Kafka优雅应用
Kafka API实战
注意版本问题这个,kafka-client要和kafka的版本一致
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.7.0</version>
</dependency>
//Producer
package com.study.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
/**
* @Auther: allen
* @Date: 2019/2/17 16:05
*/
public class ProducerNew {
private final KafkaProducer<String, String> producer;
private final String topic;
public ProducerNew(String topic, String[] args) {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "192.168.100.246:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 一批消息处理大小
props.put("batch.size", 16384);//16M
// 请求延时
props.put("linger.ms", 10);
// 发送缓存区内存大小
props.put("buffer.memory", 33554432);//32M
// 使用自定义分区器,如果自定义则适用默认的 DefaultPartitioner,可以在ProducerConfig里面设置参数
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.study.kafka.partition.MySamplePartitioner");
// key和value的序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<>(props);
this.topic = topic;
}
public void producerMsg() throws InterruptedException {
String data = "Apache Storm is a free and open source distributed realtime computation system Storm makes it easy to reliably process unbounded streams of data doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language, and is a lot of fun to use!\n" +
"Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.\n" +
"Storm integrates with the queueing and database technologies you already use. A Storm topology consumes streams of data and processes those streams in arbitrarily complex ways, repartitioning the streams between each stage of the computation however needed. Read more in the tutorial.";
data = data.replaceAll("[\\pP‘’“”]", "");
String[] words = data.split(" ");
Random _rand = new Random();
Random rnd = new Random();
int events = 10;
for (long nEvents = 0; nEvents < events; nEvents++) {
long runtime = System.currentTimeMillis();
int lastIPnum = rnd.nextInt(255);
String ip = "172.16.20." + lastIPnum;
String msg = words[_rand.nextInt(words.length)];
try {
producer.send(new ProducerRecord<>(topic, ip, msg));
System.out.println("Sent message: (" + ip + ", " + msg + ")");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ProducerNew producer = new ProducerNew("test", args);
producer.producerMsg();
Thread.sleep(20);
}
}
//Consumer
package com.study.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @Auther: allen
* @Date: 2019/2/17 16:06
*/
public class ConsumerNew {
private final KafkaConsumer<Integer, String> consumer;
private final String topic;
public ConsumerNew(String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.100.246:9092");
// 记住 consumer 是需要依赖zk的,cosumer需要把自己最后一次的消费信息提交给zookeeper进行维护,来告知消费到哪里
props.put("zookeeper.connect", "192.168.100.246:2181");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group-test");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// latest,earliest,none latest:读取最新的,earliest:从头开始
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
this.topic = topic;
}
public void consumerMsg(){
try {
consumer.subscribe(Collections.singletonList(this.topic));
//System.out.println(consumer.listTopics());
while(true){
ConsumerRecords<Integer, String> records = consumer.poll(2000);
for (ConsumerRecord<Integer, String> record : records) {
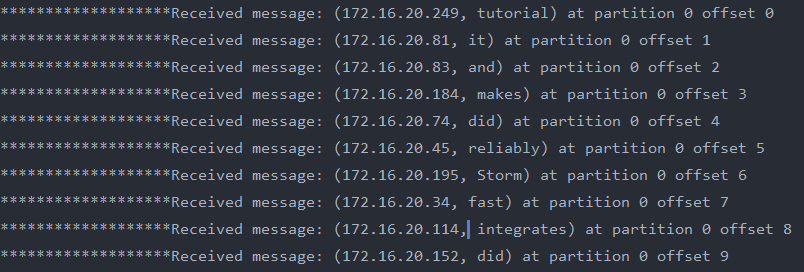
System.out.println("*******************Received message: (" + record.key() + ", " + record.value() + ") at partition "+record.partition()+" offset " + record.offset());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
ConsumerNew Consumer = new ConsumerNew("test");
Consumer.consumerMsg();
}
}
结果如下
springboot集成kafka
package com.study.springboot.producer;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.ProducerListener;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.util.Date;
import java.util.UUID;
/**
* @Auther: allen
* @Date: 2019/2/26 14:19
*/
@Component
public class Producer {
private static final Logger log = LoggerFactory.getLogger(Producer.class);
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
private static Gson gson = new GsonBuilder().create();
// 发送消息
public void sendMessage(Message message) {
log.info("kafka sendMessage start");
// 内部组织下消息
message.setId("KFK_"+System.currentTimeMillis());
message.setMsg(UUID.randomUUID().toString());
message.setSendTime(new Date());
try {
kafkaTemplate.send(kafkaTemplate.getDefaultTopic(), gson.toJson(message));
} catch (Exception e) {
log.error("发送数据出错!!!{}{}", kafkaTemplate.getDefaultTopic(), gson.toJson(message));
log.error("发送数据出错=====>", e);
}
// 消息发送的监听器,用于回调返回信息
kafkaTemplate.setProducerListener(new ProducerListener<String, String>() {
@Override
public void onSuccess(String topic, Integer partition, String key, String value, RecordMetadata recordMetadata) {
}
@Override
public void onError(String topic, Integer partition, String key, String value, Exception exception) {
}
@Override
public boolean isInterestedInSuccess() {
log.info("数据发送完毕");
return false;
}
});
log.info("kafka sendMessage end");
}
public void sendMessage(String topic, String data) {
log.info("kafka sendMessage start");
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable ex) {
log.error("kafka sendMessage error, ex = {}, topic = {}, data = {}", ex, topic, data);
}
@Override
public void onSuccess(SendResult<String, String> result) {
log.info("kafka sendMessage success topic = {}, data = {}",topic, data);
}
});
log.info("kafka sendMessage end");
}
}
package com.study.springboot.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @Auther: allen
* @Date: 2019/2/26 14:20
*/
@Component
public class Consumer {
@KafkaListener(topics = {"test2","test"})
public void processMessage(String content) {
System.out.println("消息被消费" + content);
}
}
Kafka producer 拦截器(interceptor)
https://www.cnblogs.com/huxi2b/p/7072447.html
Producer 拦截器(interceptor)是在 Kafka 0.10 版本被引入的,主要用于实现 clients 端的定制化控制逻辑。
对于 producer 而言,interceptor 使得用户在消息发送前以及producer 回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer 允许用户指定多个 interceptor 按序作用于同一条消息 从 而 形 成 一 个 拦 截 链 (interceptor chain) 。 Intercetpor 的 实 现 接 口 是org.apache.kafka.clients.producer.ProducerInterceptor
(1)configure(configs)
获取配置信息和初始化数据时调用。
(2)onSend(ProducerRecord):
该方法封装进 KafkaProducer.send 方法中,即它运行在用户主线程中。Producer 确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区,否则会影响目标分区的计算
(3)onAcknowledgement(RecordMetadata, Exception):
该方法会在消息被应答或消息发送失败时调用,并且通常都是在 producer 回调逻辑触发之前。onAcknowledgement 运行在 producer 的 IO 线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢 producer 的消息发送效率
(4)close:
关闭 interceptor,主要用于执行一些资源清理工作
如前所述,interceptor 可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个 interceptor,则 producer 将按照指定顺序调用它们,并仅仅是捕获每个 interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
案例
实现一个简单的双 interceptor 组成的拦截链。第一个 interceptor 会在消息发送前将时间戳信息加到消息 value 的最前部;第二个 interceptor 会在消息发送后更新成功发送消息数或失败发送消息数。

package com.study.kafka.interceptor;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* @Auther: allen
* @Date: 2019/2/17 11:58
*/
public class CounterInterceptor implements ProducerInterceptor<String, String> {
private int errorCounter = 0;
private int successCounter = 0;
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 统计成功和失败的次数
if (exception == null) {
successCounter++;
} else {
errorCounter++;
}
}
@Override
public void close() {
// 保存结果
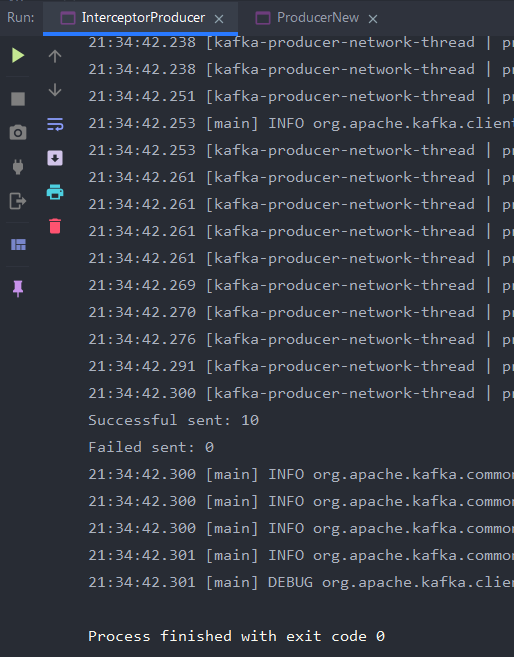
System.out.println("Successful sent: " + successCounter);
System.out.println("Failed sent: " + errorCounter);
}
}
package com.study.kafka.interceptor;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @Auther: allen
* @Date: 2019/2/17 12:01
*/
public class InterceptorProducer {
public static void main(String[] args) throws Exception {
// 1 设置配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.100.249:9092");
// 默认为1;当为all时候值为-1,表示所有的都需要同步(一致性最高相对性能也会有所降低)
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2 构建拦截链
List<String> interceptors = new ArrayList<>();
interceptors.add("com.study.kafka.interceptor.TimeInterceptor");
interceptors.add("com.study.kafka.interceptor.CounterInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
String topic = "test";
Producer<String, String> producer = new KafkaProducer<>(props);
// 3 发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic,"message" + i);
producer.send(record);
// message0 , -> 123129374927,message0
// 成功:
// 失败:
}
// 4 一定要关闭producer,这样才会调用interceptor的close方法
producer.close();
}
}
package com.study.kafka.interceptor;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* @Auther: allen
* @Date: 2019/2/17 11:57
*/
public class TimeInterceptor implements ProducerInterceptor<String, String> {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 创建一个新的record,把时间戳写入消息体的最前部
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(),
System.currentTimeMillis() + "," + record.value().toString());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
}
Partition分区机制——Kafka分区机制介绍与示例
Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex”的命名方式命名,该文件夹下存储这个分区的所有消息(.log)和索引文件(.index),这使得Kafka的吞吐率可以水平扩展。
生产者在生产数据的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区规则选择被存储到哪一个分区中,如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
另外,在消费者端,同一个消费组可以多线程并发的从多个分区中同时消费数据。
kafka---partitioner及自定义
如果消息的 key 为 null,此时 producer 会使用默认的 partitioner 分区器将消息随机分布到 topic 的可用 partition 中。
如果 key 不为 null,并且使用了默认的分区器,kafka 会使用自己的 hash 算法对 key 取 hash 值,使用 hash 值与 partition 数量取模,从而确定发送到哪个分区。
注意:此时 key 相同的消息会发送到相同的分区(只要 partition 的数量不变化)。
=== 默认的分区器的实现
1、DefaultPartitioner实现了Partitioner接口
2、分区算法的实现在这个方法中:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster, int numPartitions) {
return keyBytes == null ? this.stickyPartitionCache.partition(topic, cluster) : Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
3、如果我们需要实现自己的分区器,那么可以有2种方法
(1)新建一个包路径和DefaultPartitioner所在的路径一致,然后更改
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){…………}
方法体的内容,更改为我们自己的算法即可。
(2)新建一个类,实现Partitioner接口
package com.study.kafka.partition;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 定义Kafka分区器
*
* @Auther: allen
* @Date: 2019/2/22 14:33
*/
public class MySamplePartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(new Random().nextInt());
private Random random = new Random();
//我的分区器定义
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitioners = cluster.partitionsForTopic(topic);
int numPartitions = partitioners.size();
/**
* 由于我们按key分区,在这里我们规定:key值不允许为null。
* 在实际项目中,key为null的消息*,可以发送到同一个分区,或者随机分区。
*/
int res = 1;
if (keyBytes == null) {
System.out.println("value is null");
res = random.nextInt(numPartitions);
} else {
// System.out.println("value is " + value + "\n hashcode is " + value.hashCode());
res = Math.abs(key.hashCode()) % numPartitions;
}
System.out.println("data partitions is " + res);
return res;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
Kafka的扩容
增加机器,例如原来三台服务器的 kafka 集群增加两台机器成为有五台机器的 kafka 集群,跟搭建差不多
分区重新分配:在原来机器上的主题分区不会自动均衡到新的机器,需要使用分区重新分配工具来均衡均衡
重新分配官方文档地址:http://kafka.apache.org/documentation/#basic_ops_cluster_expansion
配置topic分区
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 2 --replication-factor 2 --config flush.messages=1
扩展topic分区
bin/kafka-topics.sh --zookeeper localhost:2181 --alert --topic test --partitions 3
1. Kafka集群partition replication默认自动分配分析
下面以一个Kafka集群中4个Broker举例,创建1个topic包含4个Partition,2 Replication;数据Producer流动如图所示:
(1)
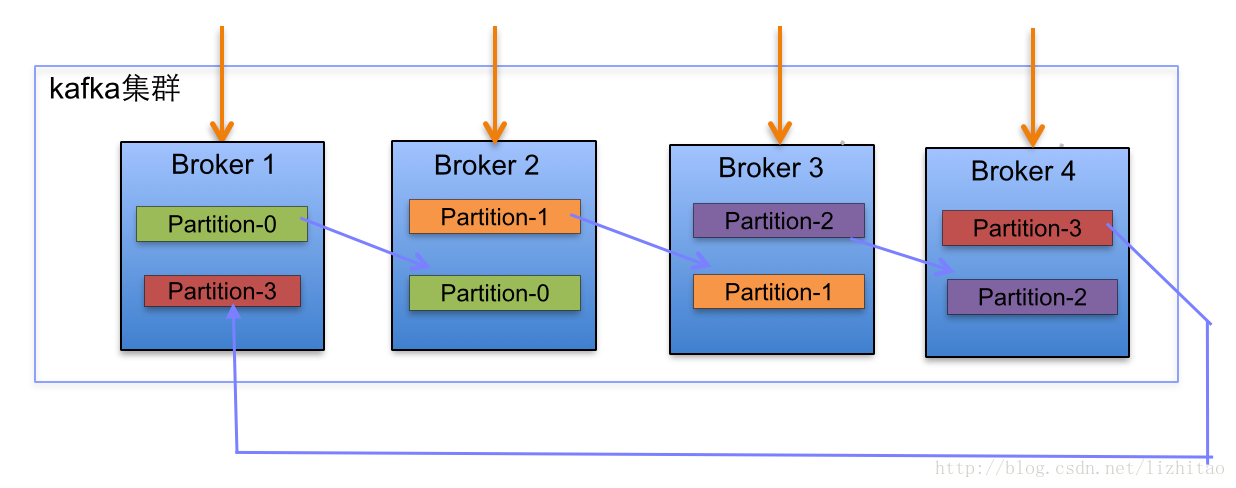
(2)当集群中新增2节点,Partition增加到6个时分布情况如下:
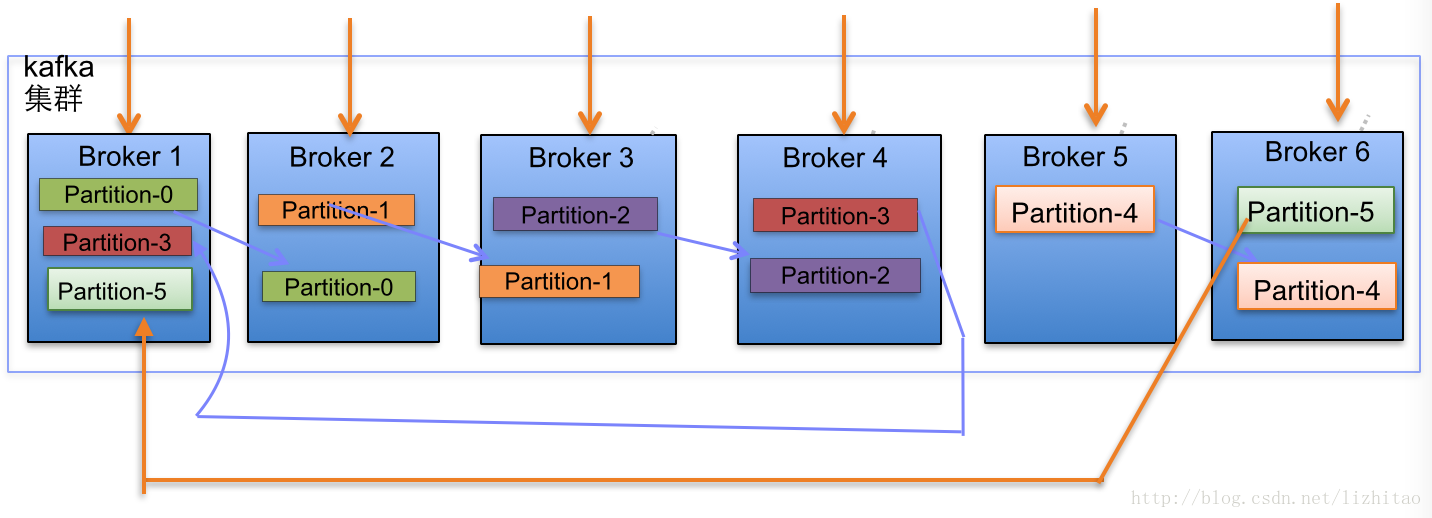
副本分配逻辑规则如下:
在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
副本分配算法如下:
将所有N Broker和待分配的i个Partition排序.
将第i个Partition分配到第(i mod n)个Broker上.
将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
2、Kafka的ISR机制

ISR(in sync replica)的含义是同步的replica,相对的就有out of sync replica,也就是跟不上同步节奏的replica
kafka的Replica
1.kafka的topic可以设置有N个副本(replica),副本数最好要小于broker的数量,也就是要保证一个broker上的replica最多有一个,所以可以用broker id指定Partition replica。
2.创建副本的单位是topic的分区,每个分区有1个leader和0到多个follower,我们把多个replica分为Lerder replica和follower replica。
3.当producer在向partition中写数据时,根据ack机制,默认ack=1,只会向leader中写入数据,然后leader中的数据会复制到其他的replica中,follower会周期性的从leader中pull数据,但是对于数据的读写操作都在leader replica中,follower副本只是当leader副本挂了后才重新选取leader,follower并不向外提供服务。
kafka的“同步”
kafka不是完全同步,也不是完全异步,是一种特殊的ISR(In Sync Replica)
1.leader会维持一个与其保持同步的replica集合,该集合就是ISR,每一个partition都有一个ISR,它时有leader动态维护。
2.我们要保证kafka不丢失message,就要保证ISR这组集合存活(至少有一个存活),并且消息commit成功。
所以我们判定存活的概念时什么呢?分布式消息系统对一个节点是否存活有这样两个条件判断:第一个,节点必须维护和zookeeper的连接,zookeeper通过心跳机制检查每个节点的连接;第二个,如果节点时follower,它必要能及时同步与leader的写操作,不是延时太久。
如果满足上面2个条件,就可以说节点时“in-sync“(同步中的)。leader会追踪”同步中的“节点,如果有节点挂了,卡了,或延时太久,那么leader会它移除,延时的时间由参数replica.log.max.messages决定,判断是不是卡住了,由参数replica.log.time.max.ms决定。
Kafka优雅应用的更多相关文章
- 从源码分析如何优雅的使用 Kafka 生产者
前言 在上文 设计一个百万级的消息推送系统 中提到消息流转采用的是 Kafka 作为中间件. 其中有朋友咨询在大量消息的情况下 Kakfa 是如何保证消息的高效及一致性呢? 正好以这个问题结合 Kak ...
- Kafka实战(七) - 优雅地部署 Kafka 集群
既然是集群,必然有多个Kafka节点,只有单节点构成的Kafka伪集群只能用于日常测试,不可能满足线上生产需求. 真正的线上环境需要考量各种因素,结合自身的业务需求而制定.看一些考虑因素(以下顺序,可 ...
- 读 Kafka 源码写优雅业务代码:配置类
这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一剑! 往期文章 Kafka 探险 ...
- Kafka实战系列--Kafka API使用体验
前言: kafka是linkedin开源的消息队列, 淘宝的metaq就是基于kafka而研发. 而消息队列作为一个分布式组件, 在服务解耦/异步化, 扮演非常重要的角色. 本系列主要研究kafka的 ...
- Apache Kafka源码分析 - KafkaApis
kafka apis反映出kafka broker server可以提供哪些服务,broker server主要和producer,consumer,controller有交互,搞清这些api就清楚了 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kakfa揭秘 Day3 Kafka源码概述
Kakfa揭秘 Day3 Kafka源码概述 今天开始进入Kafka的源码,本次学习基于最新的0.10.0版本进行.由于之前在学习Spark过程中积累了很多的经验和思想,这些在kafka上是通用的. ...
- Kafka官方文档翻译——设计
下面是博主的公众号,后续会发布和讨论一系列分布式消息队列相关的内容,欢迎关注. ------------------------------------------------------------ ...
- java优雅的使用elasticsearch api
本文给出一种优雅的拼装elasticsearch查询的方式,可能会使得使用elasticsearch的方式变得优雅起来,使得代码结构很清晰易读. 建立elasticsearch连接部分请参看另一篇博客 ...
随机推荐
- Python序列之列表(一)
在Python中,列表是一种常用的序列,接下来我来讲一下关于Python中列表的知识. 列表的创建 Python中有多种创建列表的方式 1.使用赋值运算符直接赋值创建列表 在创建列表时,我们直接使用赋 ...
- WPF -- DataTemplate与ControlTemplate结合使用
如深入浅出WPF中的描述,DataTemplate为数据的外衣,ControlTemplate为控件的外衣.ControlTemplate控制控件的样式,DataTemplate控制数据显示的样式,D ...
- gitlab和gitlab项目迁移
一.概述 原gitlab 操作系统:centos 6.9 版本:GitLab 社区版 10.5.1 安装方式:yum 新gitlab 操作系统:centos 7.6 版本:GitLab Communi ...
- PowerDesigner 设计数据库中常用脚本
PowerDesigner 设计数据库中常用脚本 数据库设计 物理模型设置 Name转Comment脚本 '********************************************** ...
- URL 地址解析
//虚拟目录的路径 Response.Write("<strong>Request.ApplicationPath:</strong>" + Request ...
- 从零学脚手架(二)---初识webpack
在上一篇中,介绍了 webpack 的 entry . output . plugins 属性. 在这一篇,接着介绍其它配置属性. mode 这个属性在上一篇中使用过一次:设置 webpack 编译模 ...
- 如何自学成 Python 大神?这里有些建议
人生苦短,我用 Python.为什么?简单明了的理由当然是开发效率高.但是学习 Python 的初学者往往会面临以下残酷的现状:网上充斥着大量的学习资源.书籍.视频教程和博客,但是大部分都是讲解基础知 ...
- Android - Handler原理
Handler的主要作用是收发消息和切线程 功能一:收发消息 简单流程介绍 希望你看完这篇文章后也可以把流程自己讲出来,并且每个环节还可以讲出很多细节 他的消息机制离不开Looper.MessageQ ...
- 【odoo14】第八章、服务侧开发-进阶
本章代码位于作为GITHUB库 https://github.com/PacktPublishing/Odoo-14-Development-Cookbook-Fourth-Edition 在第五章( ...
- 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(Unified API篇)
SDK 开发 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(理念与设计原则篇) 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(开发基础篇) 顶级开源项目 Sentry ...