.net/juezhanangle/article/details/80051256
Python机器学习笔记 Grid SearchCV(网格搜索)的更多相关文章
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- 机器学习算法中的网格搜索GridSearch实现(以k-近邻算法参数寻最优为例)
机器学习算法参数的网格搜索实现: //2019.08.031.scikitlearn库中调用网格搜索的方法为:Grid search,它的搜索方式比较统一简单,其对于算法批判的标准比较复杂,是一种复合 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- Python机器学习笔记:奇异值分解(SVD)算法
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 奇异值分解(Singu ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
随机推荐
- LinqMethod 实现 LeftJoin
LinqMethod 实现 LeftJoin Intro 有时候我们想实现 leftJoin 但是 Linq 提供的 Join 相当于是 INNER JOIN,于是就打算实现一个 LeftJoin 的 ...
- wpf file embeded resource is readonly,Copy always will copy the file and its folder to the bin folder
Wpf file embeded resource will compile the file into the assembly and it will be readonly and can no ...
- 13. 罗马数字转整数(C#)
看到这道题,存在键值对,所以先建个泛型字典,把键值填进去. 由于这道题存在两个字符表示一个数字的情况,所以在for循环的时候判断一下,看看当前字符串中循环到的字符是否和下一个字符能够组成存在在字典里的 ...
- 如何使用npm的部分用法以及npm被墙的解决方法
我们要明白我们使用的npm就是node中自带的包(模块)管理工具:借助NPM可以帮助我们快速安和管理依赖包,使Node与第三方模块之间形成了一个良好的生态系统. 我们可以直接输入npm,查看帮助引导: ...
- Winform中双击DevExpress的TreeList的树形节点怎样获取当前节点
场景 DevExpress的TreeList怎样设置数据源,从实例入手: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/10254 ...
- spark的wordcount
在开发环境下实现第一个程序wordcount 1.下载和配置scala,注意不要下载2.13,在spark-core明确支持scala2.13前,使用2.12或者2.11比较好. https://ww ...
- 模板引擎Jinja2的基本用法
Flask提供的模板引擎为Jinja2,易于使用,功能强大.模板仅仅是文本文件,它可以生成任何基于文本的格式(HTML.XML.CSV.LaTex 等等). 它并没有特定的扩展名, .html 或 . ...
- 个人项目-WC.exe (Java实现)
一.Github项目地址:https://github.com/blanche789/wordCount/tree/master/src/main/java/com/blanche 二.PSP表格 P ...
- [b0020] python 归纳 (六)_模块变量作用域
test_module2.py: # -*- coding: utf-8 -*-"""测试 模块变量的作用域 总结:1 其他模块的变量,在当前模块的任何地方,包括函数都可 ...
- 最短时间(几秒内)利用C#往SQLserver数据库一次性插入10万条数据
用途说明: 公司要求做一个数据导入程序,要求将Excel数据,大批量的导入到数据库中,尽量少的访问数据库,高性能的对数据库进行存储.于是在网上进行查找,发现了一个比较好的解决方案,就是采用SqlBul ...