CSharpGL(23)用ComputeShader实现一个简单的ParticleSimulator
CSharpGL(23)用ComputeShader实现一个简单的ParticleSimulator
我还没有用过Compute Shader,所以现在把红宝书里的例子拿来了,加入CSharpGL中。
效果图
如下图所示。

或者看视频演示。
下面是红宝书原版的代码效果。

下载
CSharpGL已在GitHub开源,欢迎对OpenGL有兴趣的同学加入(https://github.com/bitzhuwei/CSharpGL)
Compute Shader
Compute Shader的运行与Vertex Shader等不同:它不在pipeline上运行。调用它时用的是这样的命令:
void glDispatchCompute(GLuint um_groups_x, Luint num_groups_y, GLuint num_groups_z);
Compute Shader把并行的计算单元看做一个global work group,它下面分为若干个local work group,local work group又分为若干个执行单元。一个执行单元对应一次对Compute Shader的调用。目前我还不知道这种分为2级的设定有什么好处。
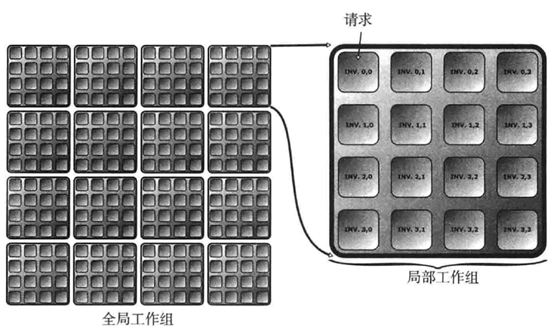
Compute Shader可以像其他Shader一样操作纹理、buffer、原子计数器等资源;它也有一些特有的内置变量(用于获取此执行单元的位置,即属于哪个local work group,是第几个)。
下面通过本文开头的ParticleSimulator的例子来学习一下如何使用Compute Shader。
Particle Simulator
设计
这个例子中,我们用Compute Shader来更新1百万个粒子的位置和速度。为了简单,我们不考虑粒子之间的碰撞问题。
首先分配2个大缓存,一个存放粒子的速度,一个存放粒子的位置。每个时刻里,Compute Shader开始运行,并且每个请求都只处理一个单一的粒子。Compute Shader从缓存中读取当前的速度和位置,计算出新的速度和位置,然后写入缓存中。
然后设置几个引力器,他们都有质量和位置。每个粒子的质量都视作1。每个粒子都受到这些引力器的作用。引力器的位置和质量用一个uniform块保存。
粒子还有生命周期,每次更新时都减少之。少到0时就重置为1,且重置其位置到原点附近。这样模拟过程就能持续进行下去。
模拟粒子的Compute Shader
此Compute Shader如下。
#version core
// 引力器的位置和质量
layout (std140, binding = ) uniform attractor_block
{
vec4 attractor[]; // xyz = position, w = mass
};
// 每块中粒子的数量为128
layout (local_size_x = ) in;
// 使用两个缓存来记录粒子的速度和质量
layout (rgba32f, binding = ) uniform imageBuffer velocity_buffer;
layout (rgba32f, binding = ) uniform imageBuffer position_buffer;
// 时间间隔
uniform float dt = 1.0; void main(void)
{
// 读取当前粒子的速度和位置
vec4 vel = imageLoad(velocity_buffer, int(gl_GlobalInvocationID.x));
vec4 pos = imageLoad(position_buffer, int(gl_GlobalInvocationID.x)); int i;
// 更新位置和生命周期
pos.xyz += vel.xyz * dt;
pos.w -= 0.0008 * dt;
// 对每个引力器
for (i = ; i < ; i++)
{
// 计算受力情况并更新速度
vec3 dist = (attractor[i].xyz - pos.xyz);
vel.xyz += dt * dt * attractor[i].w * normalize(dist) / (dot(dist, dist) + 10.0);
}
// 如何粒子过期,重置它
if (pos.w <= 0.0)
{
pos.xyz = -pos.xyz * 0.01;
vel.xyz *= 0.01;
pos.w += 1.0f;
}
// 将新的速度和位置保存到缓存
imageStore(position_buffer, int(gl_GlobalInvocationID.x), pos);
imageStore(velocity_buffer, int(gl_GlobalInvocationID.x), vel);
}
初始化
创建2个缓存,把粒子的初始位置放到原点附近,生命周期在0~1之间随机。
protected override void DoInitialize()
{
{
// 创建 compute shader program
var computeProgram = new ShaderProgram();
var shaderCode = new ShaderCode(File.ReadAllText(@"Shaders\particleSimulator.comp"), ShaderType.ComputeShader);
var shader = shaderCode.CreateShader();
computeProgram.Create(shader);
shader.Delete();
this.computeProgram = computeProgram;
}
{
GL.GetDelegateFor<GL.glGenVertexArrays>()(, render_vao);
GL.GetDelegateFor<GL.glBindVertexArray>()(render_vao[]);
// 初始化粒子位置
GL.GetDelegateFor<GL.glGenBuffers>()(, position_buffer);
GL.BindBuffer(BufferTarget.ArrayBuffer, position_buffer[]);
var positions = new UnmanagedArray<vec4>(ParticleSimulatorCompute.particleCount);
unsafe
{
var array = (vec4*)positions.FirstElement();
for (int i = ; i < ParticleSimulatorCompute.particleCount; i++)
{
array[i] = new vec4(
(float)(random.NextDouble() - 0.5) * ,
(float)(random.NextDouble() - 0.5) * ,
(float)(random.NextDouble() - 0.5) * ,
(float)(random.NextDouble())
);
}
}
GL.BufferData(BufferTarget.ArrayBuffer, positions, BufferUsage.DynamicCopy);
positions.Dispose();
GL.GetDelegateFor<GL.glVertexAttribPointer>()(, , GL.GL_FLOAT, false, , IntPtr.Zero);
GL.GetDelegateFor<GL.glEnableVertexAttribArray>()();
// 初始化粒子速度
GL.GetDelegateFor<GL.glGenBuffers>()(, velocity_buffer);
GL.BindBuffer(BufferTarget.ArrayBuffer, velocity_buffer[]);
var velocities = new UnmanagedArray<vec4>(ParticleSimulatorCompute.particleCount);
unsafe
{
var array = (vec4*)velocities.FirstElement();
for (int i = ; i < ParticleSimulatorCompute.particleCount; i++)
{
array[i] = new vec4(
(float)(random.NextDouble() - 0.5) * 0.2f,
(float)(random.NextDouble() - 0.5) * 0.2f,
(float)(random.NextDouble() - 0.5) * 0.2f,
);
}
}
GL.BufferData(BufferTarget.ArrayBuffer, velocities, BufferUsage.DynamicCopy);
velocities.Dispose();
// 把缓存绑定到TBO
GL.GenTextures(, textureBufferPosition);
GL.BindTexture(GL.GL_TEXTURE_BUFFER, textureBufferPosition[]);
GL.GetDelegateFor<GL.glTexBuffer>()(GL.GL_TEXTURE_BUFFER, GL.GL_RGBA32F, position_buffer[]);
GL.GenTextures(, textureBufferVelocity);
GL.BindTexture(GL.GL_TEXTURE_BUFFER, textureBufferVelocity[]);
GL.GetDelegateFor<GL.glTexBuffer>()(GL.GL_TEXTURE_BUFFER, GL.GL_RGBA32F, velocity_buffer[]); // 初始化引力器
GL.GetDelegateFor<GL.glGenBuffers>()(, attractor_buffer);
GL.BindBuffer(BufferTarget.UniformBuffer, attractor_buffer[]);
GL.GetDelegateFor<GL.glBufferData>()(GL.GL_UNIFORM_BUFFER, * Marshal.SizeOf(typeof(vec4)), IntPtr.Zero, GL.GL_DYNAMIC_COPY);
GL.GetDelegateFor<GL.glBindBufferBase>()(GL.GL_UNIFORM_BUFFER, , attractor_buffer[]);
}
{
// 初始化渲染器
var visualProgram = new ShaderProgram();
var shaderCodes = new ShaderCode[];
shaderCodes[] = new ShaderCode(File.ReadAllText(@"Shaders\particleSimulator.vert"), ShaderType.VertexShader);
shaderCodes[] = new ShaderCode(File.ReadAllText(@"Shaders\particleSimulator.frag"), ShaderType.FragmentShader);
var shaders = (from item in shaderCodes select item.CreateShader()).ToArray();
visualProgram.Create(shaders);
foreach (var item in shaders) { item.Delete(); }
this.visualProgram = visualProgram;
}
}
protected override void DoInitialize()
渲染
渲染循环
渲染过程有3个步骤,首先要更新引力器,然后更新粒子速度和位置,最后渲染出来。
float time = 0.0f;
protected override void DoRender(RenderEventArgs arg)
{
// 更新time和deltaTime
float deltaTime = (float)random.NextDouble() * ;
time += (float)random.NextDouble() * ; // 更新引力器位置和质量
GL.BindBuffer(BufferTarget.UniformBuffer, attractor_buffer[]);
IntPtr attractors = GL.MapBufferRange(BufferTarget.UniformBuffer,
, * Marshal.SizeOf(typeof(vec4)),
MapBufferRangeAccess.MapWriteBit | MapBufferRangeAccess.MapInvalidateBufferBit);
unsafe
{
var array = (vec4*)attractors.ToPointer();
for (int i = ; i < ; i++)
{
array[i] = new vec4(
(float)(Math.Sin(time * (float)(i + ) * 7.5f * 20.0f)) * 50.0f,
(float)(Math.Cos(time * (float)(i + ) * 3.9f * 20.0f)) * 50.0f,
(float)(Math.Sin(time * (float)(i + ) * 5.3f * 20.0f))
* (float)(Math.Cos(time * (float)(i + ) * 9.1f)) * 100.0f,
ParticleSimulatorCompute.attractor_masses[i]);
}
} GL.UnmapBuffer(BufferTarget.UniformBuffer);
GL.BindBuffer(BufferTarget.UniformBuffer, ); // 激活compute shader,绑定速度和位置缓存
computeProgram.Bind();
GL.GetDelegateFor<GL.glBindImageTexture>()(, textureBufferVelocity[], , false, , GL.GL_READ_WRITE, GL.GL_RGBA32F);
GL.GetDelegateFor<GL.glBindImageTexture>()(, textureBufferPosition[], , false, , GL.GL_READ_WRITE, GL.GL_RGBA32F);
// 指定deltaTime
computeProgram.SetUniform("dt", deltaTime);
// 执行compute shader
GL.GetDelegateFor<GL.glDispatchCompute>()(1000000, , );
// 确保compute shader的计算已完成
GL.GetDelegateFor<GL.glMemoryBarrier>()(GL.GL_SHADER_IMAGE_ACCESS_BARRIER_BIT); // 渲染出粒子效果
visualProgram.Bind();
mat4 view = arg.Camera.GetViewMat4();
mat4 projection = arg.Camera.GetProjectionMat4();
visualProgram.SetUniformMatrix4("mvp", (projection * view).to_array());
GL.GetDelegateFor<GL.glBindVertexArray>()(render_vao[]);
GL.Enable(GL.GL_BLEND);
GL.BlendFunc(GL.GL_ONE, GL.GL_ONE);
GL.DrawArrays(DrawMode.Points, , ParticleSimulatorCompute.particleCount);
GL.Disable(GL.GL_BLEND);
}
protected override void DoRender(RenderEventArgs arg)
粒子着色程序
渲染粒子的vertex shader很简单。
#version core in vec4 position; uniform mat4 mvp; out float intensity; void main(void)
{
intensity = position.w;//生命周期(0~1)
gl_Position = mvp * vec4(position.xyz, 1.0);
}
下面是fragment shader。粒子有生命周期,我们就据此赋予其不同的颜色。
#version core layout (location = ) out vec4 color; in float intensity; void main(void)
{
color = vec4(0.0f, 0.2f, 1.0f, 1.0f) * intensity + vec4(0.2f, 0.05f, 0.0f, 1.0f) * (1.0f - intensity);
}
万事俱备,效果就出来了。
2016-05-17
尝试新的粒子运动方式,效果如图。
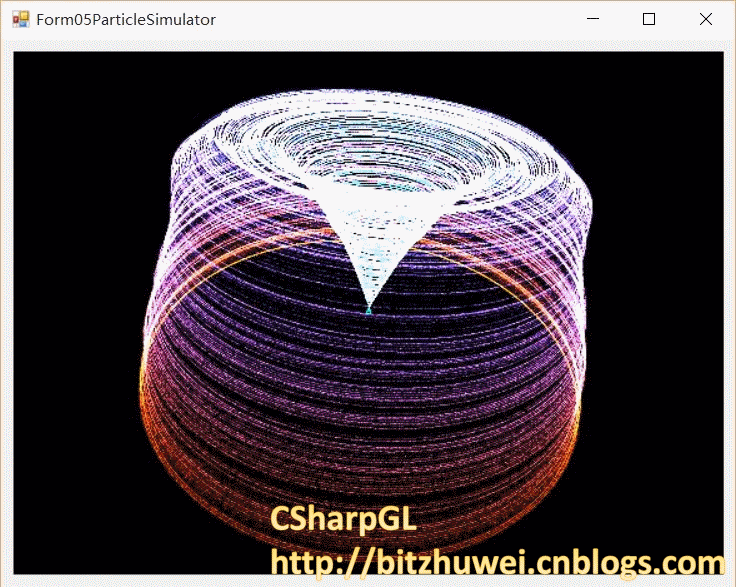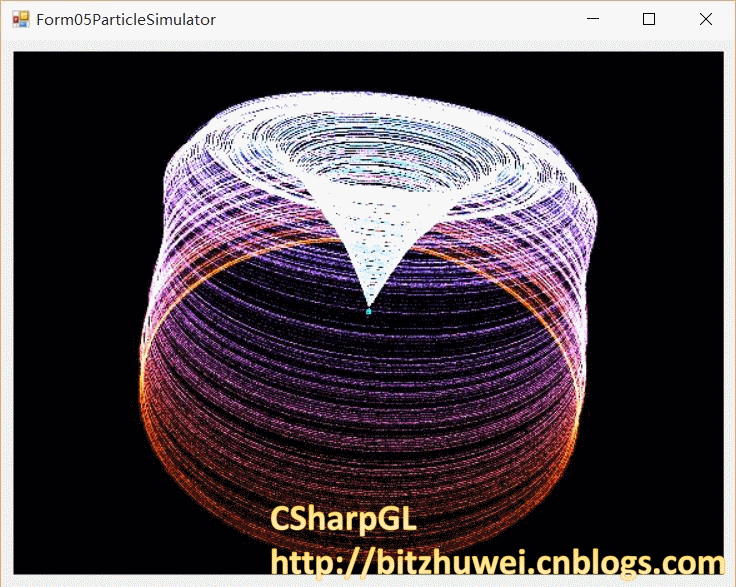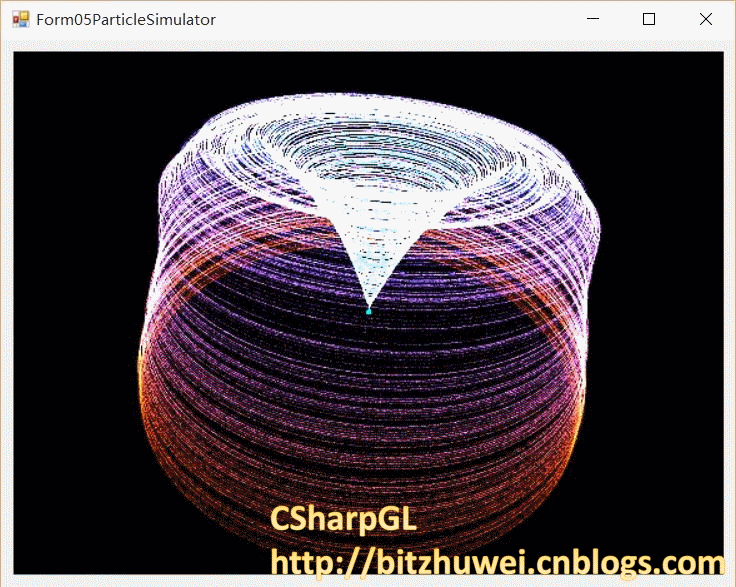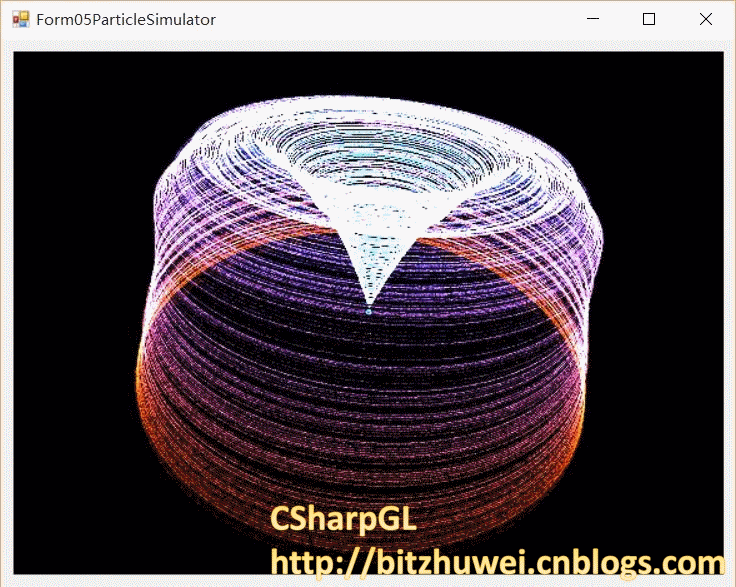
所需的compute shader代码如下。
#version core layout (std140, binding = ) uniform attractor_block
{
vec4 attractor[]; // xyz = position, w = mass
}; layout (local_size_x = ) in; layout (rgba32f, binding = ) uniform imageBuffer velocity_buffer;
layout (rgba32f, binding = ) uniform imageBuffer position_buffer; uniform float dt = 1.0; void main(void)
{
vec4 vel = imageLoad(velocity_buffer, int(gl_GlobalInvocationID.x));
vec4 pos = imageLoad(position_buffer, int(gl_GlobalInvocationID.x)); int i;
float factor = 0.05f;
pos.xyz += vel.xyz * dt;
pos.w -= factor * 0.025f * dt; vel.xyz += vec3(, factor * -0.02f, ); if (pos.w <= 0.0)
{
pos.xyz = -pos.xyz * 0.01;
vel.x = factor * sin(gl_GlobalInvocationID.x);
vel.y = factor * 3f;
vel.z = factor * cos(gl_GlobalInvocationID.x);
pos.w += 1.0f;
} imageStore(position_buffer, int(gl_GlobalInvocationID.x), pos);
imageStore(velocity_buffer, int(gl_GlobalInvocationID.x), vel);
}
fountain effect
总结
原CSharpGL的其他功能(3ds解析器、TTF2Bmp、CSSL等),我将逐步加入新CSharpGL。
欢迎对OpenGL有兴趣的同学关注(https://github.com/bitzhuwei/CSharpGL)
CSharpGL(23)用ComputeShader实现一个简单的ParticleSimulator的更多相关文章
- CSharpGL(24)用ComputeShader实现一个简单的图像边缘检测功能
CSharpGL(24)用ComputeShader实现一个简单的图像边缘检测功能 效果图 这是红宝书里的例子,在这个例子中,下述功能全部登场,因此这个例子可作为使用Compute Shader的典型 ...
- 一个简单的CSS示例
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8" /> 5 & ...
- 应用OpenMP的一个简单的设计模式
小喵的唠叨话:最近很久没写博客了,一是因为之前写的LSoftmax后馈一直没有成功,所以在等作者的源码.二是最近没什么想写的东西.前两天,在预处理图片的时候,发现处理200w张图片,跑了一晚上也才处理 ...
- 《Entity Framework 6 Recipes》翻译系列 (3) -----第二章 实体数据建模基础之创建一个简单的模型
第二章 实体数据建模基础 很有可能,你才开始探索实体框架,你可能会问“我们怎么开始?”,如果你真是这样的话,那么本章就是一个很好的开始.如果不是,你已经建模,并在实体分裂和继承方面感觉良好,那么你可以 ...
- 通过Knockout.js + ASP.NET Web API构建一个简单的CRUD应用
REFERENCE FROM : http://www.cnblogs.com/artech/archive/2012/07/04/Knockout-web-api.html 较之面向最终消费者的网站 ...
- [stm32] 一个简单的stm32vet6驱动的天马4线SPI-1.77寸LCD彩屏DEMO
书接上文<1.一个简单的nRF51822驱动的天马4线SPI-1.77寸LCD彩屏DEMO> 我们发现用16MHz晶振的nRF51822驱动1.77寸的spi速度达不到要求 本节主要采用7 ...
- ios开发UI篇—使用纯代码自定义UItableviewcell实现一个简单的微博界面布局
本文转自 :http://www.cnblogs.com/wendingding/p/3761730.html ios开发UI篇—使用纯代码自定义UItableviewcell实现一个简单的微博界面布 ...
- 一个简单的Servlet容器实现
上篇写了一个简单的Java web服务器实现,只能处理一些静态资源的请求,本篇文章实现的Servlet容器基于前面的服务器做了个小改造,增加了Servlet请求的处理. 程序执行步骤 创建一个Serv ...
- 一个简单的Java web服务器实现
前言 一个简单的Java web服务器实现,比较简单,基于java.net.Socket和java.net.ServerSocket实现: 程序执行步骤 创建一个ServerSocket对象: 调用S ...
随机推荐
- 记一次SQLServer的分页优化兼谈谈使用Row_Number()分页存在的问题
最近有项目反应,在服务器CPU使用较高的时候,我们的事件查询页面非常的慢,查询几条记录竟然要4分钟甚至更长,而且在翻第二页的时候也是要这么多的时间,这肯定是不能接受的,也是让现场用SQLServerP ...
- 06.SQLServer性能优化之---数据库级日记监控
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 之前说了一下数据库怎么发邮件:http://www.cnblogs.com/duniti ...
- 08.LoT.UI 前后台通用框架分解系列之——多样的Tag选择器
LOT.UI分解系列汇总:http://www.cnblogs.com/dunitian/p/4822808.html#lotui LoT.UI开源地址如下:https://github.com/du ...
- OpenCASCADE AIS Manipulator
OpenCASCADE AIS Manipulator eryar@163.com Abstract. OpenCASCADE7.1.0 introduces new built-in interac ...
- MySQL 系列(二) 你不知道的数据库操作
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 本章内容: 查看\创建\使用\删除 数据库 用户管理及授权实战 局域网 ...
- Twproject Gantt开源甘特图功能扩展
1.Twproject Gantt甘特图介绍 Twproject Gantt 是一款基于 jQuery 开发的甘特图组件,也可以创建其它图表,例如任务树(Task Trees).内置编辑.缩放和 CS ...
- 【JavaScript】innerHTML、innerText和outerHTML的用法区别
用法: <div id="test"> <span style="color:red">test1</span> tes ...
- SuperMap-iServer-单点登录功能验证(CAS)
SuperMap-iServer-单点登录功能验证(CAS) 1.测试目的: 验证SuperMap-iServer使用CAS单点登录的功能是否正常. 2.测试环境: SuperMap-iServer8 ...
- Android种使用Notification实现通知管理以及自定义通知栏(Notification示例四)
示例一:实现通知栏管理 当针对相同类型的事件多次发出通知,作为开发者,应该避免使用全新的通知,这时就应该考虑更新之前通知栏的一些值来达到提醒用户的目的.例如我们手机的短信系统,当不断有新消息传来时,我 ...
- 使用Nginx反向代理 让IIS和Tomcat等多个站点一起飞
使用Nginx 让IIS和Tomcat等多个站点一起飞 前言: 养成一个好习惯,解决一个什么问题之后就记下来,毕竟“好记性不如烂笔头”. 这样也能帮助更多的人 不是吗? 最近闲着没事儿瞎搞,自己在写一 ...