CopyOnWrite 思想在 Kafka 源码中的运用
CopyOnWrite 思想在 Kafka 源码中的运用
在 Kafka 的内核源码中,有这么一个场景,客户端在向 Kafka 写数据的时候,会把消息先写入客户端本地的内存缓冲,然后在内存缓冲里形成一个 Batch 之后再一次性发送到 Kafka 服务器上去,这样有助于提升吞吐量。
请看下图:
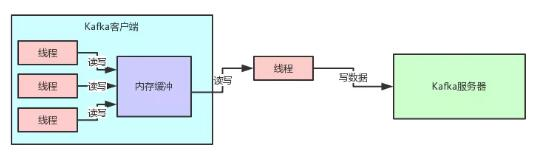
这个时候 Kafka 的内存缓冲用的是什么数据结构呢?
请看源码:
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches =
new CopyOnWriteMap<TopicPartition, Deque<RecordBatch>>();
这个数据结构就是核心的用来存放写入内存缓冲中的消息的数据结构,要看懂这个数据结构需要对很多 Kafka 内核源码里的概念进行解释。Kafka 是自己实现了一个 CopyOnWriteMap,这个CopyOnWriteMap 采用的就是 CopyOnWrite 思想。
我们来看一下这个 CopyOnWriteMap 的源码实现:
// 典型的volatile修饰普通Map
private volatile Map<K, V> map; @Override
public synchronized V put(K k, V v) {
// 更新的时候先创建副本,更新副本,然后对volatile变量赋值写回去
Map<K, V> copy = new HashMap<K, V>(this.map);
V prev = copy.put(k, v);
this.map = Collections.unmodifiableMap(copy);
return prev;
} @Override
public V get(Object k) {
// 读取的时候直接读volatile变量引用的map数据结构,无需锁
return map.get(k);
}
Kafka 这个核心数据结构在这里之所以采用 CopyOnWriteMap 思想来实现,就是因为这个 Map 的 Key-Value 对,其实没那么频繁更新。
也就是 TopicPartition-Deque 这个 Key-Value 对,更新频率很低。但是它的 Get 操作却是高频的读取请求,因为会高频的读取出来一个 TopicPartition 对应的 Deque 数据结构,来对这个队列进行入队出队等操作,所以对于这个 Map 而言,高频的是其 Get 操作。这个时候,Kafka 就采用了 CopyOnWrite 思想来实现这个 Map,避免更新 Key-Value 的时候阻塞住高频的读操作,实现无锁的效果,优化线程并发的性能。
相信看完这个文章,对于 CopyOnWrite 思想以及适用场景,包括 JDK 中的实现,以及在 Kafka 源码中的运用,都有了一个切身的体会了。
CopyOnWrite 思想在 Kafka 源码中的运用的更多相关文章
- Kafka源码中的Producer Record定义
1.ProducerRecord 含义: 发送给Kafka Broker的key/value 值对 2.内部数据结构: -- Topic (名字) -- PartitionID ( 可选) -- Ke ...
- Linux Kafka源码环境搭建
本文主要讲述的是如何搭建Kafka的源码环境,主要针对的Linux操作系统下IntelliJ IDEA编译器,其余操作系统或者IDE可以类推. 1.安装和配置JDK确认JDK版本至少为1.7,最好是1 ...
- Kakfa揭秘 Day3 Kafka源码概述
Kakfa揭秘 Day3 Kafka源码概述 今天开始进入Kafka的源码,本次学习基于最新的0.10.0版本进行.由于之前在学习Spark过程中积累了很多的经验和思想,这些在kafka上是通用的. ...
- Kafka源码分析(二) - 生产者
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 使用方式 step 1: 设置必要参数 step 2: 创建KafkaProduc ...
- Kafka源码分析系列-目录(收藏不迷路)
持续更新中,敬请关注! 目录 <Kafka源码分析>系列文章计划按"数据传递"的顺序写作,即:先分析生产者,其次分析Server端的数据处理,然后分析消费者,最后再补充 ...
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- Kafka 源码剖析
1.概述 在对Kafka使用层面掌握后,进一步提升分析其源码是极有必要的.纵观Kafka源码工程结构,不算太复杂,代码量也不算大.分析研究其实现细节难度不算太大.今天笔者给大家分析的是其核心处理模块, ...
- apache kafka & CDH kafka源码编译
Apache kafka编译 前言 github网站kafka项目的README.md有关于kafka源码编译的说明 github地址:https://github.com/apache/kafka ...
随机推荐
- Redis基于主从复制的RCE 4.x/5.x 复现
0x00 前言 最近期末考试,博客好久没有更新了,这段时间爆了三四个洞,趁着还没去实习,抓紧复现一下,这次复现的是Redis的RCE,复现过程中也遇到很多问题,记录下来和大家分享一下 0x01 拉取镜 ...
- 51nod 1720 祖玛
吉诺斯在手机上玩祖玛的游戏.在这个游戏中,刚开始有n个石头排成一排,第i个石头的颜色是ci.游戏的目标是尽可能快的把所有石头都消掉. 每一秒钟,吉诺斯可以选择一段连续的子段,并且这个子段是回文,然后把 ...
- js计算两个时间差
时间格式 time:'2018-04-26 15:49:00'需要转换为time:'2018/04/26 15:49:00' 使用time.replace(/\-/g, "/") ...
- oracle删除重复数据,只保留一条
比如,某个表要按照id和name重复,就算重复数据 delete from 表名 where rowid not in (select min(rowid) from 表名 group by id,n ...
- softmax 函数的理解和优点
我们知道max,假如说我有两个数,a和b,并且a>b,如果取max,那么就直接取a,没有第二种可能.但有的时候我不想这样,因为这样会造成分值小的那个饥饿.所以我希望分值大的那一项经常取到,分值小 ...
- .net web api 返回的是xml
var result = new HttpResponseMessage { Content = new StringContent(JsonConvert.SerializeObject(dto2) ...
- Linux 一条长命令占用多行
前言 考察下面的脚本: ? 1 emcc -o ./dist/test.html --shell-file ./tmp.html --source-map-base dist -O3 -g4 --so ...
- asp.net+ tinymce粘贴word
公司做的项目需要用到粘贴Word功能.就是将word内容一键粘贴到网页编辑器(在线富文本编辑器)中.Chrome+IE默认支持粘贴剪切板中的图片,但是我要粘贴的文章存在word里面,图片多达数十张,我 ...
- Intel 8086 CPU
一.8086概述 Intel8086拥有四个16位的通用寄存器,也能够当作八个8位寄存器来存取,以及四个16位索引寄存器(包含了堆栈指标).资料寄存器通常由指令隐含地使用,针对暂存值需要复杂的寄存器配 ...
- JSON字符串 拼接与解析
常用方式: json字符串拼接(目前使用过两种方式): 1.运用StringBuilder拼接 StringBuilder json = new StringBuilder(); json.appen ...