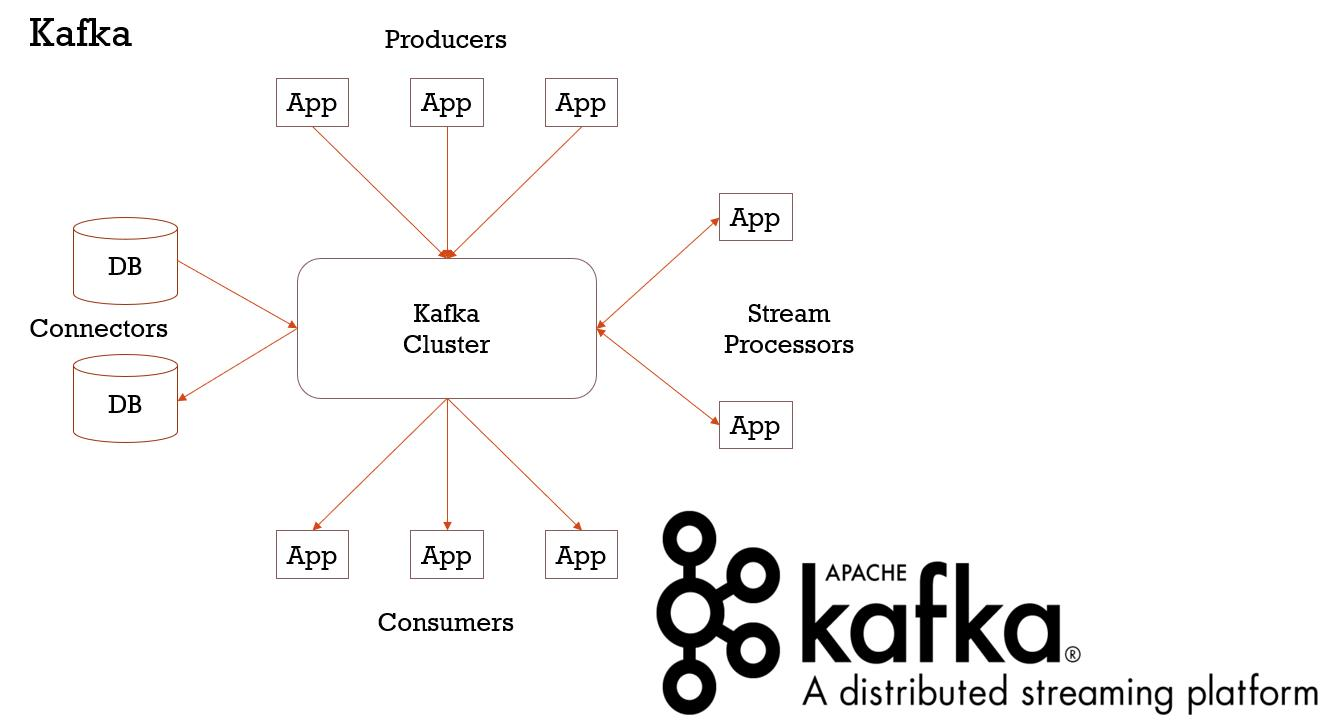
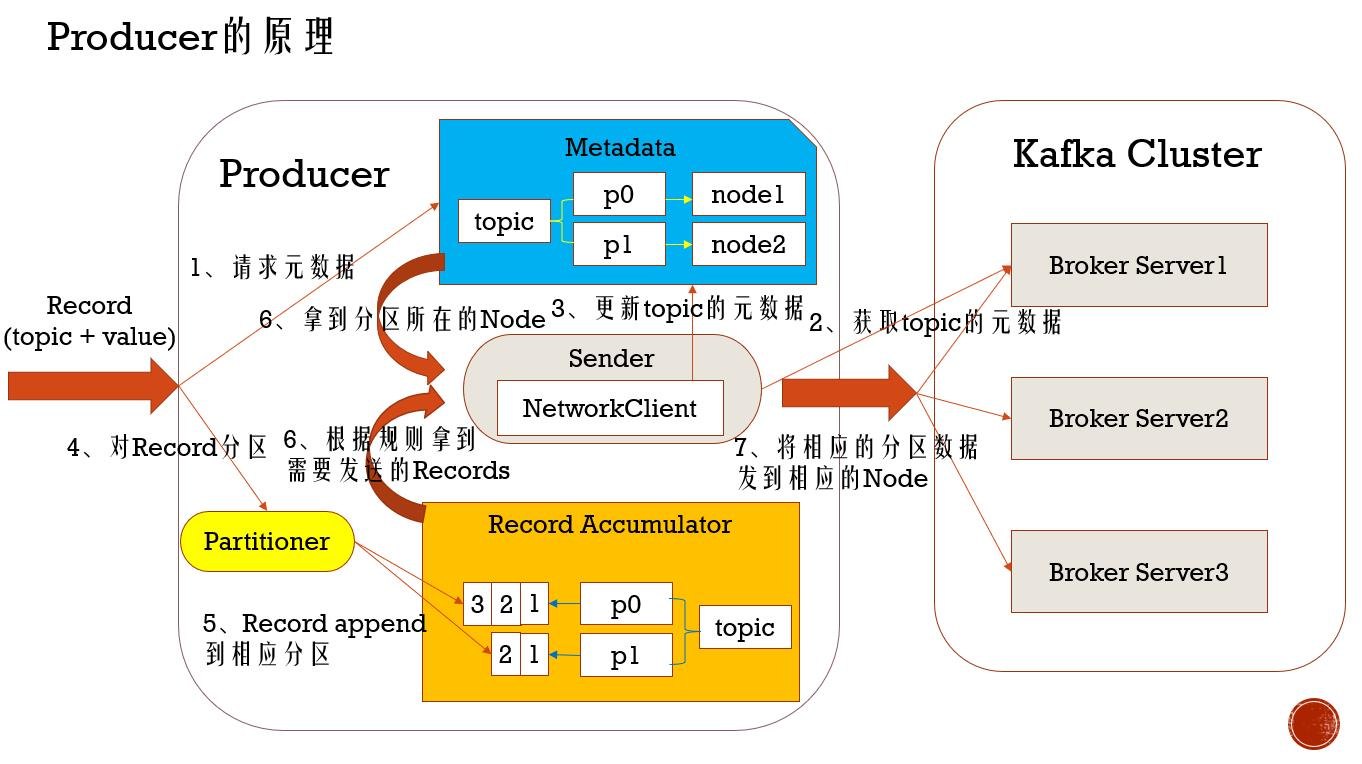
Kafaka 总结

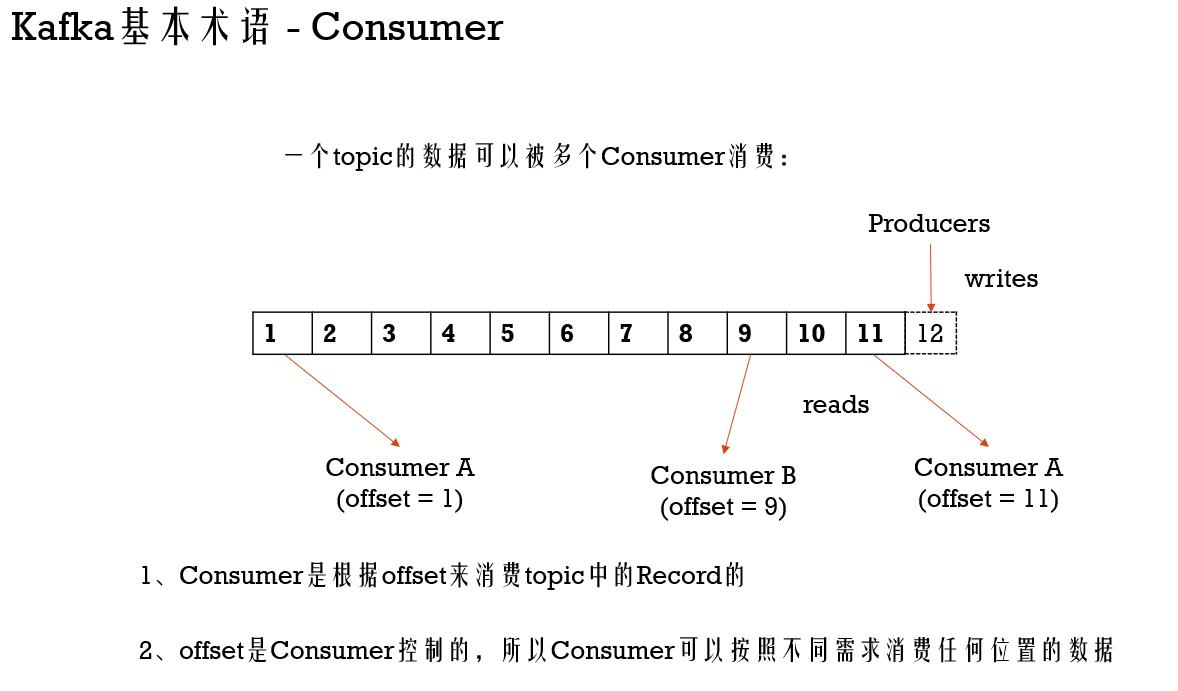
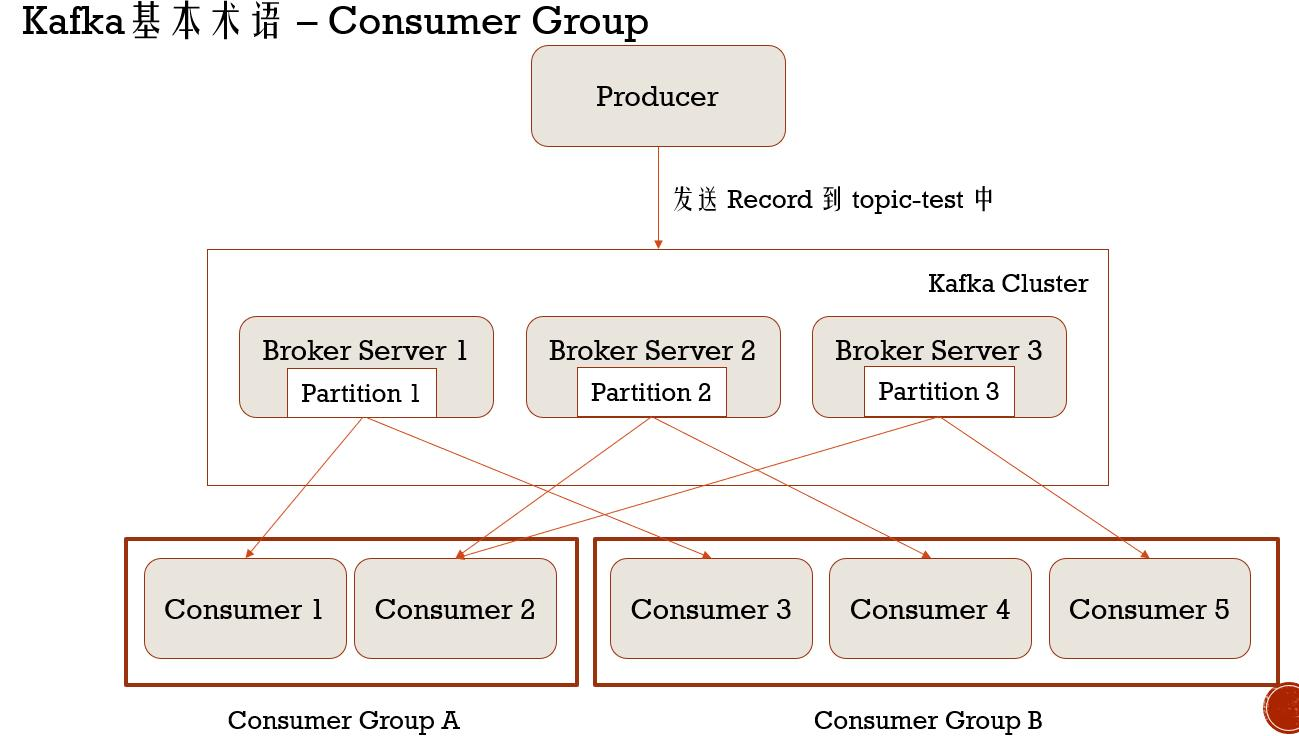
Kafka基本术语 - Consumer

import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; /**
* Created by tangweiqun on 2017/12/23.
*/
public class SimpleComsumerGroup1 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "group1");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test-group"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s, topic = %s, partition = %d",
record.offset(), record.key(), record.value(), record.topic(), record.partition());
System.out.println();
}
}
}
}
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays;
import java.util.Properties; /**
* Created by tangweiqun on 2017/12/23.
*/
public class SimpleComsumerGroup2 {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "group2");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("test-group"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s, topic = %s, partition = %d",
record.offset(), record.key(), record.value(), record.topic(), record.partition());
System.out.println();
}
}
}
}
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class SimpleProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("batch.size", "10"); Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("test-group",
Integer.toString(i), Integer.toString(i)));
} producer.close();
}
}
Kafaka 总结的更多相关文章
- centos单机安装zookeeper+kafaka
环境如下: CentOS-7-x86_64zookeeper-3.4.11kafka_2.12-1.1.0 一.zookeeper下载与安装1)下载zookeeper [root@localhost ...
- Kafaka高可用集群环境搭建
zk集群环境搭建:https://www.cnblogs.com/toov5/p/9897868.html 三台主机每台的Java版本1.8 下面kafka集群的搭建: 3台虚拟机均进行以下操作: ...
- spring cloud 2.x版本 Spring Cloud Stream消息驱动组件基础教程(kafaka篇)
本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka-ri ...
- kafka?kafaka! kafka...
kafka?kafaka! Kafka... kafka是什么? 答:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅 ...
- windows环境下配置Kafaka
一.安装Zookeeper(Kafaka依赖于zookeeper进行服务注册和管理) 1. 1 下载zookeeper:http://mirror.bit.edu.cn/apache/zookee ...
- kafaka quickstart
http://kafka.apache.org/ http://kafka.apache.org/downloads cd /root/kafuka/kafka_2.12-0.11.0.0 nohup ...
- kafka 分区和副本以及kafaka 执行流程,以及消息的高可用
1.Kafka概览 Apache下的项目Kafka(卡夫卡)是一个分布式流处理平台,它的流行是因为卡夫卡系统的设计和操作简单,能充分利用磁盘的顺序读写特性.kafka每秒钟能有百万条消息的吞吐量,因此 ...
- kafaka可视化工具
许多中间件系统都提供了良好的可视化系统.MySQL有workbench,navcat,php版的mysqladmin等可视化程序.Redis.MongoDB也有开源的可视化程序.只要官方提供了探索数据 ...
- kafaka学习
创建一个topic: [root@hdp1 bin]# ./kafka-topics. --replication-factor --partitions --topic justin Created ...
- kafaka安装
wget https://mirrors.cnnic.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz 解压 Tar -xvf kafka_2.11-2.0.0.t ...
随机推荐
- 【记录】【windows】下查看端口是否被占用并杀死该进程
查看端口是否被占用 netstat -aon|findstr "端口号" 比如 netstat -aon|findstr "6340" 杀死该进程 taskki ...
- PHP设计模式 - 状态模式
状态模式当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类.状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况.把状态的判断逻辑转移到表示不同状态的一系列类中,可以 ...
- Google Colab——零成本玩转深度学习
前言 最近在学深度学习HyperLPR项目时,由于一直没有比较合适的设备训练深度学习的模型,所以在网上想找到提供模型训练,经过一段时间的搜索,最终发现了一个谷歌的产品--Google Colabora ...
- 倾斜动画(SkewTransform)
Silverlight中的倾斜变化动画(SkewTransform)能够实现对象元素的水平.垂直方向的倾斜变化动画效果.我们现实生活中的倾斜变化效果是非常常见的,比如翻书的纸张效果,关门开门的时候门缝 ...
- ThreadLocal简解
ThreadLocal特点 ThreadLocal实现了线程间数据隔离,ThreadLocal的实例代表了一个线程局部的变量,每条线程都只能看到自己的值,并不会意识到其它的线程中也存在该变量.简单来说 ...
- WAS更新web.xml配置文件不生效的问题
问题及原因分析: 之前修复漏洞时,写了个过滤器配置在web.xml中,但是部署到服务器并重启后,重新扫描漏洞,还是没有解决对应问题.在确定了这种修复方案是切实可行之后分析,可能是配置的web.xml未 ...
- 一个工作13年的SAP开发人员的回忆:电子科技大学2000级新生入学指南
让我们跟着Jerry的文章,一起回到本世纪初那个单纯美好的年代. 2000年9月,Jerry告别了自己的高中时代,进入到自己心目中的电子游戏大学,开始了四年的本科生活.每个新生,都拿到了这样一本薄薄的 ...
- 【索引】Oracle之不可见索引和虚拟索引的比对
[索引]Oracle之不可见索引和虚拟索引的比对 Oracle之不可见索引 :http://blog.itpub.net/26736162/viewspace-2124044/ Oracle之虚 ...
- map put相同的key
Map添加相同的key 2018年09月09日 10:37:12 Airport_Le 阅读数:6479 HashMap是的key是不能重复的,如果有相同的key,最后一个key对应的value会 ...
- php操作mysql,1分钟内插入百万数据
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/qq_33862644/article/d ...