Python机器学习算法 — 支持向量机(SVM)
SVM--简介
支持向量机(Support Vector Machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。
在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
SVM--思想
建立一个最优决策超平面,使得该平面两侧距离平面最近的两类样本之间的距离最大化,从而对分类问题提供良好的泛化能力。
说白了就是:当样本点的分布无法用一条直线或几条直线分开时(即线性不可分)SVM提供一种算法,求出一个曲面用于划分。这个曲面,就称为最优决策超平面。
而且,SVM采用二次优化,因此最优解是唯一的,且为全局最优。前面提到的距离最大化就是说,这个曲面让不同分类的样本点距离最远,即求最优分类超平面等价于求最大间隔。
SVM--原理
SVM大致原理:
①假设我们要通过三八线把星星和红点分成两类。
②那么有无数多条线可以完成这个任务。
③在SVM中,我们寻找一条最优的分界线使得它到两边的Margin都最大。
④在这种情况下边缘的几个数据点就叫做Support Vector,这也是这个分类算法名字的来源。

线性可分支持向量机
1、定义
给定线性可分训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习得到的分离超平面为 wx+b=0 以及相应的分类决策函数 f(x)=sign(wx+b) 称为线性可分支持向量机。

由于训练数据线性可分,如图1所示,这时有许多超平面能将两类数据正确划分,线性可分支持向量机的目的就是从中找到最佳的超平面,使得预测新数据时有较好的表现。
以二维空间为例,相对于把超平面方程 wx+b=0 理解为一条平面直线 y=kx+b,个人更倾向于将其理解为空间平面z=ax+by+c与平面z=0的交线。将训练数据集中的样本点带入wx+b 得到的值表示空间平面z=ax+by+c上的点与z=0之间的距离,距离为正的样本为正例,距离为负的样本为负例。注意,二维空间中的超平面是图2中的红色直线。

图2 二维空间中的超平面
2、函数间隔和几何间隔

图3 二类分类问题
在如上图所示的二维空间中,假设已经找到了超平面将二维空间划分为两类,“○”表示正例,“×”表示负例。其中A,B,C三个点表示3个样本点。一般来说,一个点距离超平面的远近可以表示分类预测的确信程度。比如,预测这三个点的类别的时候,点A距离超平面较远,若预测该点为正例,就有比较大的把握。相反,点C距离超平面较近,若预测该点为正例就不那么确定,因为有可能是超平面选择的不合理而导致点C被误分为正例。因此,相比距离超平面较远的点,距离较近的点对超平面的选择有更大的影响,我们将其称之为支持向量。支持向量决定了我们如何选择超平面,可见支持向量的重要性。函数间隔和几何间隔的提出,为找到最佳的超平面提供了依据。
2.1、函数间隔
对于给定的训练数据集T和超平面(ω,b),定义超平面(ω,b)关于样本点(x_i,y_i)的函数间隔为

定义超平面(ω,b)关于训练数据集T的函数间隔为超平面(ω,b)关于T中所有样本点(x_i,y_i)的函数间隔的最小值,即

函数间隔越小的点离超平面越近,因此通过最大化训练数据集的函数间隔,即找到一条直线离两类样本点尽量的远,来找到最佳的超平面听起来似乎很合理。但是,用函数间隔来选择超平面存在一个问题:只要成比例地改变ω和b,超平面并没有改变但是函数间隔却会改变。在二维空间中,成比例地改变ω和b就是将空间平面z=ax+by+c以超平面为轴心进行转动。因此,需要对ω进行规范化,从而引出了几何间隔的概念。
2.2、几何间隔
对于给定的训练数据集T和超平面(ω,b),定义超平面(ω,b)关于样本点(x_i,y_i)的几何间隔为

定义超平面(ω,b)关于训练数据集T的几个间隔为超平面(ω,b)关于T中所有样本点(x_i,y_i)的函数间隔的最小值,即

在二维空间中,几何间隔就是将空间平面z=ax+by+c固定,不再以超平面为轴心进行转动。此时,成比例地改变ω和b不再对几何间隔有影响。
3.间隔最大化
支持向量机学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的超平面。对于线性可分的训练数据集而言,超平面有无穷多个,但是几何间隔最大的超平面是唯一的。这里的间隔最大化称为硬间隔最大化。这是因为几何间隔是指离超平面最近的正负样本点,最大化几何间隔意味着当前的超平面不仅可以很合理地划分训练数据集,对未知的测试数据集应当也有较好的分类预测能力。因此,接下来的问题就是如何求得一个几何间隔最大的超平面。这个问题可以表示为约束最优化问题:

考虑几何间隔和函数间隔的关系,可将这个问题改写为:

正如前文所述,成比例地改变ω和b会影响函数间隔,但不影响超平面,因此不妨通过调整ω和b使得函数间隔取值为1。同时,注意到最大化1/||ω||与最小化||ω||等价,因此,上式可以转化为如下形式:

目标函数的系数1/2仅仅是为了方便求导,无其他任何含义。通过利用拉格朗日对偶算法,求解上述约束最优化问题得到w和b,从而得到分类决策函数f(x)=sign(ωx+b)。基于分类决策函数可对测试数据集进行分类。
线性支持向量机
1、简介
线性支持向量机是针对线性不可分的数据集的,这样的数据集可以通过近似可分的方法实现分类。对于这样的数据集,类似线性可分支持向量机,通过求解对应的凸二次规划问题,也同样求得分离超平面:


2、线性支持向量机的原理
线性支持向量机的原始问题:


接下来的问题就变成如何求解这样一个最优化问题(称为原始问题)。
引入拉格朗日函数:

此时,原始问题即变成

利用拉格朗日函数的对偶性,将问题变成一个极大极小优化问题:

首先求解,将拉格朗日函数分别对
求偏导,并令其为0:

即为:

将其带入拉格朗日函数,即得:

第二步,求,即求:




这就是原始问题的对偶问题。
3、线性支持向量机的过程
(1)、设置惩罚参数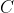 ,并求解对偶问题:
,并求解对偶问题:


假设求得的最优解为;
(2)、计算原始问题的最优解:

选择中满足
的分量,计算:

(3)、求分离超平面和分类决策函数:
分离超平面为:

分类决策函数为:

非线性支持向量机
1、适合场景
如果训练输入线性不可分,可以使用非线性支持向量机,利用核技巧将输入空间非线性问题转化到特征空间线性可分问题。

2、核函数的条件
设
对应的Gram矩阵

3、常用核函数
(1)多项式核函数


4、构建目标函数
SVM的对偶问题


假设 是上面问题的最优解,那么:
是上面问题的最优解,那么:



5、求最优解
要求解的最优化问题如下:

考虑使用序列最小最优化算法(SMO,sequential minimal optimization)
SVM--实现
SVM
# -*- coding: utf-8 -*-
# Mathieu Blondel, September 2010
# License: BSD 3 clause
import numpy as np
from numpy import linalg
import cvxopt
import cvxopt.solvers
def linear_kernel(x1, x2):
return np.dot(x1, x2)
def polynomial_kernel(x, y, p=3):
return (1 + np.dot(x, y)) ** p
def gaussian_kernel(x, y, sigma=5.0):
return np.exp(-linalg.norm(x-y)**2 / (2 * (sigma ** 2)))
class SVM(object):
def __init__(self, kernel=linear_kernel, C=None):
self.kernel = kernel
self.C = C
if self.C is not None: self.C = float(self.C)
def fit(self, X, y):
n_samples, n_features = X.shape
# Gram matrix
K = np.zeros((n_samples, n_samples))
for i in range(n_samples):
for j in range(n_samples):
K[i,j] = self.kernel(X[i], X[j])
P = cvxopt.matrix(np.outer(y,y) * K)
q = cvxopt.matrix(np.ones(n_samples) * -1)
A = cvxopt.matrix(y, (1,n_samples))
b = cvxopt.matrix(0.0)
if self.C is None:
G = cvxopt.matrix(np.diag(np.ones(n_samples) * -1))
h = cvxopt.matrix(np.zeros(n_samples))
else:
tmp1 = np.diag(np.ones(n_samples) * -1)
tmp2 = np.identity(n_samples)
G = cvxopt.matrix(np.vstack((tmp1, tmp2)))
tmp1 = np.zeros(n_samples)
tmp2 = np.ones(n_samples) * self.C
h = cvxopt.matrix(np.hstack((tmp1, tmp2)))
# solve QP problem
solution = cvxopt.solvers.qp(P, q, G, h, A, b)
# Lagrange multipliers
'''
数组的flatten和ravel方法将数组变为一个一维向量(铺平数组)。
flatten方法总是返回一个拷贝后的副本,
而ravel方法只有当有必要时才返回一个拷贝后的副本(所以该方法要快得多,尤其是在大数组上进行操作时)
'''
a = np.ravel(solution['x'])
# Support vectors have non zero lagrange multipliers
'''
这里a>1e-5就将其视为非零
'''
sv = a > 1e-5 # return a list with bool values
ind = np.arange(len(a))[sv] # sv's index
self.a = a[sv]
self.sv = X[sv] # sv's data
self.sv_y = y[sv] # sv's labels
print("%d support vectors out of %d points" % (len(self.a), n_samples))
# Intercept
'''
这里相当于对所有的支持向量求得的b取平均值
'''
self.b = 0
for n in range(len(self.a)):
self.b += self.sv_y[n]
self.b -= np.sum(self.a * self.sv_y * K[ind[n],sv])
self.b /= len(self.a)
# Weight vector
if self.kernel == linear_kernel:
self.w = np.zeros(n_features)
for n in range(len(self.a)):
# linear_kernel相当于在原空间,故计算w不用映射到feature space
self.w += self.a[n] * self.sv_y[n] * self.sv[n]
else:
self.w = None
def project(self, X):
# w有值,即kernel function 是 linear_kernel,直接计算即可
if self.w is not None:
return np.dot(X, self.w) + self.b
# w is None --> 不是linear_kernel,w要重新计算
# 这里没有去计算新的w(非线性情况不用计算w),直接用kernel matrix计算预测结果
else:
y_predict = np.zeros(len(X))
for i in range(len(X)):
s = 0
for a, sv_y, sv in zip(self.a, self.sv_y, self.sv):
s += a * sv_y * self.kernel(X[i], sv)
y_predict[i] = s
return y_predict + self.b
def predict(self, X):
return np.sign(self.project(X))
if __name__ == "__main__":
import pylab as pl
def gen_lin_separable_data():
# generate training data in the 2-d case
mean1 = np.array([0, 2])
mean2 = np.array([2, 0])
cov = np.array([[0.8, 0.6], [0.6, 0.8]])
X1 = np.random.multivariate_normal(mean1, cov, 100)
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 100)
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def gen_non_lin_separable_data():
mean1 = [-1, 2]
mean2 = [1, -1]
mean3 = [4, -4]
mean4 = [-4, 4]
cov = [[1.0,0.8], [0.8, 1.0]]
X1 = np.random.multivariate_normal(mean1, cov, 50)
X1 = np.vstack((X1, np.random.multivariate_normal(mean3, cov, 50)))
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 50)
X2 = np.vstack((X2, np.random.multivariate_normal(mean4, cov, 50)))
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def gen_lin_separable_overlap_data():
# generate training data in the 2-d case
mean1 = np.array([0, 2])
mean2 = np.array([2, 0])
cov = np.array([[1.5, 1.0], [1.0, 1.5]])
X1 = np.random.multivariate_normal(mean1, cov, 100)
y1 = np.ones(len(X1))
X2 = np.random.multivariate_normal(mean2, cov, 100)
y2 = np.ones(len(X2)) * -1
return X1, y1, X2, y2
def split_train(X1, y1, X2, y2):
X1_train = X1[:90]
y1_train = y1[:90]
X2_train = X2[:90]
y2_train = y2[:90]
X_train = np.vstack((X1_train, X2_train))
y_train = np.hstack((y1_train, y2_train))
return X_train, y_train
def split_test(X1, y1, X2, y2):
X1_test = X1[90:]
y1_test = y1[90:]
X2_test = X2[90:]
y2_test = y2[90:]
X_test = np.vstack((X1_test, X2_test))
y_test = np.hstack((y1_test, y2_test))
return X_test, y_test
# 仅仅在Linears使用此函数作图,即w存在时
def plot_margin(X1_train, X2_train, clf):
def f(x, w, b, c=0):
# given x, return y such that [x,y] in on the line
# w.x + b = c
return (-w[0] * x - b + c) / w[1]
pl.plot(X1_train[:,0], X1_train[:,1], "ro")
pl.plot(X2_train[:,0], X2_train[:,1], "bo")
pl.scatter(clf.sv[:,0], clf.sv[:,1], s=100, c="g")
# w.x + b = 0
a0 = -4; a1 = f(a0, clf.w, clf.b)
b0 = 4; b1 = f(b0, clf.w, clf.b)
pl.plot([a0,b0], [a1,b1], "k")
# w.x + b = 1
a0 = -4; a1 = f(a0, clf.w, clf.b, 1)
b0 = 4; b1 = f(b0, clf.w, clf.b, 1)
pl.plot([a0,b0], [a1,b1], "k--")
# w.x + b = -1
a0 = -4; a1 = f(a0, clf.w, clf.b, -1)
b0 = 4; b1 = f(b0, clf.w, clf.b, -1)
pl.plot([a0,b0], [a1,b1], "k--")
pl.axis("tight")
pl.show()
def plot_contour(X1_train, X2_train, clf):
# 作training sample数据点的图
pl.plot(X1_train[:,0], X1_train[:,1], "ro")
pl.plot(X2_train[:,0], X2_train[:,1], "bo")
# 做support vectors 的图
pl.scatter(clf.sv[:,0], clf.sv[:,1], s=100, c="g")
X1, X2 = np.meshgrid(np.linspace(-6,6,50), np.linspace(-6,6,50))
X = np.array([[x1, x2] for x1, x2 in zip(np.ravel(X1), np.ravel(X2))])
Z = clf.project(X).reshape(X1.shape)
# pl.contour做等值线图
pl.contour(X1, X2, Z, [0.0], colors='k', linewidths=1, origin='lower')
pl.contour(X1, X2, Z + 1, [0.0], colors='grey', linewidths=1, origin='lower')
pl.contour(X1, X2, Z - 1, [0.0], colors='grey', linewidths=1, origin='lower')
pl.axis("tight")
pl.show()
def test_linear():
X1, y1, X2, y2 = gen_lin_separable_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM()
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_margin(X_train[y_train==1], X_train[y_train==-1], clf)
def test_non_linear():
X1, y1, X2, y2 = gen_non_lin_separable_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM(gaussian_kernel)
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_contour(X_train[y_train==1], X_train[y_train==-1], clf)
def test_soft():
X1, y1, X2, y2 = gen_lin_separable_overlap_data()
X_train, y_train = split_train(X1, y1, X2, y2)
X_test, y_test = split_test(X1, y1, X2, y2)
clf = SVM(C=0.1)
clf.fit(X_train, y_train)
y_predict = clf.predict(X_test)
correct = np.sum(y_predict == y_test)
print("%d out of %d predictions correct" % (correct, len(y_predict)))
plot_contour(X_train[y_train==1], X_train[y_train==-1], clf)
# test_soft()
# test_linear()
test_non_linear()运行结果


Python机器学习算法 — 支持向量机(SVM)的更多相关文章
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- python机器学习之支持向量机SVM
支持向量机SVM(Support Vector Machine) 关注公众号"轻松学编程"了解更多. [关键词]支持向量,最大几何间隔,拉格朗日乘子法 一.支持向量机的原理 Sup ...
- Python机器学习笔记:SVM(1)——SVM概述
前言 整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思 ...
- 机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html 1. 解决 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 【机器学习】支持向量机SVM
关于支持向量机SVM,这里也只是简单地作个要点梳理,尤其是要注意的是SVM的SMO优化算法.核函数的选择以及参数调整.在此不作过多阐述,单从应用层面来讲,重点在于如何使用libsvm,但对其原理算法要 ...
- Python机器学习算法 — 关联规则(Apriori、FP-growth)
关联规则 -- 简介 关联规则挖掘是一种基于规则的机器学习算法,该算法可以在大数据库中发现感兴趣的关系.它的目的是利用一些度量指标来分辨数据库中存在的强规则.也即是说关联规则挖掘是用于知识发现,而非预 ...
- Python机器学习算法 — KNN分类
KNN简介 K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.KNN分类算法属于监督学习. 最简单最初级的分类器是将全部的训练 ...
随机推荐
- lua报错,看到报错信息有tail call,以为和尾调用有关,于是查了一下相关知识
尾调用是指在函数return时直接将被调函数的返回值作为调用函数的返回值返回,尾调用在很多语言中都可以被编译器优化, 基本都是直接复用旧的执行栈, 不用再创建新的栈帧, 原理上其实也很简单, 因为尾调 ...
- 总结:常用的Linux系统监控命令(2)
判断I/O瓶颈 mpstat命令 命令:mpstat -P ALL 1 1000 结果显示: 注意一下这里面的%iowait列,CPU等待I/O操作所花费的时间.这个值持续很高通常可能是I/O瓶颈所导 ...
- android开发里跳过的坑——“org.apache.http.message.BasicHeaderValueFormatter.INSTANCE”错误
在android4.4.2的系统里,写了一个系统应用,其中有一个功能是通过表单上传图片的,使用了httpclient-4.5.3.jar httpmime-4.5.3.jar httpcore-4.4 ...
- POJ 2431 Expedition【贪心】
题意: 卡车每走一个单元消耗一升汽油,中途有加油站,可以进行加油,问能否到达终点,求最少加油次数. 分析: 优先队列+贪心 代码: #include<iostream> #include& ...
- JDBC的Statement对象
以下内容引用自http://wiki.jikexueyuan.com/project/jdbc/statements.html: 一旦获得了数据库的连接,就可以和数据库进行交互.JDBC的Statem ...
- Spring Boot为我们准备了最佳的数据库连接池方案,只需要在属性文件(例如application.properties)中配置需要的连接池参数即可。
Spring Boot为我们准备了最佳的数据库连接池方案,只需要在属性文件(例如application.properties)中配置需要的连接池参数即可.
- component and slot
component and slot 使用: 1.component panel <article class="message"> <div class=&qu ...
- 将github上的项目源码导入eclipse详细教程
将github上的项目源码导入eclipse详细教程 学习了: http://blog.csdn.net/itbiggod/article/details/78462720
- POJ 3370 Halloween treats(抽屉原理)
Halloween treats Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 6631 Accepted: 2448 ...
- 软考之J2SE
特别感谢软考让我如今就接触了神奇的java.曾经尽管真不知道java是个神马,看完马士兵的视频发现里面的东西并不陌生.有vb,c++,c#做基础加上这次的J2SE发现原来编程语言有非常多同样的特性.也 ...