Eric's并发用户数估算与Little定律的等价性
在国内性能测试的领域有一篇几乎被奉为大牛之作的经典文章,一个名叫Eric Man Wong 于2004年发表了名为《Method for Estimating the Number of Concurrent Users》,里面介绍了一种对系统并发用户数估算的公式,并较为详细的阐述了过程以及证明方法。这个公式使用非常简单,很多性能测试工程师都在自己的项目中使用或者打算尝试使用,以至于在不分场合以及不具体分析系统用户行为的情况下使用。本文不打算深入探讨该公式的适用范围,我会在以后的文章中探讨这个问题。
我并不否定该公式在文章中作者指定条件下的正确性,它在一定程度上帮助我从另外一种思路考虑系统的性能模型,同时通过对性能工程的学习我发现该估算公式与Little定律尽然是等价的。
下面回顾下Eric是怎么得出这个公式的,根据原文的意思大概是这样:
首先我们知道在系统中占用系统资源的都是在系统正在活动的用户,也就是所谓的并发用户,对于但是并不是出于系统中的用户比如刚登出或者还没来得及登入的用户是不会消耗系统资源的,所以当我们想测量系统的容量时,这部分用户不需要考虑,可以只考虑当前出于系统中的活跃用户。
然后文章引入了一个login session的概念,当然这个东西是一直有的,但本文需要用到所以特别指明是它是等同于用户登出系统时与登入系统时的这段时间差,也就是session的生存周期。
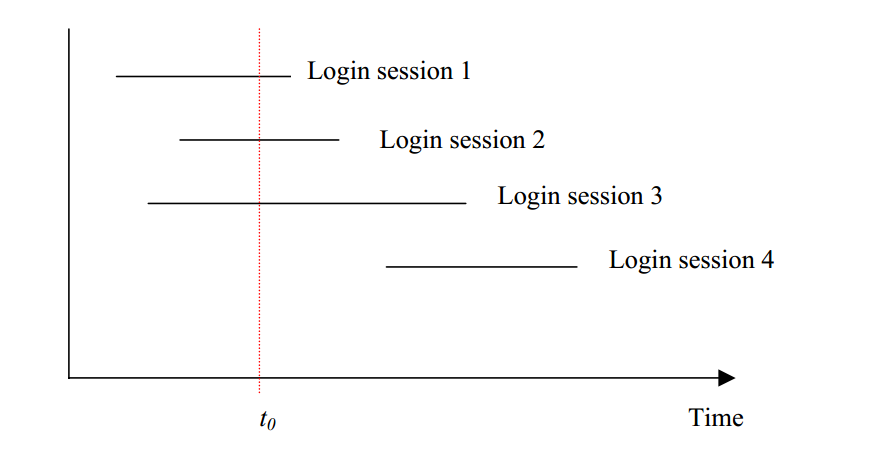
文章中这个图很好的描述了系统在处理陆续到达用户时的系统某一时刻的状态,以及诠释通过计算并发用户数统计系统性能的概念或者思想。
最终得出C=nL/T.
证明过程以及后面的详述不表。
接着再来看看什么是Little定律。
说实话这个定律应该是一个最基本的,也是在很多领域中已经广泛应用的定律,但是在国内性能测试领域出现的频率却不高。
直接借用《Programing Pearls 》的翻译:
大多数的估算都遵循这样一个浅显的法则:总花费就等于每个部分的花费再乘以总的部分数。但某些时候我们还需要更深入地了解细节。俄亥俄州立大学的Bruce Weide就一条通用得出奇的规则写下如下文字。
Denning和Buzen引入的"操作分析"(参见Computing Surveys 10第3期,1978年11月,第225~261页)比计算机系统队列网络模型更加通用。他们的展示相当精彩,不过由于文章主题的限制,他们并未深入揭示Little定律的通用性。他们的证明方法与队列和计算机系统都没有关系。想象一个任意的、有某些东西进入和离开的系统。Little定律可以表述为"系统中的东西的平均数目等于这些东西离开系统的平均速度乘以每个东西离开系统所花费的平均时间"。(若系统的总体出入流是平衡的,离开速率也就是进入速率。)
在建立性能模型时,一般是常使用如下公式表述Little定律:
N=X*R
N 表示系统中同时活动的用户,包括正在处理中和队列中的
X表示用户相继到达系统的速率,在平衡状态时即为系统吞吐量(到达=离开)
R表示每个用户在系统中平均的驻留时间
也就是说系统中平均同时被服务的用户数量等于用户到达系统的速度*每个用户在系统中待的时间
这条定律非常实用也具有很广的适用性,举一个例子:
比如说,你正在排队等待进入一个很受欢迎的夜总会,你可以通过估计人们进入的速率来知道自己还要等待多长时间。应用Little定律,你可以推理:"这个地方差不多能容纳60人,平均在里面呆的时间是3个小时,所以我们以每小时20人的速度进入。而我们前面还有20个人,所以我们还要等上一个小时。
上面的例子可以用公式进一步表述:
R=3 hours
X=20 人/hour
So N=3 hours * 20 人/hour=60 人,该夜总会能同时容纳60人
大家可以比较以上两种方法和定律,他们的表述是完全不同的,计算所需要的变量也不一样,但是经过下面的case后会有让你惊奇的发现。
Case:
有一个论坛系统,每天的活跃用户有500,用户活跃时间主要集中在晚上7点到12点,平均每人登入登出一次,登陆时长为30分钟,请为该系统建立性能测试模型。
使用Eric的估算公式解:
假设系统后端维护session,那么这个session的长度即为30分钟,L=30minutes
用户活跃时长已经得知是从7点到12点共五个小时,T=5 hours
那么并发用户数C=n*L/T=500*30/(5*60)=50
同时我们也可以使用Little定律对系统并发用户数进行估算:
500个用户需要在7点到12点这段时间陆续登入论坛可知,到达率X=500/(5*60)= 5/3 个用户/分钟
登陆时长30分钟为用户在系统中的驻留时间,R=30分钟
那么系统中同时被服务也就是并发数N=X*R=5/3 *30=50
看似两种全完不同的方法计算出来的结果完全一样,是巧合吗?或者一题多解?
我们再来从另外的角度分解Eric的估算公式:
C=n*L/T 可以表示为 C=(n/T)*L
n/T 是不是和我们刚才在上面Little中第一步一样,是计算到达率X的。
而L不就是R吗?都等同于session的长度。
也就是说C=(n/T)*T=X*R=N
结论:由以上得知,Eric's 估算公式跟Little定律是等价的. 同时读者可以自己看看他们各自的证明过程,有一定的相似性。
我们也可以在能适用的范围内放心使用这两种估算方法,以节约资源和时间。
Reference :
http://www.ece.virginia.edu/mv/edu/715/lectures/littles-law/littles-law.pdf
http://emiraga.wikispaces.com/file/view/Littles.law.January.2009.pdf
Eric's并发用户数估算与Little定律的等价性的更多相关文章
- 【转】Eric's并发用户数估算与Little定律的等价性
转自:http://www.cnblogs.com/hundredsofyears/p/3360305.html 在国内性能测试的领域有一篇几乎被奉为大牛之作的经典文章,一个名叫Eric Man Wo ...
- [转]loadrunner:系统的平均并发用户数和并发数峰值如何估算
一.经典公式1: 一般来说,利用以下经验公式进行估算系统的平均并发用户数和峰值数据 1)平均并发用户数为 C = nL/T 2)并发用户数峰值 C‘ = C + 3*根号C C是平均并发用户数,n是l ...
- LoadRunner之并发用户数与迭代关系---并发数与迭代的区别
Q1: 例如在LR里,我要测100个用户同时并发登陆所用时间,那我是不是在录制好脚本后,需要参数化“用户名”,“密码”以及在那个记事本里构造100个真实的用户名和密码? 然后运行Controller, ...
- 并发用户数与 TPS 之间的关系
1. 背景 在做性能测试的时候,很多人都用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好:对TPS不是非常理解,也根本不知道它们之间的关系,因此非常有必要进行解释. 2 ...
- 性能测试中TPS和并发用户数
并发用户数与TPS之间的关系 1. 背景 在做性能测试的时候,很多人都用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好:对TPS不是非常理解,也根本不知道它们之间的关系 ...
- 并发用户数与TPS之间的关系
1. 背景 在做性能测试的时候,很多人都用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好:对TPS不是非常理解,也根本不知道它们之间的关系,因此非常有必要进行解释. 2 ...
- 性能指标--并发用户数(Concurrent Users)
并发用户数是指:在某一时间点,与被测目标系统同时进行交互的客户端用户的数量. 并发用户数有以下几种含义: 1. 并发虚拟用户数(Concurrent Virtual Users,Users_CVU) ...
- TPS、并发用户数、吞吐量关系
TPS.并发用户数.吞吐量关系 摘要 主要描述了在性能测试中,关于TPS.并发用户数.吞吐量之间的关系和一些计算方法. loadrunner TPS 目录[-] 一.系统吞度量要素: 二.系统吞吐量评 ...
- TPS,并发用户数,吞吐量以及一些计算公式
TPS,并发用户数,吞吐量以及一些计算公式 基本概念 TPS:每秒同时处理的请求数/事务数 并发数:系统同时处理的请求数/事务数 响应时间:一般去平均响应时间,只有当方差过大时,去90%的响应时间值 ...
随机推荐
- LR问题汇总
关于录制打开IE问题 1.LR11用IE11录制脚本时能打开web页面,但是一直是0事件,也没有脚本代码; 解决方法: LR版本和IE版本兼容性问题,这个问题是我们安装环境时不注意,导致LR无法录制. ...
- 【selenium】常见问题
1鼠标变粗:setting→1.打开设置 点击 plugins 输入ideavim 把 这个勾去掉!这个是插件的配置问题. 2.editor->appearance 去掉 use bloc ...
- codeforces 673C C. Bear and Colors(暴力)
题目链接: C. Bear and Colors time limit per test 2 seconds memory limit per test 256 megabytes input s ...
- 【SOUTH CENTRAL USA 1998】 eight
[题目链接] 点击打开链接 [算法] 这是经典的八数码问题,据说此题不做人生不完整 这里笔者用的是双向广搜,由于细节较多,笔者花了3h才通过此题 [代码] #include <algorithm ...
- 【HDU 4722】 Good Numbers
[题目链接] 点击打开链接 [算法] f[i][j]表示第i位,数位和对10取模余j的数的个数 状态转移,计算答案都比较简单,笔者不再赘述 [代码] #include<bits/stdc++.h ...
- 【ZJOI 2002】 昂贵的聘礼
[题目链接] 点击打开链接 [算法] 最短路,注意不能用dijkstra,要用SPFA [代码] #include <algorithm> #include <bitset> ...
- 【旧文章搬运】Windows句柄表分配算法分析(一)
原文发表于百度空间,2009-03-30========================================================================== 阅读提示: ...
- 插入符的创建(MFC)
int CDrawRectangleDlg::OnCreate(LPCREATESTRUCT lpCreateStruct) { ) ; // TODO: 在此添加您专用的创建代码 CreateSol ...
- 洛谷 - P2657 - windy数 - 数位dp
https://www.luogu.org/problemnew/show/P2657 不含前导零且相邻两个数字之差至少为2的正整数被称为windy数. 这道题是个显然到不能再显然的数位dp了. 来个 ...
- 如何才能优雅地书写JS代码
第一:关于匿名函数的使用 要避免全局变量泛滥, 可以考虑使用匿名函数, 把不需要在外部访问的变量或者函数限制在一个比较小的范围内. 例如以下代码: <script> function fu ...