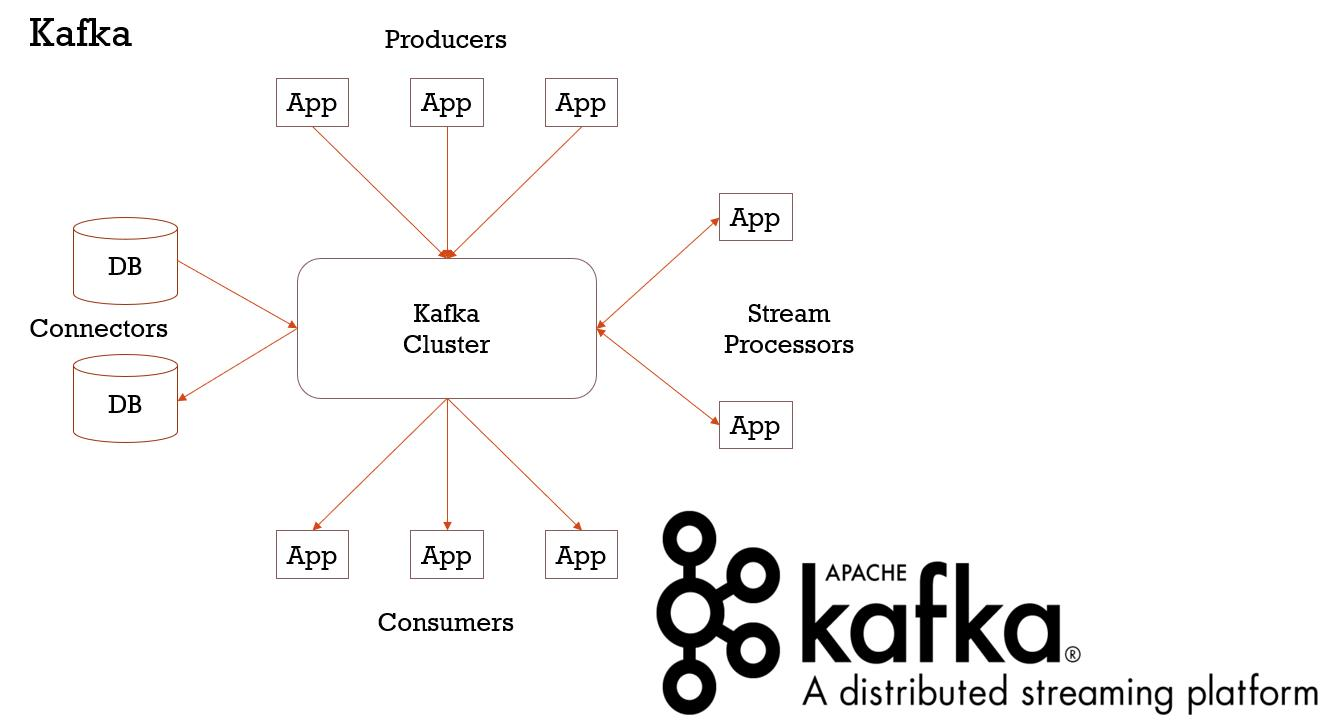
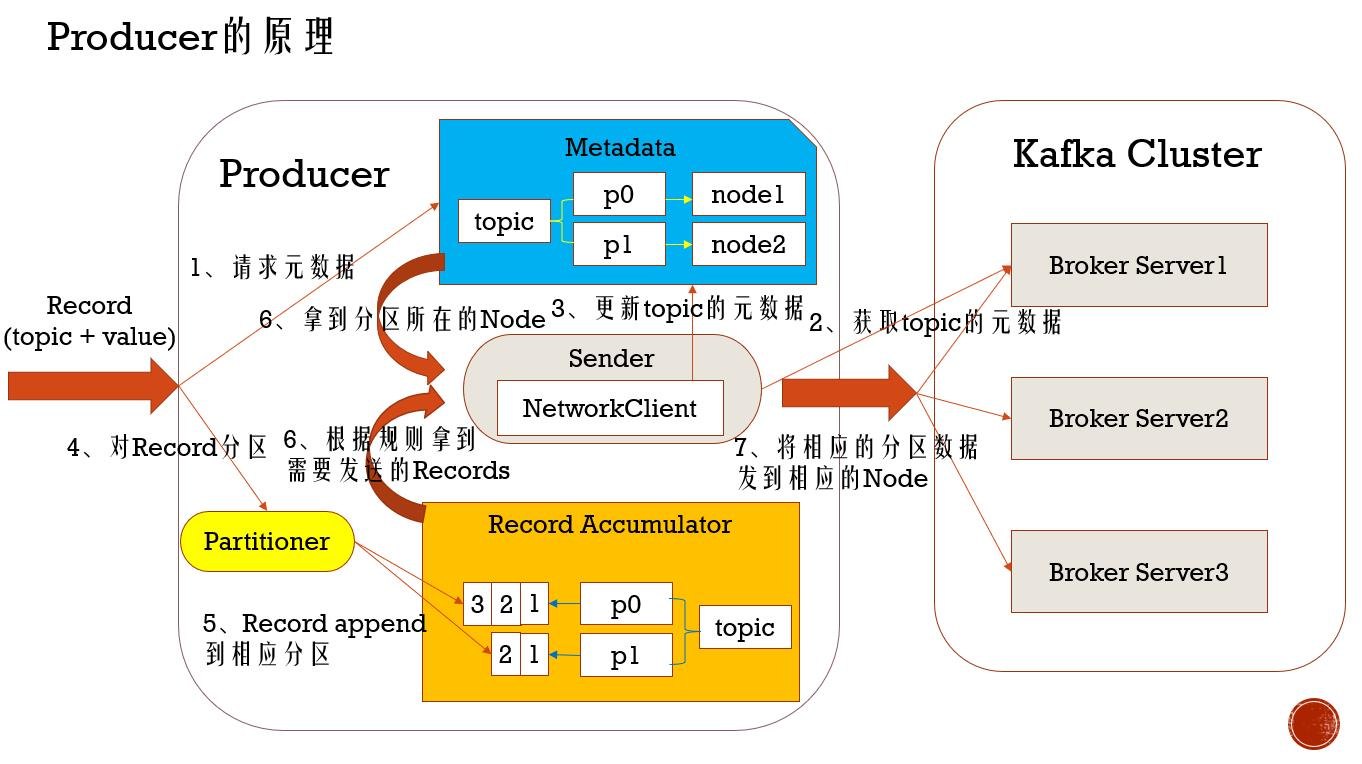
Kafaka 总结

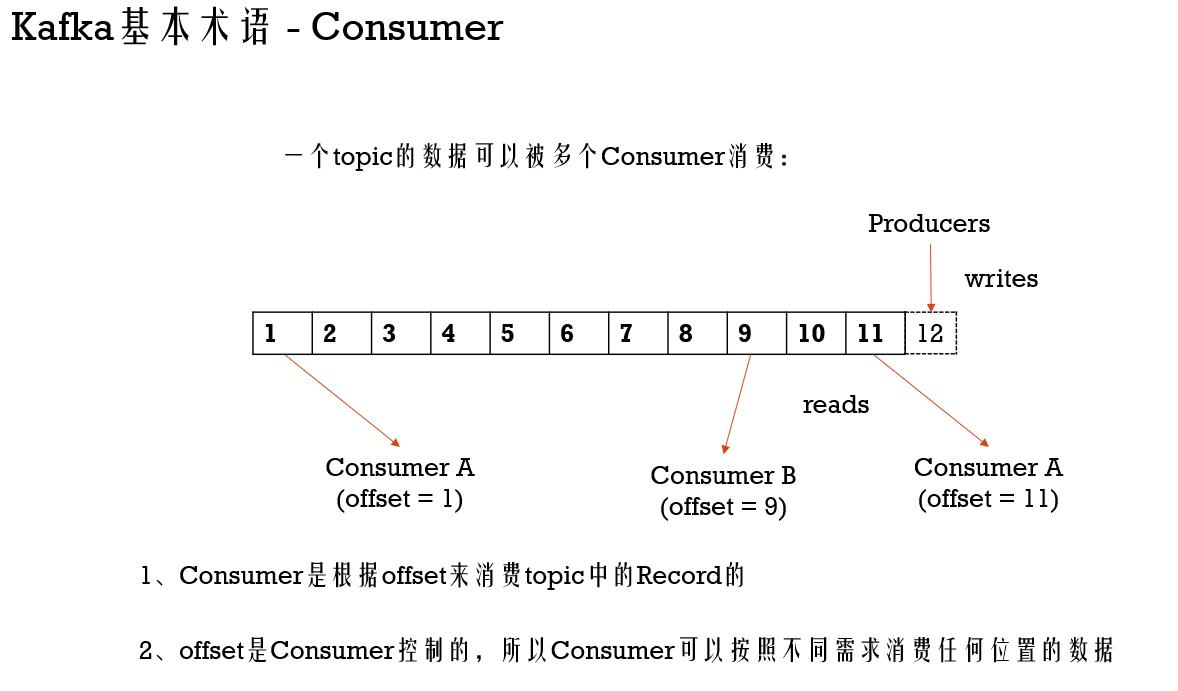
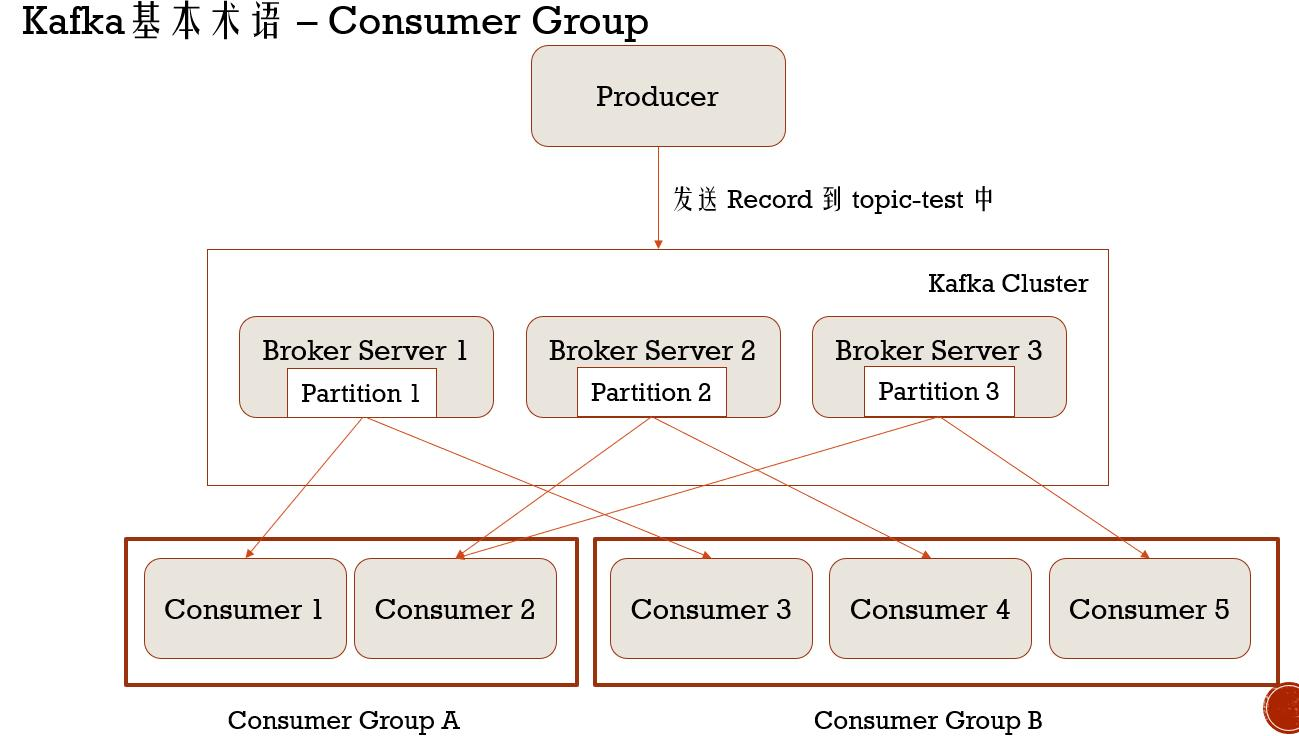
Kafka基本术语 - Consumer

import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; /**
* Created by tangweiqun on 2017/12/23.
*/
public class SimpleComsumerGroup1 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "group1");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test-group"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s, topic = %s, partition = %d",
record.offset(), record.key(), record.value(), record.topic(), record.partition());
System.out.println();
}
}
}
}
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; /**
* Created by tangweiqun on 2017/12/23.
*/
public class SimpleComsumerGroup2 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "group2");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test-group"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s, topic = %s, partition = %d",
record.offset(), record.key(), record.value(), record.topic(), record.partition());
System.out.println();
}
}
}
}
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class SimpleProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("batch.size", "10"); Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("test-group",
Integer.toString(i), Integer.toString(i)));
} producer.close();
}
}
Kafaka 总结的更多相关文章
- centos单机安装zookeeper+kafaka
环境如下: CentOS-7-x86_64zookeeper-3.4.11kafka_2.12-1.1.0 一.zookeeper下载与安装1)下载zookeeper [root@localhost ...
- Kafaka高可用集群环境搭建
zk集群环境搭建:https://www.cnblogs.com/toov5/p/9897868.html 三台主机每台的Java版本1.8 下面kafka集群的搭建: 3台虚拟机均进行以下操作: ...
- spring cloud 2.x版本 Spring Cloud Stream消息驱动组件基础教程(kafaka篇)
本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka-ri ...
- kafka?kafaka! kafka...
kafka?kafaka! Kafka... kafka是什么? 答:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅 ...
- windows环境下配置Kafaka
一.安装Zookeeper(Kafaka依赖于zookeeper进行服务注册和管理) 1. 1 下载zookeeper:http://mirror.bit.edu.cn/apache/zookee ...
- kafaka quickstart
http://kafka.apache.org/ http://kafka.apache.org/downloads cd /root/kafuka/kafka_2.12-0.11.0.0 nohup ...
- kafka 分区和副本以及kafaka 执行流程,以及消息的高可用
1.Kafka概览 Apache下的项目Kafka(卡夫卡)是一个分布式流处理平台,它的流行是因为卡夫卡系统的设计和操作简单,能充分利用磁盘的顺序读写特性.kafka每秒钟能有百万条消息的吞吐量,因此 ...
- kafaka可视化工具
许多中间件系统都提供了良好的可视化系统.MySQL有workbench,navcat,php版的mysqladmin等可视化程序.Redis.MongoDB也有开源的可视化程序.只要官方提供了探索数据 ...
- kafaka学习
创建一个topic: [root@hdp1 bin]# ./kafka-topics. --replication-factor --partitions --topic justin Created ...
- kafaka安装
wget https://mirrors.cnnic.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz 解压 Tar -xvf kafka_2.11-2.0.0.t ...
随机推荐
- SpringBoot集成Mybatis实现多表查询的两种方式(基于xml)
下面将在用户和账户进行一对一查询的基础上进行介绍SpringBoot集成Mybatis实现多表查询的基于xml的两种方式. 首先我们先创建两个数据库表,分别是user用户表和account账户表 ...
- grpc Unary模式下客户端创建insecure channel的主要流程
(原创)C/C/1.25.0-dev grpc-c/8.0.0, 使用的例子是自带的例子GreeterClient grpc Unary模式下客户端创建insecure channel的主要流程 gr ...
- day19——包、logging日志
day19 包 文件夹下具有______init______.py文件就是一个包 方法 import 包.包.包 from 包.包.包 import 模块 需要在______init______.py ...
- ZYNQ笔记(0):C语言基础知识复习
ZYNQ的SDK是用C语言进行开发的,C语言可以说是当今理工类大学生的必备技能.我本科学C语言时就是对付考试而已,导致现在学ZYNQ是一脸懵逼.现在特开一帖,整理一下C语言的基础知识. 一.定义 1. ...
- U9期间在手量控制
1.路径 库存管理->参数控制 2.设置节点 期间在手量控制时机 :单据实时控制.日关账控制.不控制 3.实现效果
- Windows 上的应用程序在运行期间可以给自己改名(可以做 OTA 自我更新)
原文:Windows 上的应用程序在运行期间可以给自己改名(可以做 OTA 自我更新) 程序如何自己更新自己呢?你可能会想到启动一个新的程序或者脚本来更新自己.然而 Windows 操作系统允许一个应 ...
- String.Join函数
string[] str1 = { "abc", "bcd", "cde", "efg" }; string str2 ...
- Windows 创建 Redis 和 zookeeper 系统服务
Redis 启动 Redis start cmd /k "cd/d c:\Redis-x64-3.2.100\&&echo start Redis &&red ...
- 复杂dic的文件化存储和读取问题
今天遇到一个难题.整出一个复杂的dic,里面不仅维度多,还含有numpy.array.超级复杂.过程中希望能够存储一下,万一服务器停了呢?万一断电了呢? 结果存好存,取出来可就不是那样了.网上搜索了很 ...
- Python进阶----反射(四个方法),函数vs方法(模块types 与 instance()方法校验 ),双下方法的研究
Python进阶----反射(四个方法),函数vs方法(模块types 与 instance()方法校验 ),双下方法的研究 一丶反射 什么是反射: 反射的概念是由Smith在1982年首次提出的 ...