Mongodb集群调研
一.高可用集群的解决方案
高可用性即HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。
计算机系统的高可用在不同的层面上有不同的表现:
1.网络高可用
由于网络存储的快速发展,网络冗余技术被不断提升,提高IT系统的高可用性的关键应用就是网络高可用性,网络高可用性与网络高可靠性是有区别的,网络高可用性是通过匹配冗余的网络设备实现网络设备的冗余,达到高可用的目的。
比如冗余的交换机,冗余的路由器等
2.服务器高可用
服务器高可用主要使用的是服务器集群软件或高可用软件来实现。
3.存储高可用
使用软件或硬件技术实现存储的高度可用性。其主要技术指标是存储切换功能,数据复制功能,数据快照功能等。当一台存储出现故障时,另一台备用的存储可以快速切换,达一存储不停机的目的。
二.MongoDB的高可用集群配置
高可用集群,即High Availability Cluster,简称HA Cluster。
集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。
这些单个的计算机系统 就是集群的节点(node)。
搭建高可用集群需要合理的配置多台计算机之间的角色,数据恢复,一致性等,主要有以下几种方式:
1.主从方式 (非对称方式)
主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行,数据的一致性通过共享存储系统解决。
2.双机双工方式(互备互援)
两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,保证工作实时,应用服务系统的关键数据存放在共享存储系统中。
3.集群工作方式(多服务器互备方式)
多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管。
MongoDB集群配置的实践也遵循了这几个方案,主要有主从结构,副本集方式和Sharding分片方式。
三.Mongo集群实现高可用方式详解
1.Master-slave主从模式
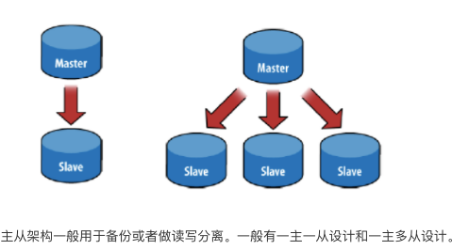
由两种角色构成:
(1)主(Master)
可读可写,当数据有修改的时候,会将oplog同步到所有连接的salve上去。
(2)从(Slave)
只读不可写,自动从Master同步数据。
特别的,对于Mongodb来说,并不推荐使用Master-Slave架构,因为Master-Slave其中Master宕机后不能自动恢复,推荐使用Replica Set,后面会有介绍,除非Replica的节点数超过50,才需要使用Master-Slave架构,正常情况是不可能用那么多节点的。
还有一点,Master-Slave不支持链式结构,Slave只能直接连接Master。Redis的Master-Slave支持链式结构,Slave可以连接Slave,成为Slave的Slave。
2.Relica Set副本集方式
Mongodb的Replica Set即副本集方式主要有两个目的,一个是数据冗余做故障恢复使用,当发生硬件故障或者其它原因造成的宕机时,可以使用副本进行恢复。
另一个是做读写分离,读的请求分流到副本上,减轻主(Primary)的读压力。
2.1.Primary和Secondary搭建的Replica Set
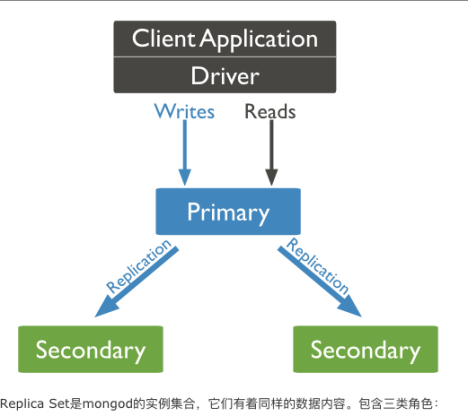
2.1.1.主节点(Primary)
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
2.1.2.副本节点(Secondary)
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
2.1.3.仲裁者(Arbiter)
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
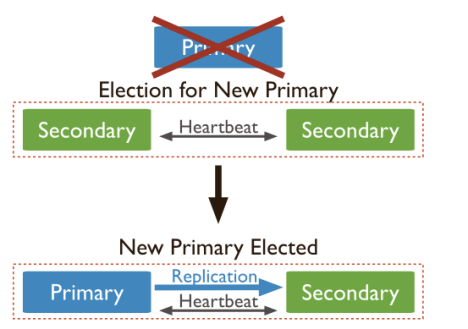
2.1.4.选主过程
其中Secondary宕机,不受影响,若Primary宕机,会进行重新选主:
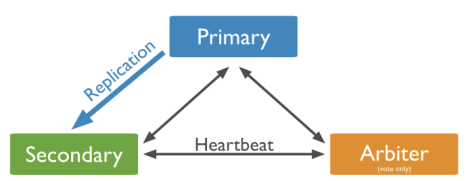
2.2.使用Arbiter搭建Replica Set
偶数个数据节点,加一个Arbiter构成的Replica Set方式
四.Sharding分片技术
当数据量比较大的时候,我们需要把数据分片运行在不同的机器中,以降低CPU、内存和IO的压力,Sharding就是数据库分片技术。
MongoDB分片技术类似MySQL的水平切分和垂直切分,数据库主要由两种方式做Sharding:垂直扩展和横向切分。
垂直扩展的方式就是进行集群扩展,添加更多的CPU,内存,磁盘空间等。
横向切分则是通过数据分片的方式,通过集群统一提供服务:
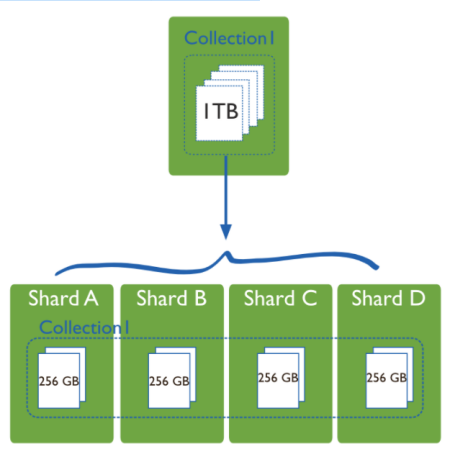
1.MongoDB的Sharding架构
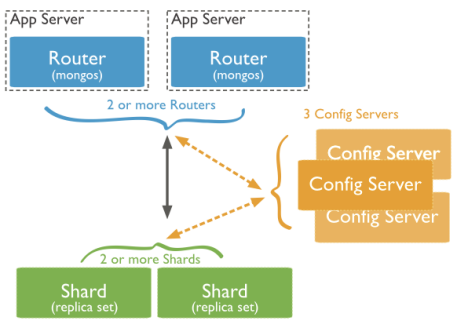
2.MongoDB分片架构中的角色
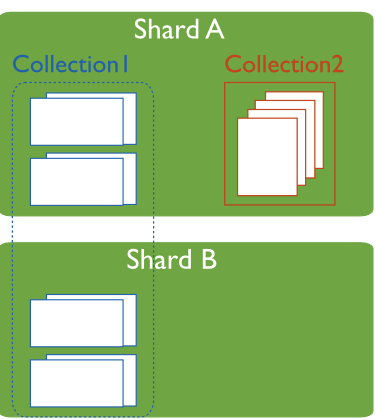
2.1.数据分片(Shards)
用来保存数据,保证数据的高可用性和一致性。可以是一个单独的mongod实例,也可以是一个副本集。
在生产环境下Shard一般是一个Replica Set,以防止该数据片的单点故障。所有Shard中有一个PrimaryShard,里面包含未进行划分的数据集合:
shards将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。
2.2.查询路由(Query Routers)
路由就是mongos的实例,客户端直接连接mongos,由mongos把读写请求路由到指定的Shard上去。
一个Sharding集群,可以有一个mongos,也可以有多mongos以减轻客户端请求的压力。
2.3.配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则。
mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,防止数据丢失!
Mongodb集群调研的更多相关文章
- Mongodb集群配置(sharding with replica set)
转自:http://blog.csdn.net/zhangzhaokun/article/details/6269514 前言 最近在研习MongoDB集群,找到一个不错的例子,加了几句,按照自己的理 ...
- MongoDB集群卡死问题
一年前搭了个MongoDB集群,跑得还算不错,但是有几次遇到过服务卡死的问题.处理起来已经得心应手了,拿来跟大家分享一下: 故障现象: 业务查询缓慢,而且会有连接异常: { "serverU ...
- mongodb集群安装及到现在遇到的一些问题
集群搭建 只有3台服务器,开始搭建mongodb集群里主要参照的是http://www.lanceyan.com/tech/arch/mongodb_shard1.html,端口的设置也是mongos ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- [转]搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- [转]搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
- 搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
- 搭建高可用mongodb集群(三)—— 深入副本集内部机制
在上一篇文章<搭建高可用mongodb集群(二)—— 副本集> 介绍了副本集的配置,这篇文章深入研究一下副本集的内部机制.还是带着副本集的问题来看吧! 副本集故障转移,主节点是如何选举的? ...
- 搭建高可用mongodb集群(二)—— 副本集
在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB> 提到了几个问题还没有解决. 主节点挂了能否自动切换连接?目前需要手工切换. 主节点的读写压力过大如何解决? 从节点 ...
随机推荐
- 菜鸡的Java笔记 第三十三 - java 泛型
泛型 GenericParadigm 1.泛型的产生动机 2.泛型的使用以及通配符 3.泛型方法的使用 JDK1.5 后的三大主 ...
- MySQL 1064 错误
ERROR 1064 : You have an error in your SQL syntax; check the manual that corresponds to your MySQL s ...
- [luogu5464]缩小社交圈
不难证明合法当且仅当满足一下两个条件: 1.每一个位置最多被覆盖两次(无环) 2.将选择的区间按左端点从小到大排序,对于每一个左端点,其之前的区间的最大右端点不小于其(连通) (关于第一个的充分性证明 ...
- 析构函数与this指针
二.析构函数 1.知识点介绍 析构函数和构造函数一样,也是一种特殊的函数,主要的作用是在对象结束生命周期时,系统自动调用析构函数,来做一些清理工作,比如在对象中有申请内存,那么是需要自己去释放内存的, ...
- 详解Python Streamlit框架,用于构建精美数据可视化web app,练习做个垃圾分类app
今天详解一个 Python 库 Streamlit,它可以为机器学习和数据分析构建 web app.它的优势是入门容易.纯 Python 编码.开发效率高.UI精美. 上图是用 Streamlit 构 ...
- Codeforces 1303G - Sum of Prefix Sums(李超线段树+点分治)
Codeforces 题面传送门 & 洛谷题面传送门 个人感觉这题称不上毒瘤. 首先看到选一条路径之类的字眼可以轻松想到点分治,也就是我们每次取原树的重心 \(r\) 并将路径分为经过重心和不 ...
- R之dplyr::select/mutate函数扩展
select函数 dplyr包select函数用的很多,不过我们一般也是通过正反选列名或数字来选择列. 常见用法如: select(iris,c(1,3)) select(iris,1,3) #同上 ...
- Oracle、MySQL关机操作步骤
一.Oracle数据库单机关机(eg:LEAP系统) 先关闭使用数据库的应用系统,再关闭数据库 关闭数据库执行以下命令 1.关闭Oracle数据库监听器:(使用操作系统下管理Oracle的账户,关闭监 ...
- dlang 安装
刷论坛看到TIOBE排行榜,排名靠前的基本是C.C++.java.python之类的语言,常用的R语言近几年排名一路走高,前20基本变化不大. 后面发现第二十九位居然有个叫做D的语言,看了下和C语法很 ...
- 生成随机数的N种方式
首先需要说明的是,计算机中生成的随机数严格来说都是伪随机,即非真正的随机数,真正随机数的随机样本不可重现.那么我们来看看代码中有哪些方式可以生成随机数. rand rand函数声明如下: #inclu ...