HTTP之缓存处理步骤
缓存的处理步骤
=================摘自《HTTP权威指南》=====================
现代的商业化代理缓存相当的复杂。这些缓存构建的非常有效,可以支持HTTP和其他一些技术的各种高级特性,但除了一些微妙的细节外,web缓存的基本工作原理大多很简单。对一条HTTP GET报文的基本缓存处理过程包括7个步骤(图7-11)
1、 接收—缓存从网络中读取抵达的请求报文;
2、 解析—缓存对报文进行解析,提取出URL和各种首部;
3、 查询—缓存查看是否有本地缓存可用,如果没有,就获取一份副本(并将其保存在本地);
4、 新鲜度检测—缓存查看已缓存的副本是否足够新鲜,如果不是,就询问服务器是否有任何更新;
5、 创建响应—缓存会用新的首部和已缓存的主体来构建一条响应报文;
6、 发送—缓存通过网络将响应回送给客户端;
7、 日志—缓存可选地创建一个日志文件条目来描述这个事务;

1、 第一步—接收
缓存检测到一条连接上的活动,读取输入数据。高性能的缓存会同时从多条输入连接上读取数据,在整条报文抵达之前开始对事务进行处理。
2、 第二部—解析
缓存将请求报文解析为片段,将首部的各个部分放入易于操作的数据结构中。这样缓存软件更容易处理首部字段并修改它们了。
3、 第三步—查找
缓存获取了URL,查找本地副本。本地副本可能存储在内存、本地磁盘,甚至附近的另一台计算机中。专业级的缓存会使用快速算法来确定本地缓存中是否有某个对象。如果本地没有这个文档,它可以根据情形和配置,到原始服务器或父代理中去取,或者返回一条错误信息。
已缓存对象中包含了服务器响应主体和原始服务器的响应首部,这样就会在缓存命中时返回正确的服务器首部。已缓存对象还包含了一些元数据(metadata),用来记录对象在缓存中停留了多长时间,以及它被用过了多少次等。
4、 第四步—新鲜度检测
HTTP通过缓存将服务器文档的副本保留一段时间。在这段时间里,都认为这份文档是“新鲜的”,缓存可以在不联系服务器的情况下,直接提供该文档。但一旦已缓存的副本停留的时间过长,超过了文档的新鲜度限制(freshness limit),就认为文档“过时”了,在提供该文档前,缓存要再次与服务器确认,以查看文档是否发生了变化。客户端发送给缓存的所有请求首部自身都可以强制缓存进行再验证,或者完全避免验证,这使得事情变得更加复杂了。
HTTP有一组非常复杂的新鲜度检测规则,缓存产品支持的大量配置选项,以及与非HTTP新鲜度标准进行互通的需要则使问题变得更严重了。
5、 第五步—创建响应
我们希望缓存的响应看起来就像来自原始服务器一样,缓存将已缓存的服务器响应首部作为响应首部的起点。然后缓存就对这些基础首部进行了修改和扩充。
缓存负责对这些首部进行改造,以便与客户端的要求相匹配。比如,服务器返回的可能是一条HTTP 1.0响应(甚至是HTTP 0.9响应),而客户端期待的是一条HTTP 1.1响应,在这种情况下,缓存必须对首部进行响应的转换。缓存还会向其中插入新鲜度信息(Cache-control、Age以及Expires首部),而且通常会包含一个Via首部来说明请求是由一个代理缓存提供的。
注意:缓存不应该调整Date首部。Date首部表示的是原始服务器最初产生这个对象的日期。
6、 第六步—发送
一旦响应首部准备好了,缓存就将响应回送给客户端。和所有代理服务器一样,代理缓存要管理与客户端之间的连接。高性能的缓存会尽力高效的发送数据,通常可以避免在本地缓存和网络I/O缓冲区之间进行文档内容的复制。
7、 日志
大多数缓存都会保存日志文件以及与缓存的使用有关的一些统计数据。每个缓存事务结束之后,缓存都会更新缓存命中和未命中数目的统计数据(以及其他相关的度量值)并将条目插入一个用来显示请求类型、URL和所发生时间的日志文件。
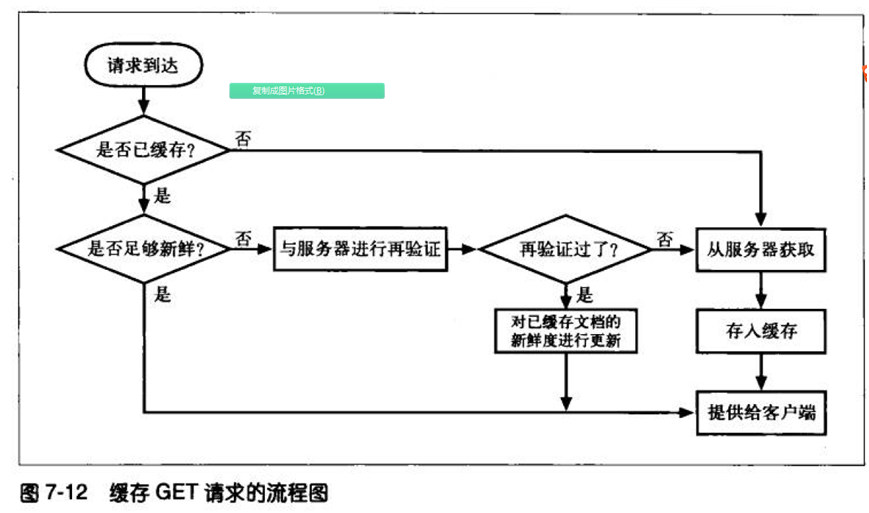
8、 缓存处理流程图
图7-12以简化的形式显示了缓存是如何处理请求以获取一个方法为GET的URL的。
HTTP之缓存处理步骤的更多相关文章
- Hibernate4.1.4配置二级缓存EHCache步骤
1.当然首先引入EHCache相关的jar包 这些包不需要另外下载,在Hibernate官方网站下载Hibernate4.1.7的压缩包(如:hibernate-release-4.1.7.Final ...
- [原创]java WEB学习笔记93:Hibernate学习之路---Hibernate 缓存介绍,缓存级别,使用二级缓存的情况,二级缓存的架构集合缓存,二级缓存的并发策略,实现步骤,集合缓存,查询缓存,时间戳缓存
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- 使用gulp解决RequireJS项目前端缓存问题(一)
1.前言 前端缓存一直是个令人头疼的问题,你有可能见过下面博客园首页的资源文件链接: 有没有发现文件名后面有一串不规则的东东,没错,这就是运用缓存机制,我们今天研究的就是这种东西. 先堵为快,猛戳链接 ...
- Hibernate ——二级缓存
一.Hibernate 二级缓存 1.Hibernate 二级缓存是 SessionFactory 级别的缓存. 2.二级缓存分为两类: (1)Hibernate内置二级缓存 (2)外置缓存,可配置的 ...
- [NHibernate]缓存(NHibernate.Caches)
系列文章 [Nhibernate]体系结构 [NHibernate]ISessionFactory配置 [NHibernate]持久化类(Persistent Classes) [NHibernate ...
- MyBatis学习--查询缓存
简介 以前在使用Hibernate的时候知道其有一级缓存和二级缓存,限制ORM框架的发展都是互相吸收其他框架的优点,在Hibernate中也有一级缓存和二级缓存,用于减轻数据压力,提高数据库性能. m ...
- hibernate的二级缓存
缓存(Cache): 计算机领域非常通用的概念.它介于应用程序和永久性数据存储源(如硬盘上的文件或者数据库)之间,其作用是降低应用程序直接读写永久性数据存储源的频率,从而提高应用的运行性能.缓存中的数 ...
- 深入了解Hibernate的缓存使用
Hibernate缓存 缓存是计算机领域的概念,它介于应用程序和永久性数据存储源(如在硬盘上的文件或者数据库)之间,其作用是降低应用程序 直接读写永久性数据存储源的频率,从而提高应用的运行性能.缓存中 ...
- NHibernate系列文章十:NHibernate对象二级缓存下
摘要 上一节对NHibernate二级缓存做了简单介绍,NHibernate二级缓存是由SessionFactory管理的,所有Session共享.这一节介绍二级缓存其他两个方面:二级缓存查询和二级缓 ...
随机推荐
- WPF 动态资源 DataContext="{DynamicResource studentListKey}" DisplayMemberPath="Name"
public class StudentList:ObservableCollection<Student> { public List<Student> studentLis ...
- OWIN,Katana,identity整体概述
在用asp.net identity的时候,发现很多概念不是很懂,特地去查资料了解了一些相关信息,现在做下笔记. 1.OWIN,OWIN是Open Web Server Interface for . ...
- ASP.NET MVC过滤器学习笔记
1.过滤器的两个特征 1.他是一种特性,可以引用到控制器类和Action方法上.比如下图 这里控制器类和action方法都引用了过滤器,这个过滤器是用来做授权的 2.特征继承自FilterAttrib ...
- 解决U盘不能分配空间(windows下操作)
亲测可行 1.WIN+R => cmd => diskpart命令进入工具. 2.使用LIST DISK查看所有磁盘,?提示所有命令. 3.SELECT DISK 1将磁盘聚焦到1号磁盘, ...
- java 线程之线程状态
Thread 类中的线程状态: public enum State { NEW,//新建 RUNNABLE,// 执行态 BLOCKED, //等待锁(在获取锁的池子里) WAITING,//等待状态 ...
- electron——ipcMain模块、ipcRenderer模块
ipcMain 从 主进程 到 渲染进程 的异步通信. ipcMain模块是EventEmitter类的一个实例. 当在主进程中使用时,它处理从渲染器进程(网页)发送出来的异步和同步信息. 从渲染器进 ...
- maven 学习---POM机制
POM 代表工程对象模型.它是使用 Maven 工作时的基本组建,是一个 xml 文件.它被放在工程根目录下,文件命名为 pom.xml. POM 包含了关于工程和各种配置细节的信息,Maven 使用 ...
- X264-应用工程
接下来的几篇博客中,具体学习下X264的实现过程. 源代码的分析参考了雷神的博客,感谢雷神!博客链接:https://blog.csdn.net/leixiaohua1020/article/deta ...
- 一条SELECT查询语句在数据库里执行时都经历了什么
每天都在跟 mysql 打交道,你知道执行一条简单的 select 语句,都经历了哪些过程吗? 首先,mysql 主要是由 server 层和存储层两部分构成的.server 层主要包括连接器.查询缓 ...
- Linux上安装git
Linux上安装git Git是一个开源的分布式版本控制系统,可以有效.高速的处理从很小到非常大的项目版本管理. 而国外的GitHub和国内的Coding都是项目的托管平台.但是在使用Git工具的时候 ...