Empirical Analysis of Beam Search Performance Degradation in Neural Sequence Models
Empirical Analysis of Beam Search Performance Degradation in Neural Sequence Models
2019-06-13 10:28:44
Paper: [abs] [Download PDF][Supplementary PDF] Eldan Cohen, Christopher Beck ; PMLR 97:1290-1299
1. Background and Motivation:
Beam search 是一种常用在时序任务中解码算法,如:NLP 中的语言翻译,Image Captioning 等。不同于一般的贪婪搜索策略,该算法会始终维持相同的搜索宽度,最终会输出该宽度的多个搜索结果。就是因为这种天然的优势,该算法被广泛的应用于各种时序任务中。但是,大量的研究表明,beam search 存在如下的不足:“随着 width” 的增加,最终的效果也会不断降低,即:增加 width,不能提升效果,该算法只能在特定的较小的 width 条件下,才会 work 的很好。
针对上述问题,作者在本文中在多个任务上进行了大量的实验,来研究这个问题:machine translation,abstract summarization, and image captioning。作者在这些实验的基础上,提出了一种可解释的模型,该模型基于 search discrepancies(搜索差异性) 的概念,然后基于该差异性的分布进行了经验性的研究。主要贡献如下:
1). 本文表明增加 beam width 将会导致 solution 在早期有较大的不一致性 (discrepancies);这些序列通常会有较低的评价得分,从而导致最终的性能衰减。
2). 本文所提出的 explanatory model generalizes the previouly observed "copies" and predictions that repeat training set targets and accounts for more of the degraded predictions.
3). 本文表明对 beam search 进行修改,使其不考虑 large search discrepancies 可以有效的缓解性能衰减。
2. Neural Sequence Models:

在神经序列模型中,通过充分的搜索以求得一个全局最优序列几乎是不可能的。贪心算法会在每一个时刻,选择一个最优的候选,使得序列局部最优,但是可能最终得到的仅仅是一个局部次优的序列。Beam search 将每一个时刻的可能序列宽度拓展为 B,这个 B 称为 beam width。正式的来说,beam search candidate 通过如下的方式进行更新:
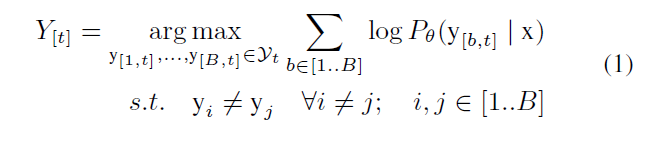
本文将 search discrepancy 定义为:extending a partial sequence with a token that is not the most probable one. 正式的来说,一个序列 y 在时刻 t 有一个 search discrepancy,如果其满足如下的条件:
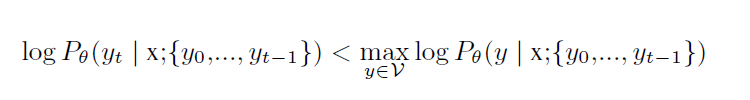
我们将最可能的 token 和 选择的 token 的差异性,取 log,记为:
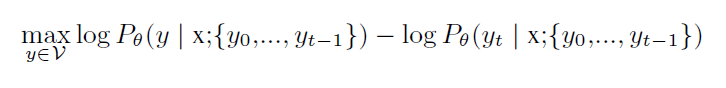
为了说明该 discrepancy gap 是如何计算的,我们给出了上图1。具有最高条件概率候选的 discrepancy gap 为 0,其他候选之间的 gap 就是其 log 概率的距离。
3. Discrepancy-Constrained Beam Search:
本文评价了两种类似 trick 的方法来约束 beam search,都是考虑到较大的搜索差异。
Discrepancy Gap:
给定阈值 M,我们修改 beam search 来仅仅考虑搜索差异小于等于 M 的候选。正式的来说,我们修改公式 1,使其包含这一约束:
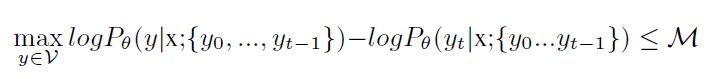
Beam Candidate Rank:
给定阈值 N,我们修改 $y_t$ 使其在每一个 beam 中仅仅包含 top N one-token extensions。注意到,beam search 仍然保持 top B candidates,然而在每一个 beam 中,其不会考虑超过 N 的候选。
4. Experiments:
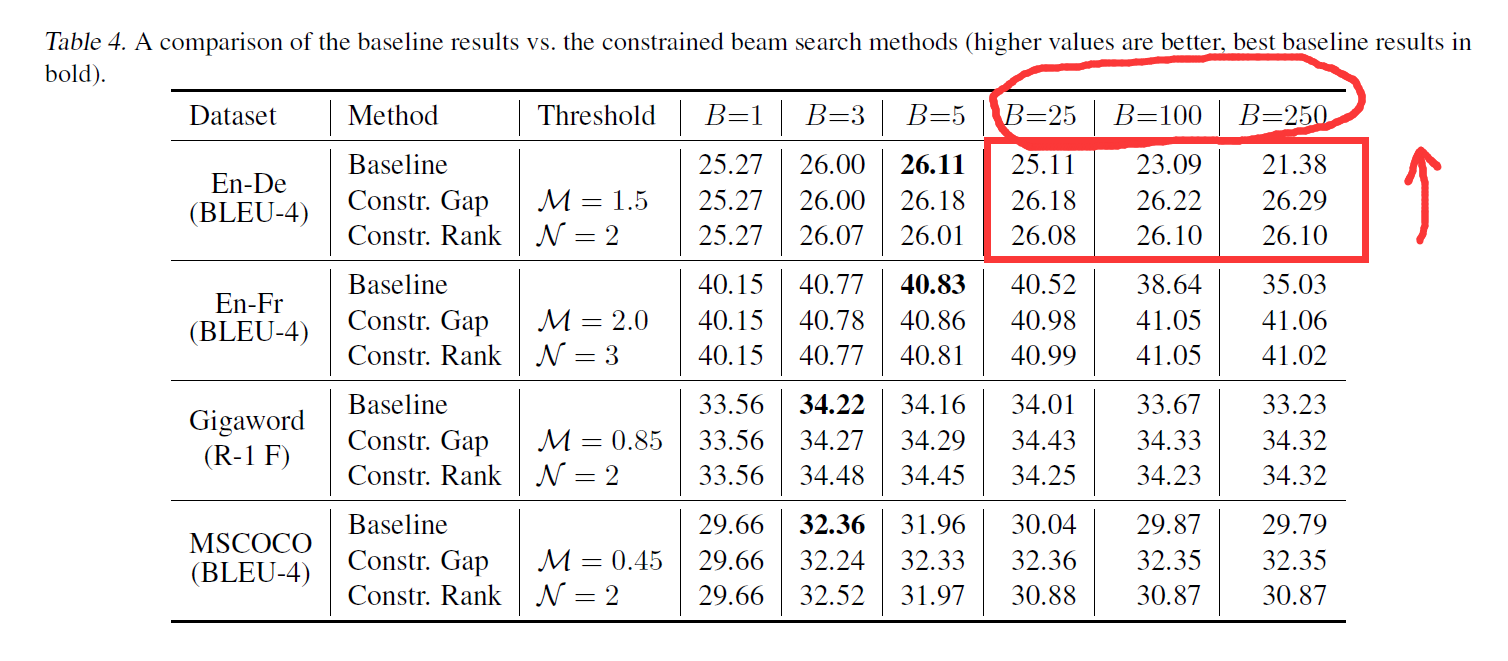
作者的实验表明,当考虑到作者提到的不一致性约束时,在增加 beam width 的时候,就不存在精度下降的问题了。但是这个表格貌似也反映了,beam width 设置的太大,有些情况下,并不会明显提升精度,反而有可能降低。到底该不该设置较大的 beam width,还是应该调调参数,试试才知道哇。
==
Empirical Analysis of Beam Search Performance Degradation in Neural Sequence Models的更多相关文章
- Beam Search(集束搜索/束搜索)
找遍百度也没有找到关于Beam Search的详细解释,只有一些比较泛泛的讲解,于是有了这篇博文. 首先给出wiki地址:http://en.wikipedia.org/wiki/Beam_searc ...
- 关于Beam Search
Wiki定义:In computer science, beam search is a heuristic search algorithm that explores a graph by exp ...
- [0.0]Analysis of Baidu search engine
Rencently, my two teammates and I is doing a project, a simplified Chinese search engine for childre ...
- 【NLP】选择目标序列:贪心搜索和Beam search
构建seq2seq模型,并训练完成后,我们只要将源句子输入进训练好的模型,执行一次前向传播就能得到目标句子,但是值得注意的是: seq2seq模型的decoder部分实际上相当于一个语言模型,相比于R ...
- 集束搜索beam search和贪心搜索greedy search
贪心搜索(greedy search) 贪心搜索最为简单,直接选择每个输出的最大概率,直到出现终结符或最大句子长度. 集束搜索(beam search) 集束搜索可以认为是维特比算法的贪心形式,在维特 ...
- 关于 Image Caption 中测试时用到的 beam search算法
关于beam search 之前组会中没讲清楚的 beam search,这里给一个案例来说明这种搜索算法. 在 Image Caption的测试阶段,为了得到输出的语句,一般会选用两种搜索方式,一种 ...
- 实现nlp文本生成中的beam search解码器
自然语言处理任务,比如caption generation(图片描述文本生成).机器翻译中,都需要进行词或者字符序列的生成.常见于seq2seq模型或者RNNLM模型中. 这篇博文主要介绍文本生成解码 ...
- Beam Search
Q: 什么是Beam Search? 它在NLP中的什么场景里会⽤到? 传统的广度优先策略能够找到最优的路径,但是在搜索空间非常大的情况下,内存占用是指数级增长,很容易造成内存溢出,因此提出了beam ...
- beam search 和 greedy search
贪心搜索(greedy search): 贪心搜索最为简单,直接选择每个输出的最大概率,直到出现终结符或最大句子长度. 集束搜索(beam search): 集束搜索可以认为是维特比算法的贪心形式,在 ...
随机推荐
- python+java全栈工程师 转 向前端的路
python的优点 简单 简单 简单 我目前在公司用python 1. 增加odoo的各种业务,成本核算.自动跑单.自动备份数据库之类的 ----odoo是国外大佬做的一个开源erp 用的python ...
- Windows安装MySQL5.7教程
导读: 我们日常学习可能会需要在本地安装MySQL服务,也遇到过小伙伴探讨关于Windows系统安装MySQL的问题.在这里建议大家安装MySQL5.7版本,当然想尝试8.0版本的同学也可以参考安装. ...
- Oracle12C本地用户的创建和登录
1.查看sysdba下所有PDB以及服务名 select name,pdb from v$services; 2.根据PDB信息修改tnsnames.ora 3.修改listener.ora(网上相关 ...
- Python包模块化调用方式详解
Python包模块化调用方式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一般来说,编程语言中,库.包.模块是同一种概念,是代码组织方式. Python中只有一种模块对象类型 ...
- Linux文本编译工具VIM详解
Linux文本编译工具VIM详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.VIM概述 1>.vim简介 >.vi: 全称Visual editor,即文本编辑 ...
- danci2
composite 英 ['kɒmpəzɪt] 美 [kɑm'pɑzɪt] n. 复合材料:合成物:菊科 adj. 复合的:合成的:菊科的 vt. 使合成:使混合 a composite of 网络释 ...
- Linux——自定义服务命令
前言 这个写部署禅道的时候包含了这个内容,但是今天弄的时候突然忘记了,所以还是重新写下. 步骤 有的同学可能会不知道一些系统自带的目录是什么意思,所以我这里就拆分下,不直接创建 进入到系统服务目录 c ...
- 深入理解JVM内存分配和常量池
一.虚拟机的构成 虚拟结主要由运行时数据区.执行引擎.类加载器三者构成: 而我们所说的JVM内存模型指的就是运行时数据区,下面具体分析一下运行时数据区: 二.运行时数据区组成和各个区域的作用 我们看到 ...
- 分享STM32 FLASH 擦除(以及防止误擦除程序代码)、写入
编译环境:我用的是(Keil)MDK4.7.2 stm32库版本:我用的是3.5.0一.本文不对FLASH的基础知识做详细的介绍,不懂得地方请查阅有关资料. 对STM32 内部FLASH进行编程操 ...
- Time Frequency (T-F) Masking Technique
时频掩蔽技术. 掩蔽效应 声掩蔽(auditory masking)是指一个声音的听阈因另一个声音的存在而上升的现象.纯音被白噪声所掩蔽时,纯音听阈上升的分贝数,主要决定于以纯音频率为中心一个窄带噪声 ...