jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——总结与性能分析
Sizzle引擎的主体部分已经分析完毕了,今天为这部分划一个句号。
a. Sizzle解析流程总结
是时候该做一个总结了。Sizzle解析的流程已经一目了然了。
1.选择器进入Sizzle( selector, context, results, seed )函数,先对选择器不符合要求的(比如没有选择器、选择器不为字符串、上下文环境context不是节点元素且不是document)排除,直接返回;接着判断如果选择器是简单的选择器(只有一个元选择器,比如“#ID”、“.CLASS”、“TAG”等)直接用浏览器支持的函数获取结果返回。接着判断如果浏览器支持高级搜索querySelectorAll且选择器也符合参数标准则获取结果返回。否则进入select( selector, context, results, seed )函数接着处理。
2.进入select( selector, context, results, seed )函数后。select先对选择器selector进行词法解析(tokenize( selector, parseOnly )函数),在没有备选种子seed且选择器并非多个并列选择器(“div >p,input”等用逗号分隔的是并列选择器)的情况下缩小选择范围,包括对原子选择器组tokens的第一个元选择器(最小的选择器)token = tokens[0]为“#ID”且id的下一个token是关系节点(">"/"+"/" "/"~")的情况先通过Expr.find["ID"]缩小范围(context = Expr.find["ID"](…));剩下的tokens的第一给token不是(">"/"+"/"~")的任何一个且tokens中没有Sizzle自定义的位置伪类(位置伪类有:first、last、even、odd、eq(n)、gt(n)、lt(n))的情况下,找到最后一个元选择器且保证该元选择器后面没有任何关系选择器,如果找到则根据元选择器查找到备选seed(
seed = find(token.matches[0].replace( runescape, funescape ), rsibling.test( tokens[0].type ) && context.parentNode || context)
),此时如果seed为空或者tokens中没有选择器了则直接返回结果,否则拿着缩小范围的seed继续往下查。进入compile ( selector, group /* Internal Use Only */ )编译好的函数中继续。
3. compile ( selector, group /* Internal Use Only */ )函数最终将返回一个执行终极匹配函数的curry化函数。该curry化函数最终在select函数中执行
compile( selector, match )( seed, context, documentIsXML, results, rsibling.test( selector ))
; compile函数实际就做了两件事情。一件是用tokens生成一个终极匹配函数(cached = matcherFromTokens( group[i] ))压入setMatchers或elementMatchers中。另一件事就是生成并返回执行终极匹配函数的curry化函数(
cached = compilerCache( selector, matcherFromGroupMatchers( elementMatchers, setMatchers ) );
)
4.使用matcherFromTokens生成tokens对应的终极匹配函数。matchers数组用来保存所有匹配函数数组。matchers初始化时有一个默认的匹配函数。从左往右遍历选择器(0-n遍历tokens)如果遇到关系选择器(matcher = Expr.relative[ tokens[i].type ]),则整合关系选择器和原来的matchers生成一个新的匹配函数(matchers = [ addCombinator(elementMatcher( matchers ), matcher) ];);如果遇到非关系选择器,获取选择器匹配函数(matcher = Expr.filter[ tokens[i].type ].apply( null, tokens[i].matches );),分两种情况处理,一种是伪类选择器则将选择器tokens分成四个部分分别生成相应的匹配函数然后整合直接返回终极匹配函数(
return setMatcher(
i > 1 && elementMatcher( matchers ),
i > 1 && toSelector( tokens.slice( 0, i - 1 ) ).replace( rtrim, "$1" ),
matcher,
i < j && matcherFromTokens( tokens.slice( i, j ) ),//如果伪类后面紧跟伪类并列选择器(比如“:first.chua span”)中的".chua"
j < len && matcherFromTokens( (tokens = tokens.slice( j )) ),//如果伪类(或伪类并列选择器)还有选择器要筛选
j < len && toSelector( tokens )
);
),另一种是非伪类选择器则将元选择器匹配函数压入matchers中(matchers.push( matcher );)。然后通过elementMatcher( matchers )生成终极匹配函数返回。
5.使用matcherFromGroupMatchers( elementMatchers, setMatchers )返回一个执行终极匹配函数的curry化函数。这个curry化函数内部流程是:先确定起始查找范围,或是seed,或是整个树节点。遍历终极匹配器集合elementMatchers,如果元素匹配则将节点放入结果集中
while ( (matcher = elementMatchers[j++]) ) {
if ( matcher( elem, context, xml ) ) {
results.push( elem );
break;
}
}
。然后遍历有伪类选择器的终极匹配函数做相应的处理
while ( (matcher = setMatchers[j++]) ) {
matcher( unmatched, setMatched, context, xml );
}
。完成所有流程后把匹配结果返回。
到此基本流程就结束啦。可能内部有些小细节没有深究明白,但是流程已经OK了。希望大家有所收获,哈哈。
b. 选择器效率问题
一般来说浏览器原生函数效率getElementById > getElementsByTagName >= getElementsByClassName。测试结果
测试案例(借用Arron的测试案例)
<div id="demo" class='demo'>
<ul>
<li><input type="checkbox" data="data"/></li>
<li></li >
<li> </li>
<li></li >
</ul>
</div >
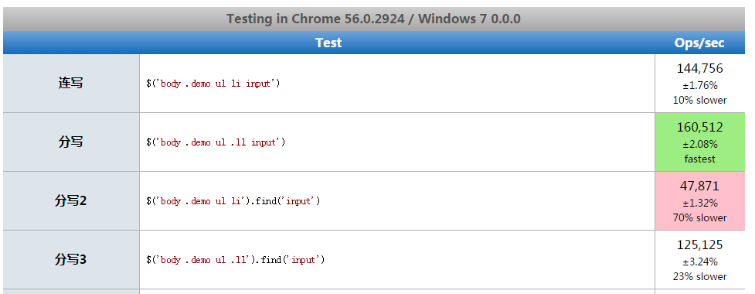
第一组测试:连续书写、分段书写、使用find方式比较: https://jsperf.com/jquerywrite/1


和Arron测试的结果不同:aaron的测试结果在点击这里查看
可见Arron测试的jquery版本比较低,没有做开头是id选择器的优化。高版本就没有这个问题了。
我根据jQuery的源码推测一下:
分两种情况:
第一种,支持querySelectorAll下
$('#demo li:nth-child(1)') 方式Sizzle会先直接使用querySelectorAll查询'#demo li:nth-child(1)'
$('li:nth-child(1)','#demo')方式先$('#demo')得到结果作为context进入Sizzle使用querySelectorAll查询'li:nth-child(1)'。比第一种多走一步
$('.demo').find('li:nth-child(1)')方式和$('li:nth-child(1)','#demo')类似,效率应该差不多。
第二种,不支持querySelectorAll的情况下(我用IE7测试),用自己的测试方法(jsperf有兼容问题)
测试方法(定时10秒看执行次数)
<script type="text/javascript">
var dateStart,dateEnd, count = 0; //这是其中一个案例
function testID(){
dateStart = new Date();
count = 0; while(1){
dateEnd = new Date();
if(dateEnd - dateStart > 10000){
console.log('#demo li:nth-child(1) run count = ' + count);
break;
} $('#demo li:nth-child(1)');
count++;
}
}
日志: #demo li:nth-child(1) run count = 51781
日志: li:nth-child(1),#demo run count = 51982
日志: (#demo).find(li:nth-child(1)) run count = 52831
他们之间没有太大的差距。分析Sizzle流程可知,三种方式都是先计算出"#demo",然后匹配" li:nth-child(1)"。
所以按照分析,ID选择器放入查询语句中,浏览器支持的伪类查询效率远远高于jQuery自定义的伪类(尽量使用浏览器支持的查询语句)
再测试一组数据


几乎没有差别。

按照分析,一次查找比多次查找要快
所以按照分析,在现代浏览器(IE8+,chrome,fireforx)的这三种写法中连写是最快的。 究其原因是一次查找比多次查找要快。
第二组:CSS属性选择器、CSS伪类选择器比较

通过第一行和第三行看出属性选择器和伪类选择器执行效率差不多。但是jQuery自定义的伪类比较慢。
第三组:CSS约束

避免过度约束
第四组:CSS筛选伪类、避免筛选伪类

可见,jQuery自定义伪类是拖慢选择器效率的一大罪魁祸首
第五组: 快速缩小范围
<div id="demo" class='demo'>
<ul class="uu">
<li class="ll"><input type="checkbox" data="data"/></li>
<li></li >
<li> </li>
<li></li >
</ul>
<ul>
<li><input type="checkbox" data="data"/></li>
<li></li >
<li> </li>
<li></li >
</ul>
<ul>
<li><input type="checkbox" data="data"/></li>
<li></li >
<li> </li>
<li></li >
</ul>
</div >
查询第一个li标签下的input
解析:li标签的个数明显class.ll对应的标签多。所以.ll缩小范围更明显。所以第二行的执行次数比第一行多。第四行执行次数明显比第三行多。

解析:ul标签数量比.uu对应的标签数量多,所以第二行执行次数比第一行多。
可见,快速缩小查找范围(合理利用从右到左查询原理)能加快查找速度
总结:
- 连续方式书写jQuery更快
- 多用#ID选择器,总是以#ID选择器打头缩小选择范围
- 让选择器最右边的选择器具有特征性,如“#id input”可换成“#id input[type=’text’]”。因为比较是从右往左开始的,右边的选择器能够确定唯一结果更好。
- 尽量使用高级浏览器原生css选择器替换jQuery自定义伪类。
- 避免过度约束和冗余约束。
- 使用亲密关系的关系选择器“>”和“+”,避免使用“ ”和“~”,可以避免递归匹配。
- 尽量避免使用伪类。
- 缓存jQuery对象,然后在缓存对象上使用查找。
如果觉得本文还有那么一点点作用,请顶一下。
jQuery-1.9.1源码分析系列(三) Sizzle选择器引擎——总结与性能分析的更多相关文章
- Java并发包源码学习系列:阻塞队列BlockingQueue及实现原理分析
目录 本篇要点 什么是阻塞队列 阻塞队列提供的方法 阻塞队列的七种实现 TransferQueue和BlockingQueue的区别 1.ArrayBlockingQueue 2.LinkedBloc ...
- Alamofire源码解读系列(三)之通知处理(Notification)
本篇讲解swift中通知的用法 前言 通知作为传递事件和数据的载体,在使用中是不受限制的.由于忘记移除某个通知的监听,会造成很多潜在的问题,这些问题在测试中是很难被发现的.但这不是我们这篇文章探讨的主 ...
- SpringBoot源码解读系列三——引导注解
我们再来看下SpringBoot应用的启动类: 查看代码 import org.springframework.boot.SpringApplication; import org.springfra ...
- Spring源码由浅入深系列三 refresh
spring中的refresh是一个相当重要的方法.它完成IOC的第一个阶段,将xml中的bean转化为beanDefinition.详细说明如上图所示. 在上图中,创建obtainFreshBean ...
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
本篇讲解参数编码的内容 前言 我们在开发中发的每一个请求都是通过URLRequest来进行封装的,可以通过一个URL生成URLRequest.那么如果我有一个参数字典,这个参数字典又是如何从客户端传递 ...
- Alamofire源码解读系列(六)之Task代理(TaskDelegate)
本篇介绍Task代理(TaskDelegate.swift) 前言 我相信可能有80%的同学使用AFNetworking或者Alamofire处理网络事件,并且这两个框架都提供了丰富的功能,我也相信很 ...
- Alamofire源码解读系列(八)之安全策略(ServerTrustPolicy)
本篇主要讲解Alamofire中安全验证代码 前言 作为开发人员,理解HTTPS的原理和应用算是一项基本技能.HTTPS目前来说是非常安全的,但仍然有大量的公司还在使用HTTP.其实HTTPS也并不是 ...
- Alamofire源码解读系列(十一)之多表单(MultipartFormData)
本篇讲解跟上传数据相关的多表单 前言 我相信应该有不少的开发者不明白多表单是怎么一回事,然而事实上,多表单确实很简单.试想一下,如果有多个不同类型的文件(png/txt/mp3/pdf等等)需要上传给 ...
- Alamofire源码解读系列(十二)之时间轴(Timeline)
本篇带来Alamofire中关于Timeline的一些思路 前言 Timeline翻译后的意思是时间轴,可以表示一个事件从开始到结束的时间节点.时间轴的概念能够应用在很多地方,比如说微博的主页就是一个 ...
随机推荐
- GIT和SVN之间的区别及基本操作对比
1)GIT是分布式的,SVN不是: 这是GIT和其它非分布式的版本控制系统,例如 SVN,CVS等,最核心的区别.如果你能理解这个概念,那么你就已经上手一半了.需要做一点声明,GIT并不是目前第一个或 ...
- shell简单用法笔记(shell中数值运算)二
shell中变量值,如果不手动指定类型,默认都是字符串类型: 例如: a= b= c=$a+#b echo $c 结果会输出:123+456 shell中,如果要进行数值运算,可以通过一下方法: 方法 ...
- 安装jdk
检查已安装jdk,如果有,先删除 rpm -qa|grep java rpm -e --nodeps filename 从oracle官方网站下载jdk安装包:jdk-8u111-linux-x64. ...
- Mono 3.2 上跑NUnit测试
NUnit是一款堪与JUnit齐名的开源的回归测试框架,供.net开发人员做单元测试之用,可以从www.nunit.org网站上免费获得,最新版本是2.5.Mono 3.2 源码安装的,在/usr/b ...
- React源码剖析系列 - 生命周期的管理艺术
目前,前端领域中 React 势头正盛,很少能够深入剖析内部实现机制和原理.本系列文章希望通过剖析 React 源码,理解其内部的实现原理,知其然更要知其所以然. 对于 React,其组件生命周期(C ...
- 记录Office Add-in开发经验
原创文章转载请注明出处:@协思, http://zeeman.cnblogs.com 得益于微软系强大的共通能力和Visual Studio的开发支持,做Office插件不是什么难事.一点经验记录如下 ...
- ASP.NET MVC 5 - 视图
在本节中,你要去修改HelloWorldController类,使用视图模板文件,在干净利索地封装的过程中:客户端浏览器生成HTML. 您将创建一个视图模板文件,其中使用了ASP.NET MVC 3所 ...
- 【Paddy】如何将物理表分割成动态数据表与静态数据表
前言 一般来说,物理表的增.删.改.查都受到数据量的制约,进而影响了性能. 很多情况下,你所负责的业务关键表中,每日变动的数据库与不变动的数据量比较,相差非常大. 这里我们将变动的数据称为动态数据,不 ...
- 使用WCF的Trace与Message Log功能
原创地址:http://www.cnblogs.com/jfzhu/p/4030008.html 转载请注明出处 前面介绍过如何创建一个WCF Service http://www.cnblo ...
- Mint linux 自定义上下文菜单实现ZIP压缩文件无乱码解压
1. 前提条件 我的Mint Linux 是Thunar文件管理器(默认的). 2. 配置自定义动作 打开Thunar文件管理器,点击菜单“编辑”=>“配置自定义动作”.点击“+”添加一个新的. ...