28、对多次使用的RDD进行持久化或Checkpoint
一、图解
二、说明
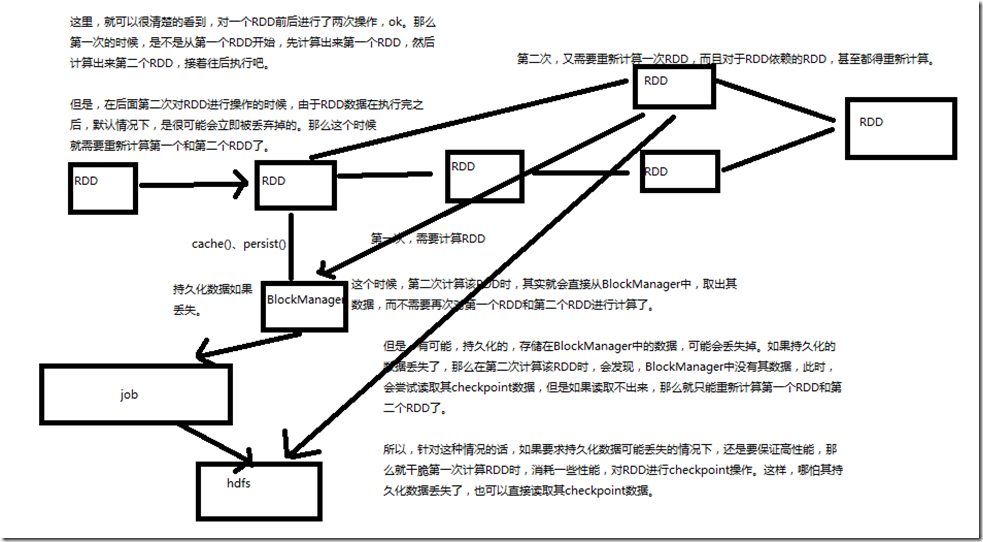
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作。那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算。 此外,如果要保证在RDD的持久化数据可能丢失的情况下,还要保证高性能,那么可以对RDD进行Checkpoint操作。 持久化,再checkpoint
这样,第一次,需要重新计算RDD; 第二次计算该RDD,其实会从BlockManager中,取出其数据,而不需要再次对第一个RDD和第二个RDD进行计算了; 但是,有可能持久化的数据,存储在BlockManager中的数据,可能会丢失掉。如果持久化的数据丢失了,那么在第二次计算该RDD时,会发现,BlockManager中没有数据
,此时,会尝试读取器checkpoint数据,如果读取不出来,只能重新计算第一个RDD和第二个RDD了; 所以,如果持久化数据可能丢失的情况下,还要保证高性能,那么就干脆第一次计算RDD时,消耗一些性能,对RDD进行checkpoint操作,这样,哪怕其持久化数据丢失
了,也可以直接读取其checkpoint的数据;
三、序列化的持久化级别
除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。因为很有可能,RDD的数据是持久化到内存,或者磁盘中的。那么,此时,如果内存大小不是特别充足,
完全可以使用序列化的持久化级别,比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法即可。 这样的话,将数据序列化之后,再持久化,可以大大减小对内存的消耗。此外,数据量小了之后,如果要写入磁盘,那么磁盘io性能消耗也比较小。 对RDD持久化序列化后,RDD的每个partition的数据,都是序列化为一个巨大的字节数组。这样,对于内存的消耗就小的多了。但是唯一的缺点就是,获取RDD数据时,
需要对其进行反序列化,会增大其性能开销。 因此,对于序列化的持久化级别,还可以进一步优化,也就是说,使用Kryo序列化类库,这样,可以获得更快的序列化速度,并且占用更小的内存空间。但是要记住,
如果RDD的元素(RDD<T>的泛型类型),是自定义类型的话,在Kryo中提前注册自定义类型。
28、对多次使用的RDD进行持久化或Checkpoint的更多相关文章
- spark新能优化之多次使用RDD的持久化或checkPoint
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作.那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算. 此外,如果要保证在RDD的持久化数据 ...
- Spark(七)【RDD的持久化Cache和CheckPoint】
RDD的持久化 1. RDD Cache缓存 RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中.但是并不是这两个方法被调用时立即缓存,而是 ...
- RDD的cache 与 checkpoint 的区别
问题:cache 与 checkpoint 的区别? 关于这个问题,Tathagata Das 有一段回答: There is a significant difference between cac ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- spark系列-7、spark调优
官网说明:http://spark.apache.org/docs/2.1.1/tuning.html#data-serialization 一.JVM调优 1.1.Java虚拟机垃圾回收调优的背景 ...
- Spark调优秘诀
1.诊断内存的消耗 在Spark应用程序中,内存都消耗在哪了? 1.每个Java对象都有一个包含该对象元数据的对象头,其大小是16个Byte.由于在写代码时候,可能会出现这种情况:对象头比对象本身占有 ...
- Spark调优秘诀——超详细
版权声明:本文为博主原创文章,转载请注明出处. Spark调优秘诀 1.诊断内存的消耗 在Spark应用程序中,内存都消耗在哪了? 1.每个Java对象都有一个包含该对象元数据的对象头,其大小是16个 ...
- spark性能优化(包括优化原理及基本方法)
https://www.jianshu.com/p/b8841a8925fb spark性能优化 1.诊断内存的消耗 2. 高性能序列化类库 3. 优化数据结构 4. 对多次使用的rdd进行持久化或者 ...
随机推荐
- [洛谷P3227][HNOI2013]切糕
题目大意:有一个$n\times m$的切糕,每一个位置的高度可以在$[1,k]$之间,每个高度有一个代价,要求四联通的两个格子之间高度最多相差$D$,问可行的最小代价.$n,m,k,D\leqsla ...
- App开放接口API安全性之Token签名Sign的设计与实现
前言 在app开放接口api的设计中,避免不了的就是安全性问题,因为大多数接口涉及到用户的个人信息以及一些敏感的数据,所以对这些接口需要进行身份的认证,那么这就需要用户提供一些信息,比如用户名密码等, ...
- ppt thinkcell-Thinkcell: 一款强大的专业图表制作工具
https://jingyan.baidu.com/article/6dad50750e6121a123e36e00.html
- Springboot打包执行源码解析
一.打包 Springboot打包的时候,需要配置一个maven插件[spring-boot-maven-plugin] <build> <plugins> <plugi ...
- Oracle---视图插参数
1.创建一个参数Package create or replace package p_view_param is -- Author : ALANN -- Created : 2017/12/2 ...
- Hook executed successfully but returned HTTP 403
jenkins配置gitlab的webhook,完成配置,测试结果显示 Hook executed successfully but returned HTTP 403 解决: 进入jenkins: ...
- text-overflow 全兼容
text-overflow 全兼容 text-overflow 这个CSS属性用于设置或检索是否使用一个省略标记(...)标示对象内文本的溢出.比起在后台用程序截断文本再附上省略标记的做法,用CSS来 ...
- Js保存图片到本地
注:此方法是使用hbuilderx云打包之后才能用,否则在浏览器中会报 plus is not defined 官方文档 http://www.html5plus.org/doc/zh_cn/gall ...
- FreeRTOS队列操作
API函数 //创建 #if( configSUPPORT_DYNAMIC_ALLOCATION == 1 ) #define xQueueCreate( uxQueueLength, uxItemS ...
- SpringBoot返回date日期格式化
SpringBoot返回date日期格式化,解决返回为TIMESTAMP时间戳格式或8小时时间差 问题描述 在Spring Boot项目中,使用@RestController注解,返回的java对象中 ...