个推 Spark实践教你绕过开发那些“坑”
Spark作为一个开源数据处理框架,它在数据计算过程中把中间数据直接缓存到内存里,能大大提高处理速度,特别是复杂的迭代计算。Spark主要包括SparkSQL,SparkStreaming,Spark MLLib以及图计算。
Spark核心概念简介
1、RDD即弹性分布式数据集,通过RDD可以执行各种算子实现数据处理和计算。比如用Spark做统计词频,即拿到一串文字进行WordCount,可以把这个文字数据load到RDD之后,调用map、reducebyKey 算子,最后执行count动作触发真正的计算。
2、宽依赖和窄依赖。工厂里面有很多流水线,一款产品上游有一个人操作,下游有人进行第二个操作,窄依赖和这个很类似,下游依赖上游。而所谓宽依赖类似于有多条流水线,A流水线的一个操作是需要依赖一条流水线B,才可以继续执行,要求两条流水线之间要做材料运输,做协调,但效率低。
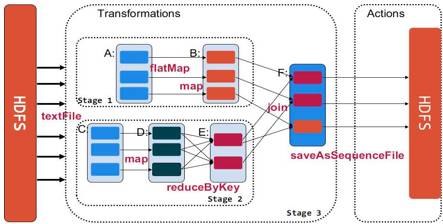
从上图可以看到,如果B只依赖A则是一种窄依赖。像图中这种reduceByKey的操作,就是刚刚举例的宽依赖,类似于多条流水线之间某一些操作相互依赖,如:F对E、B的依赖。宽依赖最大的问题是会导致洗牌过程。
Spark Streaming介绍
流式计算,即数据生成后,实时对数据进行处理。Spark 是一个批处理框架,那它如何实现流式处理?Spark 是把数据裁成一段一段的处理,即一个数据流离散化成许多个连续批次,然后Spark对每个批次进行处理。

个推为什么选择Spark
1、Spark 比较适合迭代计算,解决我们团队在之前使用hadoop mapreduce迭代数据计算这一块的瓶颈。
2、Spark是一个技术栈,但可以做很多类型的数据处理:批处理,SQL,流式处理以及ML等,基本满足我们团队当时的诉求。
3、它的API抽象层次非常高,通过使用map、reduce、groupby等多种算子可快速实现数据处理,极大降低开发成本,并且灵活。另外Spark框架对于多语言支持也是非常好,很多负责数据挖掘算法同学对于python 熟悉,而工程开发的同学熟悉java, 多语言支持可以把开发和分析的同学快速地引入过来。
4、在2014年的时候,我们用hadoop Yarn,而Spark可以在Yarn部署起来,使用Spark大大降低了切换成本,并且可以把之前的hadoop资源利用起来。
5、Spark在社区很火,找资料非常方便。
个推数据处理架构

上图是一个典型的lambda架构。主要分三层。上面蓝色的框,是做离线批量处理,下面一层是实时数据处理这一块,中间这一层是对于结果数据做一些存储和检索。
有两种方式导入数据到HDFS,一部分数据从业务平台日志收集写入到 Kafka,然后直接Linkedin Camus(我们做过扩展) 准实时地传输到 HDFS,另外部分数通过运维那边的脚本定时导入到 HDFS 上。
离线处理部分我们还是使用两个方式(Hadoop MR 和 Spark)。原有的hadoop MR没有放弃掉, 因为原来很多的工程已经是用MR做的了,非常稳定,没有必要推倒重来,只有部分迭代任务使用Spark 重新实现。另外Hive是直接可以跟Spark做结合,Spark Sql中就可以使用Hive的命令 。
个推Spark集群的部署状况
个推最开始用Spark是1.3.1版本,用的是刀片服务器,就是刀框里面可以塞 16 个刀片服务器,单个内存大小192G, CPU 核数是24 核的。在Spark官方也推荐用万兆网卡,大内存设备。我们权衡了需求和成本后,选择了就用刀片机器来搭建 Spark集群。刀框有个好处就是通过背板把刀片机器连接起来,传输速度快,相对成本小。部署模式上采用的是 Spark on Yarn,实现资源复用。
Spark 在个推业务上的具体使用
1、个推做用户画像、模型迭代以及一些推荐的时候直接用了MLLib,MLLib集成了很多算法,非常方便。
2、个推有一个BI工具箱,让一些运营人员提取数据,我们是用Spark SQL+Parquet格式宽表实现,Parquet是列式存储格式,使用它你不用加载整个表,只会去加载关心那些字段,大大减少IO消耗。
3、实时统计分析这块:例如个推有款产品叫个图,就是使用Spark streaming 来实时统计。
4、复杂的 ETL 任务我们也使用 Spark。例如:我们个推推送报表这一块,每天需要做很多维度的推送报表统计。使用 Spark 通过 cache 中间结果缓存,然后再统计其他维度,大大地减少了 I/O 消耗,显著地提升了统计处理速度。
个推Spark实践案例分享
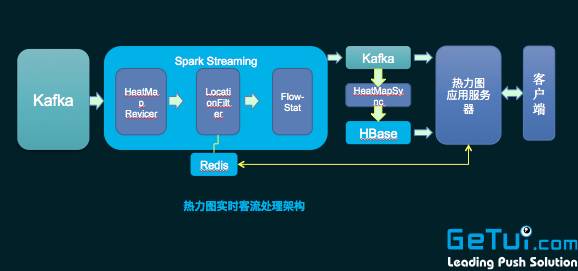
上图是个推热力图的处理架构。左边这一侧利用业务平台得到设备的实时位置数据,通过Spark Streaming以及计算得到每一个geohash格子上的人数,然后统计结果实时传输给业务服务层,在push到客户端地图上面去渲染,最终形成一个实时热力图。Spark Streaming 主要用于数据实时统计处理上。
个推教你绕过开发那些坑
1、数据处理经常出现数据倾斜,导致负载不均衡的问题,需要做统计分析找到倾斜数据特征,定散列策略。
2、使用Parquet列式存储,减少IO,提高Spark SQL效率。
3、实时处理方面:一方面要注意数据源(Kafka)topic需要多个partition,并且数据要散列均匀,使得Spark Streaming的Recevier能够多个并行,并且均衡地消费数据 。使用Spark Streaming,要多通过Spark History 排查DStream的操作中哪些处理慢,然后进行优化。另外一方面我们自己还做了实时处理的监控系统,用来监控处理情况如流 入、流出数据速度等。通过监控系统报警,能够方便地运维Spark Streaming 实时处理程序。这个小监控系统主要用了 influxdb+grafana 等实现。
4、我们测试网经常出现找不到第三方jar的情况,如果是用CDH的同学一般会遇到,就是在CDH 5.4开始,CDH的技术支持人员说他们去掉了hbase等一些jar,他们认那些jar已经不需要耦合在自己的classpath中,这个情况可以通过spark.executor.extraClassPath方式添加进来。
5、一些新入门的人会遇到搞不清transform和action,没有明白transform是lazy的,需要action触发,并且两个action前后调用效果可能不一样。
6、大家使用过程当中,对需要重复使用的RDD,一定要做cache,性能提升会很明显。
个推 Spark实践教你绕过开发那些“坑”的更多相关文章
- PWA 推送实践
PWA 推送实践 最近公司内录任务的系统总是忘记录任务,而那个系统又没有通知,所以想要实现一个浏览器的通知功能,免得自己忘记录入任务. 前端实现通知的几种方式 想要实现通知,我们就需要有个客户端,对于 ...
- Xamarin Anroid开发教程之Anroid开发工具及应用介绍
Xamarin Anroid开发教程之Anroid开发工具及应用介绍 Xamarin开发Anroid应用介绍 如今智能手机已经盛行了好几年,而针对这些智能手机的软件开发也变得异常火热.但是在Andro ...
- HealthKit开发快速入门教程之HealthKit开发概述简介
HealthKit开发快速入门教程之HealthKit开发概述简介 2014年6月2日召开的年度开发者大会上,苹果发布了一款新的移动应用平台,可以收集和分析用户的健康数据.该移动应用平台被命名为“He ...
- 【基于spark IM 的二次开发笔记】第一天 各种配置
[基于spark IM 的二次开发笔记]第一天 各种配置 http://juforg.iteye.com/blog/1870487 http://www.igniterealtime.org/down ...
- Spark Standalone模式应用程序开发
作者:过往记忆 | 新浪微博:左手牵右手TEL | 能够转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明博客地址:http://www.iteblog.com/文章标题:<Spar ...
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Playmaker全面实践教程之Playmaker常用工具
Playmaker全面实践教程之Playmaker常用工具 Playmaker常用工具 Playmaker插件搭载了8个工具:FSM Browser.State Browser.Templates.T ...
- Playmaker全面实践教程之playMaker编辑器
Playmaker全面实践教程之playMaker编辑器 playMaker编辑器 playMaker编辑器是制作状态机的主要视图,如图1-23所示.只有熟悉此视图,读者才能更加快捷的使用Playma ...
随机推荐
- 仿jQuery之链式调用
链式调用的形式其实就是对象调用一连串的方法.为什么能连续调用这么多的方法?因为调用方法返回调用的对象,于是乎就可以一如既往,一往无前地调用下去.链式调用的原理就是在方法中返回执行上下文this,每次调 ...
- SVN和Git的一些用法总结(转)
转载请注明出处:http://www.codelast.com/ 以下都是比较基础的操作,高手们请绕道,不必浪费时间来看了. (A)SVN (1)查看日志提交的时候一般会写上注释,如果要查看提交日志, ...
- 比列的数目更多,以便找到第一k小值
问题叙述性说明:现有n作为一个有序序列(2,3,9),(3,5,11,23),(1,4,7,9,15,17,20),(8,15,35,9),(20,30,40),第k小值. 问题分析:可用多路归并排序 ...
- 汉高澳大利亚sinox接口捆绑经典winxp,全面支持unicode跨语言处理
用qtconfig(或者qtconfig-qt4)设置字体后,汉澳sinox视窗界面以跟winxp媲美的界面出现,爽心悦目. 并且视窗使用非常稳定.非常少出现死机无响应现象,堪称完美. 引入unico ...
- Microservice架构模
Microservice架构模 在2014年,Sam Newman,Martin Fowler在ThoughtWorks的一位同事,出版了一本新书<Building Microservices& ...
- Android环境结构Android Studio解决方法不能启动,第一次
android Studio 下载和eclipse 的android开发环境的搭建下载包: 联系: http://pan.baidu.com/s/1kTKJZkN password: qxqf And ...
- CSS浏览器兼容性问题集()两
11.非常适合 高度适合于被改变时所述内目标高度的外层的高度不能自己主动调节,尤其是排队对象时margin 要么paddign 时. 例: #box {background-color:#e ...
- DM8168 layout
我们学到了以前的系统板的教训,新的版本号DM8168烤... 一级:电源.DM8168.DDR3.FPGA.CPLD.Nandflash.USB.以太网络.SATA.JTAG等待. 的地面电源部充分. ...
- java_eclipse_maven_svn_主题彩色插件_全屏插件
作为一名不算新手的猿猿,还来纠结IDE环境搭建实属不该,不过着实纠结了不少时间. target: eclipse + maven +svn + 设置默认编码+全屏 绕的路就不说了,直奔主题,由于mav ...
- 【SSH三大框架】Hibernate基础第六篇:多对一关联关系的映射、分析及加入、查询
这里举样例用的是:部门与员工的关系. 一个部门能够相应多个员工,这就是非常明显的多对一关联关系. 我们须要建立两个实体类:员工(Employee).部门(Department) 员工类:Employe ...