re(正则表达式)模块
一、最常用的匹配语法
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'\Z' 匹配字符结尾,同$'\d' 匹配数字0-9'\D' 匹配非数字'\w' 匹配[A-Za-z0-9]'\W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t''(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}import re
a = 'abc+10 + 20'
b = 'abc+10+20'
regex1 = re.compile('\d+\s*[+]\s*\d+') #对正则表达式进行编译,\d+表示匹配一个或多个数字,\s*表示匹配0个或多个空格,[]里面为字符集
print(regex1.search(a).group()) #匹配字符串 结果:10 + 20,对匹配该算术表达式来说,如果这里换成\s+则匹配不到,如果\d+换成\d*则会匹配到你不想匹配到的结果
print(regex1.search(b).group()) #结果:10+20 上述的python表示方式也可以这么表示
print(re.search('\d+\s*[+]\s*\d+',a).group())等同于先进行编译,再匹配
3、?一般搭配*、+、{}使用
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
python结果:
a = 'aabab'
regex1 = re.compile(r'a.*?b')
regex2 = re.compile(r'a.*b') print(regex1.findall(a)) ->['aab', 'ab'] ->这里用search的话只能找到aab
print(regex2.findall(a)) ->['aabab']
"*?" 重复任意次,但尽可能少重复
如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
"+?" 重复1次或更多次,但尽可能少重复
与上面一样,只是至少要重复1次
"??" 重复0次或1次,但尽可能少重复
如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
"{n,m}?" 重复n到m次,但尽可能少重复
如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
"{n,}?" 重复n次以上,但尽可能少重复
如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
4、groups与()搭配使用
a = 'abc+10+20'
regex1 = re.compile(r'(\d+)([+])(\d+)')
print(regex1.search(a).groups()) ->('10', '+', '20') 能把分组的数据一一取出来
5、^与&
如:匹配以数字开头以数字结尾
a = '1abc+10+20'
regex1 = re.compile(r'^\d.*\d$')
print(regex1.search(a).group()) ->1abc+10+20,如果不是以数字开头和数字结尾则匹配不到
6、groupdict与()搭配使用
print(re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict() ) -> {'province': '3714', 'city': '81', 'birthday': '1993'}
7、split使用
- a = '1abc+10+20'
- regex1 = re.compile(r'\+')
- print(regex1.split(a)) ->['1abc', '10', '20']
上述2、3步骤相当于
print(re.split(r'\+',a))
8、sub使用
*号替换+号
- a = '1abc+10+20'
- regex1 = re.compile(r'\+')
- print(regex1.sub('*',a)) ->1abc*10*20,后面可以加count来确保匹配多少次
上述2、3步骤相当于
#print(re.sub(r'\+','*',a)) ->1abc*10*20
9、反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
10^与[]搭配 [^abc]匹配除了abc之外的任意字符
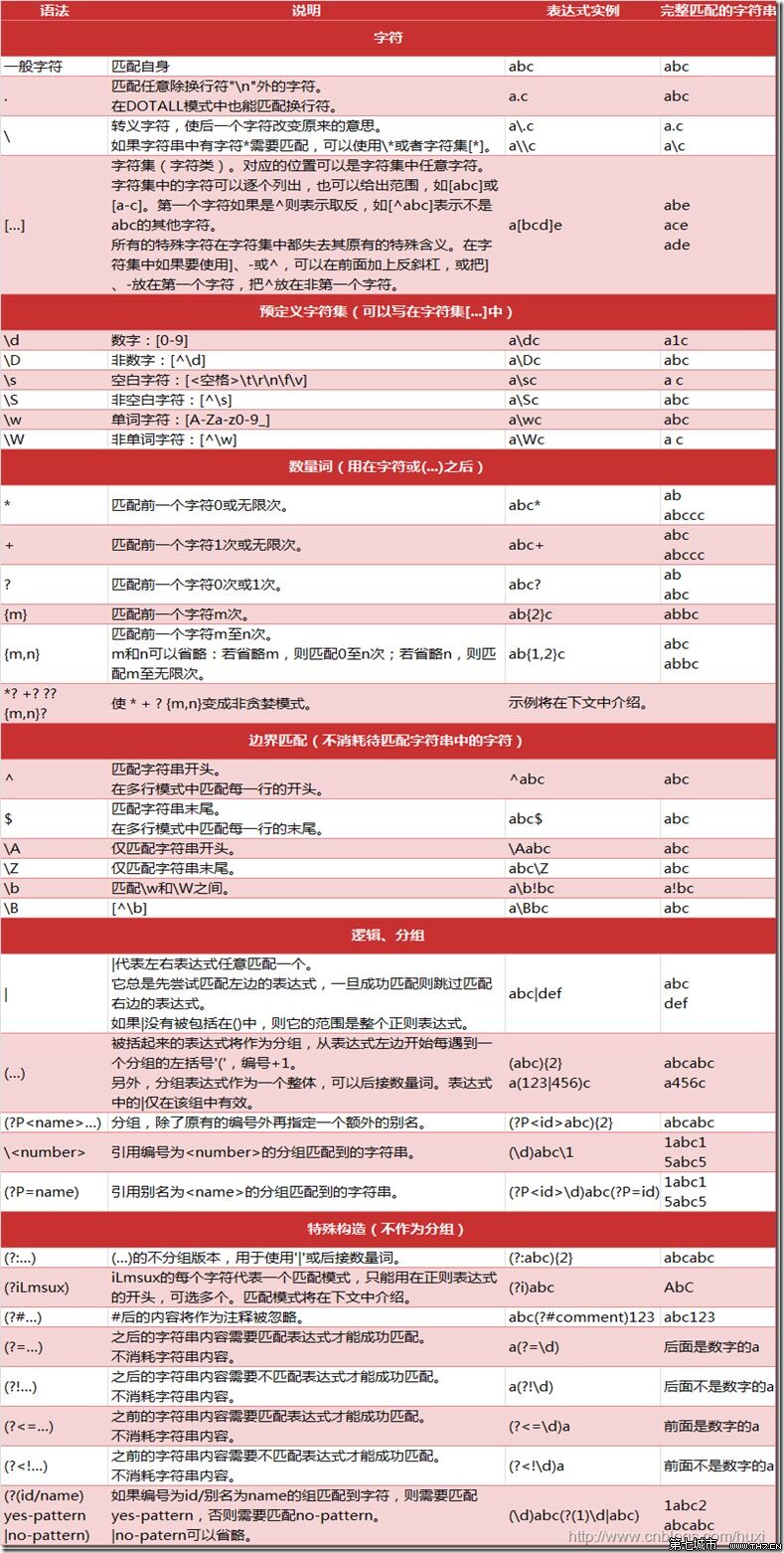
最后在添加一个图表
re(正则表达式)模块的更多相关文章
- Python正则表达式模块(re模块)
Python是我接触到的第一门编程语言,虽然它足够简单,但是对于当时刚刚接触编程语言的我来说还是有些难度的,于是只是了解了一些Python的基本语法,稍微深入一点的地方都没怎么了解.不过,到现在为止, ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- Python数据分析学习-re正则表达式模块
正则表达式 为高级的文本模式匹配.抽取.与/或文本形式的搜索和替换功能提供了基础.简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于 ...
- Python 正则表达式模块 (re) 简介
Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使用这一内嵌于 Python 的语言工具,尽管不能 ...
- Python编程中 re正则表达式模块 介绍与使用教程
Python编程中 re正则表达式模块 介绍与使用教程 一.前言: 这篇文章是因为昨天写了一篇 shell script 的文章,在文章中俺大量调用多媒体素材与网址引用.这样就会有一个问题就是:随着俺 ...
- python正则表达式模块
正则表达式是对字符串的最简约的规则的表述.python也有专门的正则表达式模块re. 正则表达式函数 释义 re.match() 从头开始匹配,匹配失败返回None,匹配成功可通过group(0)返回 ...
- python的re正则表达式模块学习
python中re模块的用法 Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,在文本解析.复杂字符串分析和信息提取时是一个非常有用的工 ...
- python正则表达式模块re
正则表达式的特殊元素 匹配符号 描述 '.'(点dot) 在默认模式下,它匹配除换行符之外的任何字符.如果指定了DOTALL标志,则匹配包括换行符在内的任何字符 '^'(Caret) 匹配以字符串开头 ...
- python re(正则表达式模块)学习
一.简介 正则表达式本身是一种小型的.高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配.正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎 ...
- python正则表达式模块re:正则表达式常用字符、常用可选标志位、group与groups、match、search、sub、split,findall、compile、特殊字符转义
本文内容: 正则表达式常用字符. 常用可选标志位. group与groups. match. search. sub. split findall. compile 特殊字符转义 一些现实例子 首发时 ...
随机推荐
- python--爬取http://www.kuaidaili.com/并保存为xls
代码如下: 复制在python3上先试试吧^_^ # -*- coding: utf-8 -*- """ Created on Mon Jun 12 13:27:59 2 ...
- python学习之-requests模块基础
安装版本:2.18 模块导入:import requests l 发送请求 发送GET请求: 获取GITHUB的公共时间线 r = requests.get(url='https://api.git ...
- [bzoj3709][PA2014]Bohater_贪心
bzoj-3709 PA-2014 Bohater 题目大意:在一款电脑游戏中,你需要打败n只怪物(从1到n编号).为了打败第i只怪物,你需要消耗d[i]点生命值,但怪物死后会掉落血药,使你恢复a[i ...
- T1079 回家 codevs
http://codevs.cn/problem/1079/ 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 白银 Silver~死坑 题目描述 Description 现在是晚 ...
- Jetson TK1 二:usb无线网卡的使用
一.总体是按照群里的文档“TK1连接无线网络”的步骤操作的,但也遇到了一些问题,如下: 1.自动配置设备并下载内核源代码到指定的目录下时(估计是解压时),出现时间超前之类的问题,原因是当前本地时间是几 ...
- 解决filter拦截request中body内容后,字符流关闭,无法传到controller的问题
解决filter拦截request中body内容后,字符流关闭,无法传到controller的问题 2.问题: 在一般的请求中,content-type为:application/x-www-form ...
- OHIFViewer meteor build 问题
D:\Viewers-master\OHIFViewer>meteor build --directory d:/h2zViewerC:\Users\h2z\AppData\Local\.met ...
- 安装ftp服务器
Linux安装ftp组件 1 安装vsftpd组件 安装完后,有/etc/vsftpd/vsftpd.conf文件,是vsftp的配置文件. [root@bogon ~]# yum -y insta ...
- ubuntu 16.04 更新后搜狗输入法无法输入中文的问题
方法一:重启搜狗输入法 通过下面的两个命令重启搜狗输入法,看重启后是否可以正常使用: ~$ killall fcitx ~$ killall sogou-qinpanel 方法二:检查修复安装依 ...
- Loadrunner IP欺骗
一.为什么要设置IP欺骗 1. 当某个IP的訪问过于频繁,或者訪问量过大时,server会拒绝訪问请求.这时候通过IP欺骗能够添加訪问频率和訪问量,以达到压力測试的效果. 2. 某些server配置了 ...